GraphQL resolvers at the edge without schema glue sprawl
Learn how to keep GraphQL resolvers at the edge, move business rules into services, and stop schema glue from turning into hidden app logic.
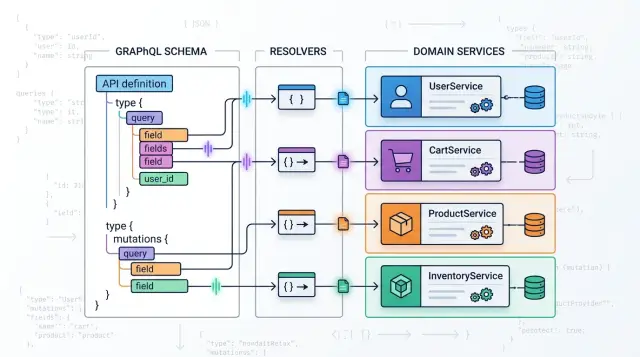
Table of Contents
Why schema glue becomes a problem
A GraphQL resolver often starts as a thin adapter. It reads args, calls a service, and returns data. Then someone adds a status check. Next week, a pricing rule. A month later, the resolver knows about trial plans, expired cards, feature flags, and which roles can bypass limits.
That is when the resolver stops being glue and turns into a mini controller. It still looks harmless because each change is small. The problem is cumulative. Logic spreads field by field, and before long, business behavior lives in schema code.
Duplication follows fast. One resolver checks whether a customer can upgrade. Another checks the same rule with one small difference. A third copies the old version and adds a special case for annual billing. Now the real rule is not in one place. It is scattered across files that were only meant to connect GraphQL to the app.
A small product change can then break behavior in odd places. Say the team changes upgrade rules so suspended accounts cannot switch plans until billing clears. If that rule lives in three resolvers and one mutation helper, one path will almost always be missed. The schema still compiles. Tests may still pass. Users find the bug first.
The deeper problem is that schema glue hides intent. When business rules sit inside argument parsing, response shaping, and null handling, developers can see conditions but not the policy behind them.
You can spot that confusion early. Developers read several resolvers just to find one rule. The same pricing check appears in slightly different forms. Refactors feel risky because nobody knows which field depends on what. New teammates guess where logic belongs, and they often guess wrong.
Teams usually learn this once the codebase grows a bit. The problem is not GraphQL. The problem is letting schema code become the place where business decisions quietly pile up.
What DDD-lite means in this setup
DDD-lite means taking the useful part of domain-driven design and leaving the ceremony behind. You do not need a maze of layers, factories, and abstract base classes. You need a clear home for business decisions, clear names, and a clean boundary between GraphQL code and application rules.
In practice, that means naming things after the business, not after the transport layer. A resolver should talk about subscriptions, teams, invoices, or seats. It should not become a dumping ground for argument parsing, permission rules, pricing checks, and side effects just because the schema made that easy.
The split is simple. Resolvers translate requests into an application call, then translate the result back into the schema shape. Services or small domain objects decide what is allowed, what changes, and what must happen together. If your pricing rule changes, you update the service. If your GraphQL field names change, you update the resolver. Those changes should not drag each other around.
That is the "lite" part. Keep the model small. If a rule is only a few lines, a plain service function is often enough. If one business concept has several related rules, give it a small domain object with methods that read like the business itself. Skip patterns that add files but not clarity.
A good test is simple: can someone read the resolver and understand the API flow in a few seconds? They should see input mapping, one application call, and output mapping. They should not need to scan conditionals to learn how billing works.
This is why the idea of keeping resolvers at the edge is so useful. The edge layer adapts data. The domain layer makes decisions. Draw that line once and keep it obvious. The code stays easier to change when either the schema or the business moves.
What belongs in a resolver
A resolver should do the smallest amount of work needed to turn a GraphQL request into an application call. In a DDD-lite setup, it stays close to the transport layer, not the business layer.
Its job starts with reading input. That usually means field arguments, request metadata, and the current user from context. A mutation like upgradeSubscription may read a planId plus the signed-in account, then pass both to one service or use case.
That service call should be the center of the resolver. One resolver, one clear application action. If a resolver starts checking plan prices, account state, trial limits, billing dates, and side effects, it is no longer an adapter. It is business logic mixed into schema glue.
