gRPC REST translation: where it helps and where it hurts
Learn when gRPC REST translation makes sense, where gateways add risk, and how to keep error formats and status codes from drifting.
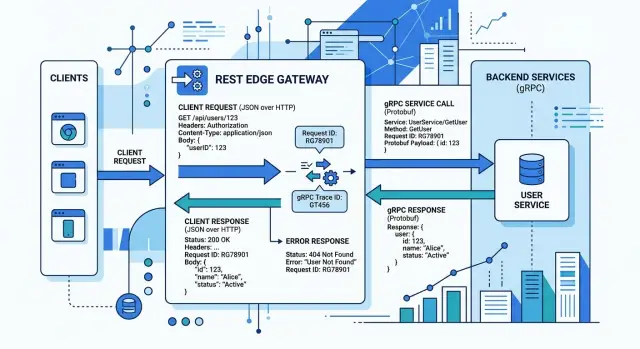
Table of Contents
Why teams mix gRPC and REST
Most teams do not choose gRPC or REST in a vacuum. They deal with two different audiences. Inside the system, developers want speed, strict contracts, and fewer surprises. At the edge, browsers, mobile apps, partners, and simple scripts usually expect JSON over plain HTTP.
That split makes sense. Internal services often prefer gRPC because the contract is typed, client code can be generated, and requests stay consistent across teams. You get less guessing about field names, data types, and request shapes.
Public clients live in a different world. A browser does not speak gRPC the same way a backend service does. Many outside clients also expect familiar REST behavior: simple endpoints, HTTP status codes, and JSON bodies they can inspect without special tooling.
So teams put a translation layer in the middle. The edge accepts REST calls, then maps them to gRPC methods behind the scenes. That can be an API gateway, a proxy, or custom backend code. This is why gRPC REST translation keeps showing up in real products.
Done well, this split is practical. A small company can keep a clean internal service contract while giving customers an API they can use right away. The internal team gets strong typing. Outside users get something familiar.
Trouble starts when the edge does more than translate format. If the layer changes names, hides fields, rewrites errors, or turns one backend action into a different public meaning, the system starts to drift. Then the REST edge API stops being a thin adapter and becomes a second product you have to maintain.
That is where teams get burned. One service returns a clear gRPC error, but the edge turns it into a generic 500. A missing field becomes an empty string because the mapper picked a default. A timeout in one place looks like a validation problem in another. Clients lose trust fast when the same failure looks different depending on which path they hit.
Mixing gRPC and REST is normal. Letting the translation layer invent its own behavior is the part that causes long-term pain.
What the translation layer actually does
Most people treat the edge as a format converter. It does more than that. In gRPC REST translation, this layer takes an HTTP request, matches it to a route, and turns it into a specific gRPC method call with the right request message.
A route like POST /v1/orders/123/cancel?reason=duplicate may become OrderService.CancelOrder. The path value 123, the query value duplicate, the JSON body, and headers such as Authorization or X-Request-Id all need a clear home in the gRPC request or metadata. Whether you use API gateway mapping or a small custom proxy, the job stays the same.
The layer also handles edge chores that do not belong inside business logic. It can verify auth, apply rate limits, attach request IDs, and write logs before the call reaches the service. That helps because every backend method should not repeat the same HTTP work.
Error conversion is where many teams get sloppy. A gRPC service may return NOT_FOUND, INVALID_ARGUMENT, or FAILED_PRECONDITION with structured details about fields, limits, or retry hints. The REST edge API has to turn that into an HTTP status and one stable JSON error shape.
If one endpoint returns 404 with code and message, while another returns 400 with a plain string, clients start adding special cases. That is how drift begins. The backend still behaves one way, but the edge tells a different story.
A healthy translation layer keeps two promises. First, it does not invent domain rules. If a customer cannot cancel a paid invoice, the service should decide that. Second, it preserves intent. If the backend says a field is invalid, the client should receive that same meaning after status code mapping, not a vague bad request.
