Go webhook libraries for signatures, retries, and logs
Go webhook libraries help teams verify payload signatures, track delivery attempts, and replay failures with less custom code and fewer blind spots.
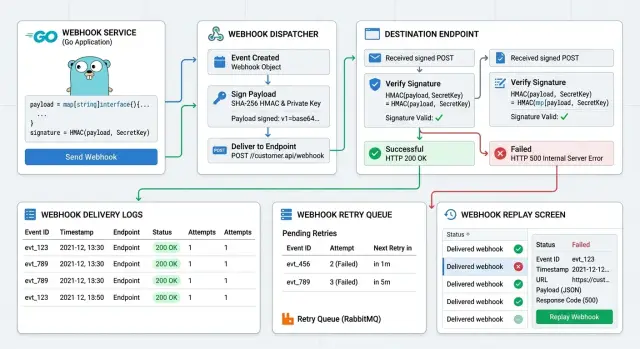
Table of Contents
Why webhook handling gets messy fast
Webhooks look simple on paper. A service sends an HTTP request, your app reads it, and work starts. The mess begins when real traffic shows up and the same event lands twice, or arrives late, or reaches one service but not the next.
Duplicate delivery is common, not rare. A sender may retry because your server answered too slowly, your load balancer cut the connection, or a deploy restarted the app at the wrong second. If your code treats every delivery as brand new, one customer action can create two emails, two status changes, or two charges.
Bad signatures add another layer of trouble. The request can look completely normal at first glance: valid JSON, expected event name, familiar headers. But if you skip payload signature verification, you might accept a forged request or reject a real one after a tiny body change, such as whitespace, encoding, or middleware reading the body too early.
Timeouts make debugging worse because they hide the real failure. The sender only knows your endpoint did not answer in time. Your team may only see a vague error in one service, no log in another, and no clear record of which payload actually arrived. Without delivery attempt logging, people end up guessing.
Then custom fixes spread. One service stores retries in Redis, another writes failed events to Postgres, and a third just logs an error and hopes the sender retries again. Soon you do not have one webhook system. You have four partial ones, all with different rules.
That is why Go webhook libraries matter so much. They do not solve every edge case, but they cut down the glue code that usually grows around signature checks, retries, idempotency, and replay failed webhooks.
What your Go setup needs from day one
Most webhook bugs start with one bad choice: treating the HTTP handler as the whole system. A safer Go setup keeps the request path thin and saves enough detail to explain every failure later.
Read the raw request body first and keep those exact bytes. Many providers sign the original payload, so if your handler parses JSON too early, your signature check can fail even when the sender did everything right.
Run payload signature verification before you trust any field in the body. That means before parsing business data, before updating records, and before kicking off background work. Even the best Go webhook libraries cannot fix a flow that trusts unverified input.
After the signature passes, save the provider event ID and the result of each processing attempt. You want a simple trail that shows what happened, not a mystery you have to rebuild from logs.
A useful record usually includes:
- the raw payload and relevant headers
- the provider event ID
- when the attempt started and ended
- the final status and error message
Keep retries out of the request path. If a downstream service is slow or your database is under load, the sender still needs a fast response from your endpoint. Put retry work in a queue or worker so one temporary problem does not turn into a pile of duplicate deliveries.
Replay matters too. One failed event during a deploy should not force a code change, a manual curl command, or a guessed payload from memory. Save enough data to replay one event on demand, with the same body and headers, and mark that replay as a new attempt.
That baseline is boring on paper. In production, it saves hours.
Choose libraries for each job
Most teams get farther with a small set of focused tools than with one big webhook framework. Good Go webhook libraries are often just standard pieces that do one job well, then fit together cleanly.
For the HTTP endpoint, start with net/http if you want the least moving parts. Add chi when you need clean routing and middleware without much weight. Use gin only if your app already runs on it and the team likes its style. Webhooks do not need a heavy web layer.
For payload signature verification, the standard crypto/hmac package is usually enough. It keeps the logic obvious: read the raw body, build the expected digest, compare it in constant time, then decide whether to accept the event. If a provider ships a small helper package for its headers and timestamp rules, that can save time, but only if it does not hide too much.
Logging needs structure from day one. slog is a good default in modern Go. zerolog is a solid pick if your team wants speed and compact JSON logs. In both cases, log the same fields every time: provider, event ID, delivery ID, signature result, HTTP status, retry count, and processing time.
For storage, PostgreSQL is hard to beat. Use pgx if you want direct control and good performance. Use sqlc when you want typed queries and fewer hand-written data access bugs. Store the raw payload, headers you care about, current status, and each delivery attempt. That gives you delivery attempt logging and makes replay failed webhooks much easier.
Retries belong in a worker queue, not in the request handler. Asynq is easy to start with and works well for delayed retries. gocraft/work is also a steady choice if your team already uses Redis jobs.