After the service returns, the resolver can map the result into GraphQL types. That part is easy to underestimate. Domain objects often use names and shapes that make sense inside the app, while the schema uses names that make sense to clients. That translation belongs at the edge.
Error handling also belongs in the resolver, but only at the request boundary. If the request has no user, if input is malformed, or if the service returns a known domain error, the resolver should turn that into a predictable GraphQL response. Teams create a mess when one resolver throws raw errors, another returns null, and a third invents a custom payload.
What stays out matters just as much. Leave pricing rules, state changes, workflow decisions, permission policy details, and write ordering inside services. If a customer can upgrade only once per billing cycle, the service decides that. If an upgrade should create an invoice, adjust limits, and log an event, the service owns that flow.
A useful test is this: if you removed GraphQL tomorrow and called the same use case from REST, a background job, or a CLI command, would the business behavior still work? If the answer is yes, the split is healthy. Thin GraphQL resolvers read the request, call one application action, and map the result back out.
A simple example with a subscription upgrade
Imagine a mutation called upgradeSubscription. A customer moves from Basic to Pro in the middle of the month. The request looks simple, but the rules rarely are. You may need to check whether the user is logged in, whether the account can upgrade during a trial, how to handle proration, and whether the plan is even available for that customer.
A fat resolver tries to do all of that in one place. It reads auth, validates input, fetches billing data, compares plans, calculates charges, writes updates, catches payment errors, and shapes the response. That works for a week or two. Then the resolver turns into schema glue with business rules buried inside it.
With resolvers kept at the edge, the resolver stays small. It should read auth, map GraphQL input to a service request, and call one service.
mutation {
upgradeSubscription(input: { accountId: "a1", targetPlan: PRO }) {
ok
code
message
}
}
The thin resolver might pass a request like this to subscriptionService.upgrade():
actorIdfrom the sessionaccountIdfrom the mutation inputtargetPlanfrom the schema enum
The service owns the rules. It decides whether the account is still in trial, whether proration applies today, whether the customer can move straight to Pro, and what to do if payment fails. That logic belongs together because those rules change together.
The service should return a plain result object, not GraphQL-shaped logic. For example, it can return ok: true with the updated subscription summary, or ok: false with a code like PLAN_NOT_ALLOWED or PAYMENT_FAILED. The resolver maps that result to the schema response and stops there.
Compare that with the fat version it replaced. In the old resolver, a billing rule change meant editing resolver code, test mocks, and sometimes other mutations that copied the same checks. In the thin version, you update one service and leave the schema layer alone.
That split is the whole point of DDD-lite GraphQL. The schema explains how clients talk to your app. The service decides what the business allows.
How to refactor a fat resolver step by step
Do not refactor every resolver at once. Pick one mutation that changes data and already causes pain: repeated bugs, hard reviews, or rules that nobody trusts. If you want thinner resolvers, start where the cost is obvious.
A good target is a resolver with too many decisions in it. You will usually see role checks, state checks, billing rules, direct database writes, event sending, and response shaping all mixed together. That mix is why small edits turn into risky edits.
The refactor works best as a short, boring pass. Read the resolver line by line and label each part. Parsing args, reading context, and returning schema types belong to the resolver. Rules like "this user can archive this project only if billing is active" do not.
Then create one named service method for the business action. Give it a plain name such as archiveProject or changePlan. DDD-lite does not need a giant domain model. It needs a clear home for rules.
Move one rule at a time into that service method. Start with the rule that breaks most often, such as state transitions or permission checks tied to business policy. Leave request parsing and final mapping in the resolver.
Before deleting the old code, add tests around the service. Cover at least one allowed case, one blocked case, and one side effect such as a saved record or queued event.
When you finish, the resolver should mostly read input, call the service, and map the result to the schema response.
This works better than a big rewrite because each move is small and easy to review. You can stop after any step and still ship safely.
A simple check helps at the end. If the resolver still decides prices, workflow steps, or account limits, it is still fat. If it mostly translates GraphQL input into a service call and translates the result back out, you are close.
Where validation, auth, and mapping should go
This split works best when resolvers handle edge concerns, then pass clean input to application code. Once a resolver starts checking plan rules, decoding IDs, enforcing roles, and shaping every error by hand, it turns into a second service layer.