That is why this layer looks small on paper but touches almost every request. If it stays thin and consistent, teams get the benefit of gRPC inside and a simple HTTP surface outside without a pile of one-off behavior.
Where translation layers help
A translation layer helps when your public API has one job and your internal services have another. Web apps, mobile apps, partner integrations, and simple scripts usually want plain HTTP and JSON. Your backend team may still prefer gRPC because protobuf is strict, fast, and easier to keep consistent inside the system.
That split is often practical. gRPC REST translation lets client teams use familiar request and response shapes without forcing them to deal with protobuf files, generated clients, or HTTP/2 details. For many products, that lowers friction right away.
It also gives you a clean boundary around your internals. Public clients do not need to know that an endpoint reaches UserService, BillingService, or three smaller services behind the gateway. They do not need to know port numbers, service discovery rules, or how calls move across your network. You can rename, split, or move internal services later and keep the edge API stable.
That matters most when teams move at different speeds. Backend engineers can keep protobuf contracts between services and evolve them for internal use. Frontend and mobile teams can keep working with a REST edge API that changes less often. Both sides get an interface that fits the way they work.
A gateway is also a good place to apply shared rules once instead of repeating them in every service. Common examples include:
- checking auth tokens before requests reach private services
- applying rate limits for public traffic
- adding request IDs for tracing
- blocking or shaping traffic during spikes
This is where API gateway mapping pays off. One layer can translate paths, methods, headers, and payloads in a consistent way.
A simple case makes it clear. A mobile app sends POST /orders with JSON. The gateway verifies the user, adds internal metadata, and maps that request to CreateOrder on a gRPC service. If the backend later splits ordering into two services, the app may not need any change at all.
Used this way, the translation layer acts like a buffer. It keeps the public side simple and gives the backend room to change without turning every internal refactor into a client update.
Where translation layers hurt
A translation layer gives you one more moving part between the client and the service. That sounds small on a diagram. In practice, it becomes one more place where your API can drift.
A gRPC method has a clear contract in protobuf. The REST edge API often has a JSON shape, status code rules, field names, and error messages of its own. If the team updates one side and forgets the other, clients get odd behavior. A field might exist in gRPC but never appear in JSON. A required value might become optional at the gateway. Even tiny naming changes, like user_id turning into userId, can create bugs that nobody sees until a mobile app breaks.
Latency also gets worse, even when each step looks fast by itself. The gateway has to accept HTTP, parse JSON, map it to protobuf, send the gRPC call, receive the response, convert it back to JSON, and write the final status code. Each step adds work. One request may only pick up a few extra milliseconds, but under load those small costs stack up.
Errors are where things usually fall apart first. gRPC can return structured details, such as which field failed validation or whether the caller hit a rate limit. A shallow JSON wrapper often reduces that to something like {"error":"bad request"} with a plain 400 status. The client loses detail, support loses context, and developers start guessing.
That loss hurts debugging too. If logs stop at the gateway, your team sees the REST request and the final failure, but not the full path in between. They may not know whether the bug lives in the client payload, the mapping rule, the backend service, or the status code translation. A simple validation error can take an hour because the gateway hid the original gRPC status and request metadata.
A common example is a signup form. The backend returns INVALID_ARGUMENT with field-level details for email and password. The gateway maps it to a generic 400 with one message string. The web app can no longer point to the exact fields, and the support team only sees "signup failed" in logs.
That is the main cost of gRPC REST translation: more compatibility at the edge, but more chances for drift, slower requests, thinner errors, and harder incident work.
A simple example
A mobile app talks to a REST edge API because phones, browsers, and third-party clients usually work better with plain HTTP and JSON. The app sends POST /orders to place an order and POST /payments to charge a card. Behind the edge gateway, those two routes call different gRPC services.
/orders goes to OrdersService.CreateOrder. /payments goes to PaymentsService.Charge. On a normal day, the split feels clean. The client gets REST, the backend gets fast service-to-service calls, and the gRPC REST translation layer stays out of the way.