A lean default stack looks like this:
chifor routingcrypto/hmacfor payload signature verificationslogfor JSON logs- PostgreSQL with
pgxorsqlc Asynqfor webhook retry handling
That setup covers the boring parts well, which is exactly what you want.
Verify signatures before you trust the payload
Many webhook bugs start with one small mistake: the app parses JSON first and verifies later. That flips the order. The sender signed the exact raw bytes, not your parsed struct. If you change whitespace, normalize fields, or rebuild the body, the check can fail even when the event is real.
In Go, read r.Body once into a byte slice and keep that slice unchanged for verification. Use the same raw body when you build the HMAC or other signature check. Only after the signature passes should you unmarshal JSON into a struct and hand it to business logic.
A safe flow looks like this:
- read the raw body as bytes
- find the matching secret from the request headers or endpoint config
- reject the request fast if the secret is missing or unknown
- check the timestamp window if the provider sends one
- compare the expected and received signatures with
subtle.ConstantTimeCompare
That timestamp check matters more than teams think. If a sender includes a signed timestamp, treat old requests as suspicious. A replayed payload with a valid signature can still cause damage if your app accepts it hours later. A short window, often a few minutes, cuts that risk without making normal delivery fail.
Use a constant-time comparison every time. A plain string comparison can leak tiny timing differences. In Go, subtle.ConstantTimeCompare is simple and removes the guesswork.
Rejecting unknown secrets fast also keeps your logs clean. If you host webhooks for several customers, do not loop through every stored secret until one matches. Look up the intended secret first. If it is not there, return an auth error and log one clear reason.
A small payment example makes this concrete. A provider posts an event during a deploy. Your handler receives the raw body, checks the timestamp, verifies the HMAC, and only then parses the JSON. If the deploy changed your event struct, verification still works because it depends on the raw bytes, not your current parser.
Log attempts so failures make sense
Even with solid Go webhook libraries, most webhook bugs turn into log-reading jobs. If an event fails at 2:13 a.m., your team needs one clean record that shows what arrived, what your handler did, and why the provider tried again.
Start with identifiers. Save the provider name, the provider event ID, and the delivery ID for each attempt. Those three fields answer different questions: which system sent it, which event it was, and which specific delivery reached your endpoint. When a provider retries the same event five times, the event ID stays the same while the delivery ID changes.
A small set of fields covers most of the pain:
- provider name
- event ID and delivery ID
- received time and handler duration
- response status code and error text
- retry count or attempt number
Timing matters more than many teams expect. If your handler usually returns in 80 ms but some attempts take 9 seconds, that points to a slow database call, a lock, or an outside API. Without request timing, every timeout looks random.
Store enough request data to replay one event without guessing. That usually means the raw payload, headers needed for validation, and the final processing result. You do not need to keep every detail forever, but you do need one reliable snapshot for a failed event. If a payment event broke during a deploy, you should be able to replay failed webhooks after the fix and confirm that the same input now succeeds.
Keep your logs and metrics tied together with the same IDs. When a metric shows a spike in 500 responses, you should be able to search one event ID and see each attempt in order, how many retries happened, and where the handler spent time. That makes delivery attempt logging useful instead of noisy.
Retry and replay without double work
A failed delivery should move into a queue, not disappear into app logs. Store the raw payload, event ID, source, attempt count, next retry time, and the last error. That gives you one place to manage webhook retry handling and one record your team can inspect later.
Retry timing matters. If you hit the same broken endpoint every 10 seconds, you create more noise and more load. Use backoff instead: wait a little after the first failure, then wait longer after each new one. A simple schedule like 1 minute, 5 minutes, 15 minutes, 1 hour, and 6 hours is often enough for small systems.
Set a hard stop. After a fixed number of attempts, mark the delivery as failed and leave it for review. Endless retries hide real problems, fill queues, and make delivery attempt logging harder to read.
Before a worker does anything with the payload, check whether that event already changed your system. Save a stable event ID in a table before side effects happen, or save it in the same transaction as the side effect if you can. If the worker sees the same ID again, it should log "already processed" and exit.
Even with good Go webhook libraries, teams still need a simple replay path. The replay action should use the exact stored payload and run through the same verification and idempotency checks as a normal delivery. That is how you replay failed webhooks without charging a customer twice or sending duplicate emails.
A replay command is only useful if it is boring and predictable:
- Requeue one event by ID
- Keep the full attempt history
- Record who started the replay
- Record the reason for the replay
- Support a dry run for testing logs
Teams that run lean ops usually like this model because it cuts custom glue. One worker reads from the queue, one table tracks processed events, and one replay command handles the rare cases when a human needs to step in.
A simple setup in Go step by step
Keep the first version boring. One HTTP endpoint and one event type give you a clean path to test signatures, logging, and retries before more webhook traffic shows up. Many teams break things by adding five providers, three event families, and custom rules on day one.