Validate request shape at the API boundary. Missing fields, bad enum values, malformed IDs, and empty strings should fail before the domain sees them. Your service should receive simple, trusted values, not raw GraphQL input with nullable fields and transport-specific quirks.
Auth belongs close to the use case entry point, usually in the application service or command handler. The resolver can pass the current user, workspace, or session from context, but the service should decide whether that actor may upgrade a subscription or view billing data. That rule often matters outside GraphQL too, such as in a background job or an admin script.
Validation and auth are easy to mix up, but they answer different questions. "Is this ID valid?" is an edge concern. "May this user change this account?" is a business concern. Keep them apart and both layers stay readable.
A simple request flow is usually enough:
- The resolver reads args and context.
- Edge code parses IDs, enums, and required fields.
- The service checks permissions and business rules.
- A mapper shapes the response for GraphQL.
- One translator turns domain failures into GraphQL errors.
That last step matters more than teams expect. If one resolver turns PlanLocked into a clear client error and another turns it into a generic server error, the API feels random. Put that translation in one place. Then your domain can return plain errors, and the GraphQL layer can map them to stable codes and messages.
Output mapping should stay boring and consistent. If your domain model uses money objects, internal statuses, or database IDs, map them once in the same way every time. Do not scatter formatting decisions across resolvers.
Mistakes teams make when they try this split
Teams often pull logic out of resolvers and feel done too early. The resolver gets thinner, but the mess just moves somewhere else.
A common version is the giant helper file. One month later, graphqlHelpers.ts holds price rules, access checks, date formatting, and half a dozen database calls. That is still schema glue, just with a different name.
Another mistake is building one service that does everything for one request. A method like upgradePlan() starts with SQL, checks permissions, applies billing rules, maps output for GraphQL, and formats labels for the UI. That service is hard to test because it mixes storage, policy, domain decisions, and presentation in one place.
Sharing a single service method across unrelated workflows causes trouble too. An upgrade flow, an admin correction, and a promo campaign may all change the same subscription, but they do not follow the same rules. If one method tries to cover all of them, exceptions pile up fast. You end up with flags like isAdmin or skipEmail, and the code stops telling a clear story.
GraphQL types leaking into domain code is another quiet problem. When domain services accept GraphQLResolveInfo, return schema-specific objects, or know field names from the API, your domain stops being portable. Then every schema change ripples through code that should not care.
The most expensive mistake is refactoring names without tests first. Renaming planService to subscriptionDomainService changes nothing if nobody checked behavior. A fat resolver moved into a fancy folder is still a fat resolver.
A few warning signs show up early:
- Services import GraphQL packages.
- One method has database queries and response shaping together.
- Unrelated actions call the same method with many boolean flags.
- The rename was larger than the test diff.
This separation matters even more on teams that use AI heavily in development. Review agents, code generation, and automated tests all work better when each layer has one job. Keep resolvers thin, keep business rules in services, and keep each service focused on one workflow people can describe in a sentence.
Quick checks for every resolver
A resolver should be boring. If it starts making pricing calls, checking upgrade limits, and rewriting data for three different cases, it is doing too much.
The resolver should read input, pass it to the right service, and shape the response. The business rule should live somewhere else, in code you can call from tests, jobs, or another API.
A short checklist helps during review:
- If it does not fit on one screen, it probably needs help.
- If two files can decide the same business rule, move that rule into one service.
- If you cannot test the rule without starting GraphQL, the logic is in the wrong place.
- If a REST endpoint or background job would need the same behavior, both should call the same method.
- If a new teammate cannot point to the file where the real rule lives, the split is still muddy.
A small subscription upgrade flow makes this easy to spot. The resolver can read the user ID, plan ID, and session. Then it calls something like upgradeSubscription(...) and returns the result in GraphQL shape. Trial limits, proration, blocked downgrades, and account state checks should stay in the service. That is the code you want to unit test hard.
When one of those checks fails, fix the structure before you add more code. A fat resolver almost never gets slimmer on its own. Teams keep patching it because the next change feels small, then six months later nobody wants to touch it.