Trouble starts when both paths hit the same kind of problem but report it differently.
Imagine the payment provider slows down. The orders route waits on the payments service through the gateway, hits its timeout, and the gateway returns a 504 Gateway Timeout. The body looks like this:
{
"error": "gateway_timeout",
"message": "upstream service did not respond in time"
}
Now the mobile app calls /payments directly a few seconds later. That request reaches the payments gRPC service, which catches the same slow provider call, wraps it as an internal server error, and sends it back through a different mapping rule. The client gets a 500 with a different body:
{
"code": "internal_error",
"details": "payment processor timeout"
}
Support now sees two tickets for the same outage. One customer says the app showed a timeout. Another says the server failed. The team searches logs for two error names, two status codes, and two body shapes. The bug is not harder than before, but the cleanup is.
That is where translation layers hurt. They can hide backend details, but they can also create new differences by route. If one timeout becomes 504 and another becomes 500, people stop trusting the API. Clients start adding route-specific fixes, and drift spreads fast.
A better setup gives the public API one error shape and one mapping rule for timeouts, no matter which gRPC service failed.
How to keep one error contract
Clients do not care whether a failure started in gRPC or at the REST edge API. They care that the error looks the same every time. If one path returns INVALID_ARGUMENT and another returns a vague 400 with a different body, support gets harder and client code turns messy fast.
Start with a small set of error codes that people can trust. Keep them stable. Most teams only need a handful, such as validation_error, not_found, auth_required, permission_denied, rate_limited, conflict, internal_error, and service_unavailable. That is enough for clear client behavior without leaking backend trivia.
Map gRPC statuses to HTTP statuses on purpose, not by accident. Pick one HTTP status for each gRPC status and write it down once. A common mapping looks like this:
INVALID_ARGUMENT->400UNAUTHENTICATED->401PERMISSION_DENIED->403NOT_FOUND->404RESOURCE_EXHAUSTED->429INTERNAL->500UNAVAILABLE->503DEADLINE_EXCEEDED->504
The body should stay steady too. Return the same fields every time, even when the backend fails in a new way. Four fields cover most cases well: code, message, request_id, and details.
{
"code": "validation_error",
"message": "email is invalid",
"request_id": "req_9f2c1",
"details": {
"field": "email"
}
}
That request_id saves real time in production. A customer can send one string to support, and your team can find the matching logs in seconds.
Do not hand-write the same mapping in three places. That is how drift starts. Keep one source of truth, then generate the gateway mapping, shared constants, and docs from it. For many teams, that source is a protobuf enum plus a small mapping table checked into the same repo as the service.
CI should hit the same failure through both paths. Send one bad request over gRPC, send the equivalent REST request through the gateway, and compare the result. The transport can differ. The contract should not. Check the app code, the HTTP status, and the response fields in the same test.
If a client team can handle errors with one simple switch statement, your contract is in good shape. If they need transport-specific exceptions, the contract already drifted.
Common mistakes that cause drift
Drift starts small. One team adds a new error name, another route returns a different JSON shape, and a gateway maps the same backend failure to two HTTP statuses. A month later, clients stop trusting the API because the same problem looks different depending on which path they hit.
The most common cause is local decision-making. Each service team tries to make errors "clearer" for its own endpoint, but the system gets harder to use as a whole. In gRPC REST translation, that usually shows up in four places:
- Services invent their own error codes and names for the same failure
- Some routes pass through raw gRPC messages, while others wrap them in custom JSON
- Teams remap HTTP status codes without testing what web or mobile clients already do
- Docs change by hand after behavior changed in code
The first problem spreads fast. One service returns USER_NOT_FOUND, another returns ACCOUNT_MISSING, and a third says 404_entity_absent. All three mean the same thing. Clients now need special cases, and support teams need a cheat sheet just to read logs.
Mixed error shapes are just as bad. If one REST edge API route returns { "error": "timeout" } and another exposes raw gRPC text, clients cannot parse failures in a stable way. They end up matching strings, and string matching always breaks. Keep the public shape fixed, even when backend services change.