This split also makes reuse obvious. If you later add an admin panel action, a REST route, or a queue worker, they should all call the same business method. Then another developer can open the codebase and see the rule in one place instead of hunting through schema glue.
Next steps for a cleaner GraphQL codebase
Most teams should not try to fix every resolver in one pass. Start with one mutation that already feels messy. Write down its boundary in plain language: what comes from the schema, what the domain service decides, and what goes back to the client.
That small exercise usually exposes the real problem. A resolver often began as simple schema glue, then picked up pricing rules, permission checks, status changes, and side effects. Once you name those parts, it gets easier to move them.
A simple team rule helps more than a big refactor. Keep the resolver limited to a few jobs: read args and context, validate request shape, pass a clear command to an application service, and map the result to the GraphQL shape.
If business decisions show up in the resolver, stop and move them down a layer. A good test is this: if the same rule would still matter in a CLI command, a job worker, or a REST endpoint, it does not belong in the resolver.
You also need a review habit. When someone adds a new field or mutation, ask where the rule lives. If the answer is "inside the resolver for now," that is usually a warning sign. Teams save a lot of cleanup time by catching that early instead of after five similar resolvers copy the same logic.
Code review is a good place to teach the pattern with very short examples. One small before-and-after diff is enough. Show a resolver that checks three business conditions, then show the same resolver calling subscriptionService.upgrade(...) and mapping the result. People learn faster from that than from a long document.
After a few passes, the codebase settles down. New schema changes feel safer because the rules have one home.
If your team is untangling API and domain boundaries, Oleg Sotnikov at oleg.is works as a Fractional CTO and startup advisor on exactly this kind of cleanup. A practical outside review can help you decide which resolver to fix first and where the service boundaries should actually sit.
Frequently Asked Questions
How do I know a resolver is getting too fat?
Look for decision-making in the resolver. If it checks pricing, account state, trial limits, billing dates, or side effects before it calls a service, it has grown past adapter work. Another sign is reuse pain: a rule shows up in two or three resolvers with small differences.
What should stay inside a GraphQL resolver?
Keep the resolver close to the request boundary. It should read args and context, reject malformed input, call one application action, and map the result to the GraphQL shape. Once it starts deciding what the business allows, move that logic out.
Where should business rules live instead of schema code?
Put those rules in an application service or a small domain object. That code should answer questions like who may upgrade, when proration applies, or which state changes may happen together. Then GraphQL stays thin, and other entry points can call the same rule.
Should auth checks live in the resolver or the service?
Let the resolver pass the current actor from context, then let the service decide access. The resolver can check whether a user exists at all, but the service should decide whether that user may change a subscription, archive a project, or view billing data.
Where should I handle input validation?
Validate request shape at the edge. Bad IDs, missing fields, empty strings, and wrong enum values should fail before the domain sees them. That keeps service code focused on business decisions instead of transport quirks.
How do I refactor a messy resolver without breaking things?
Start with one mutation that already hurts. Move one rule at a time into a named service method, keep request parsing and response mapping in the resolver, and add tests around the service before you delete old code. Small moves make review and rollback much easier.
Can the same business logic work for REST endpoints and background jobs?
Yes, and that is a good test for the split. If REST, a CLI command, or a job worker needs the same behavior, they should call the same service method. If the rule only works when GraphQL runs, the resolver still owns too much.
What mistakes do teams make when they move logic out of resolvers?
Teams often move the mess into a helper file and call it progress. Another common miss is one giant service that mixes SQL, policy, business rules, and GraphQL response shaping. Watch for boolean flags like isAdmin or skipEmail; they usually mean one method covers too many workflows.
How should I return domain errors to GraphQL clients?
Keep domain errors plain inside the service, then map them once at the GraphQL boundary. For example, a service can return PLAN_NOT_ALLOWED or PAYMENT_FAILED, and the resolver layer can turn that into stable client-facing codes and messages. That keeps the API predictable.
When should I ask for outside help with GraphQL and service boundaries?
Bring in outside help when your team keeps patching the same resolvers, reviews drag on, or nobody agrees where rules belong. A short architecture review can show which mutation to clean up first and where service boundaries should sit. If you want that kind of practical help, Oleg Sotnikov offers Fractional CTO and startup advisory work in this area.