HTTP status drift causes quiet damage. A team might change a timeout from 503 to 500 because it "looks more correct." The code may still compile, but client behavior changes. A mobile app may retry on 503 and stop retrying on 500. That turns a temporary backend issue into a user-facing failure.
Docs drift faster than code
Hand-edited docs almost always fall behind. Someone updates the gateway mapping, forgets the docs, and now the docs promise one thing while production does another. That gap wastes time in QA, support, and frontend work.
A better rule is simple: generate as much of the contract as you can from the source of truth. If your protobuf, gateway config, and published error schema do not come from the same place, drift is not a risk. It is the default.
Teams that run lean infrastructure learn this quickly. Oleg Sotnikov often pushes companies toward one contract with one mapping table and one test suite around it. That is less glamorous than adding new gateway rules, but it saves a lot of rework.
If clients need a stable API, treat error shape, status mapping, and docs as one unit. Change them together, or do not change them at all.
Quick checks before launch
Before you ship gRPC REST translation, test the failures people hit on day one, not the happy path you already know works. A create call that succeeds tells you very little. A bad token, a missing record, or a slow upstream call tells you whether the REST edge API feels consistent or confusing.
Compare the same failures on both sides
Pick four cases and run each one through gRPC and the REST edge API: auth failure, validation error, timeout, and not found. For each case, compare the HTTP status, gRPC status, internal error code, message text, and any field-level details. If the REST response says 404 but the service returns invalid argument, your API gateway mapping has already started to drift.
Keep the check simple and repeatable:
- Auth: expired token, missing token, wrong scope
- Validation: required field missing, bad format
- Timeout: upstream slow call, deadline exceeded
- Not found: wrong ID, deleted record
A short test table is enough. You want both interfaces to answer the same question in the same way: what failed, why it failed, and what the caller should do next.
Every error should include a request ID. Put it in headers and in the response body if your format allows it. When a client sends a screenshot or a log snippet, that ID lets your team trace the request across the gateway and the gRPC service fast.
Measure both layers
One latency number is not enough. Track gateway latency and service latency separately, or you will blame the wrong layer. The gateway can add 30 to 50 ms with auth checks, JSON mapping, and retries even when the backend is quick. The reverse happens too: the edge looks slow because the service is waiting on the database.
If you already use tools like Grafana, Prometheus, or Sentry, split dashboards by edge and backend. That makes regressions easy to spot after a release.
Do not launch until your team can answer three plain questions for any failed request: which layer rejected it, what error shape the client saw, and which request ID ties the whole path together.
What to do next
Do not translate your whole backend at once. Pick one endpoint that real users hit often, map it carefully, and watch how it behaves in production. A single route will show you most of the problems early: missing fields, odd status code mapping, and error messages that make sense to backend engineers but confuse client apps.
Keep the public REST edge API smaller than your internal gRPC API. Internal services can stay detailed and fast. Public endpoints should stay stable, boring, and easy to document. If your gRPC service has ten methods, you may only need three REST routes at the edge.
A good rollout usually looks like this:
- Choose one endpoint with clear inputs and a small response.
- Write down the REST request, REST response, and every error shape you will allow.
- Compare real client failures against your mapping, not just happy-path tests.
- Fix naming, status codes, and error bodies before you add more routes.
This is where many teams rush. They add five or ten mappings, then spend weeks cleaning up drift. It is cheaper to slow down early. If mobile clients see 404 for one missing record, 400 for the same case on another route, and a raw gRPC message on a third, trust drops fast.
Treat error review as part of the design, not cleanup work. Save samples from logs, support tickets, and client test runs. Then check them side by side. If two routes describe the same problem in different ways, merge them now. That discipline matters more than fancy gateway config.
If your team wants a second opinion, Oleg Sotnikov can help as a Fractional CTO with API design, infrastructure, and practical AI-first development workflows. That kind of outside review is often useful when gRPC REST translation starts small but is about to spread across the whole product.