- Accept the request and read the raw body once. Keep the exact bytes and the headers together, because signature checks often fail if you re-encode JSON.
- Verify the signature and the event time before you parse anything useful. If the timestamp is too old or the signature fails, stop there and return the right status.
- Save a delivery attempt before your business logic runs. Store the provider, event ID, received time, selected headers, raw body, and a status like "received".
- Send the event to a worker or queue. Your HTTP handler should stay short: validate, save, enqueue, respond.
- When the worker finishes, mark the attempt as success. If it fails, store the error, schedule the next try, and keep the same event ID so replay failed webhooks does not create duplicate work.
Then split transport code from business logic. Your payment code should not care about header formats, and your signature code should not know how invoices change. That separation makes payload signature verification and webhook retry handling much easier to test.
Go webhook libraries help when you keep that contract small. Let one package handle request verification, let another run background jobs, and let your code decide what the event means. That is much easier to maintain than custom glue spread across handlers, cron jobs, and ad hoc scripts.
This setup also makes delivery attempt logging useful instead of noisy. If a deploy breaks a worker, you can see whether the provider sent the event, whether your app accepted it, and exactly when the retry should run next.
A real example: one payment event during a deploy
A customer pays at 14:03, right when your app restarts for a deploy. The payment provider sends a webhook, opens a connection, and waits. Your app is still coming back up, so the request hits a timeout.
Nothing looks dramatic from the customer side. They already paid. The messy part starts in your backend if you do not record the failed delivery clearly.
A good log entry gives you enough to trace the event without guessing. You want the provider's delivery ID, the event type, the response status, and a body hash. That body hash matters more than people think. It lets you confirm that the retry carries the same payload, even if it arrives a minute later on a different app instance.
A simple log for that first miss might look like this:
delivery_id=wh_8f31 event=payment.succeeded status=timeout body_hash=9d4c...
Two minutes later, your app is healthy again. The provider retries, or your own retry worker pulls the failed attempt from a queue and sends it back through the same handler. The event is real, the signature still checks out, and this time the request finishes.
Now idempotency does the quiet work that saves you from a bad day. Your handler checks whether it already processed delivery ID wh_8f31 or the payment intent behind it. If yes, it stops. If no, it writes the payment record once, sends one receipt email, and exits.
Without that check, one timeout can turn into duplicate work fast:
- two charge records in your database
- two receipt emails to the customer
- one support ticket asking why it happened
This is why teams should treat retries as normal traffic, not as edge cases. Oleg often pushes this approach in production systems: log every attempt, keep a replay path, and make each webhook safe to run more than once.
Mistakes that cause duplicate or missing work
Most webhook bugs start with one bad assumption: "the request reached us, so we can process it now." That shortcut causes double charges, skipped updates, and long cleanup work later.
A common mistake comes first. Teams parse JSON before they verify the signature. That sounds harmless, but signature checks usually depend on the exact raw request body. If your code reads the body, reshapes it, or marshals it again, you can no longer prove the sender signed those exact bytes. Read the raw payload first, verify it, and only then decode it.
Another problem shows up when teams keep only normal app logs. A stack trace or a line in stdout rarely tells the full story. You also need an event record with the webhook ID, delivery time, signature result, response code, retry count, and final status. Without that record, you cannot tell whether a provider never sent the event again, your worker dropped it, or your code processed it twice.
Retry logic also trips people up. If you retry inside the HTTP handler, you keep the sender waiting while your server does extra work. That often ends in a timeout, and the provider sends the same webhook again. A better pattern is simple: accept the request, store it, return fast, and let a worker handle retries in the background.
Time checks need care too. Many signature schemes include a timestamp to stop replay attacks. If your server clock drifts, or your allowed window is too tight, you reject real events. Keep your clock in sync and allow a small buffer for network delay.
The last mistake is replaying old events without idempotency. Replays should help you recover, not create new damage. Store an event ID or delivery ID, and make your business action safe to run once. If a payment webhook arrives three times, your system should still create one result, not three.
Quick checks before you ship
Go webhook libraries cut down a lot of plumbing, but they do not prove your setup is ready. Run a few ugly tests before release. Ten minutes here can save hours of guessing later.
Start with one real event in a non-production environment. Then make your team answer simple questions from logs alone. If one delivery fails, can someone find that attempt, the retry count, and the last error in under five minutes? If not, your delivery attempt logging is still too thin.
Use the same event to test the paths that usually break:
- Change one byte in the body and confirm payload signature verification fails fast, with a clear reason in logs.
- Send the exact same event twice and make sure your app does the work once, then records the duplicate.
- Force one handler error, check webhook retry handling, and confirm the next attempt keeps the same event ID.
- Replay a failed webhook from stored data or your admin tool without touching code or redeploying.
- Search by event ID and see the full delivery history in one place, not across three tools.
Teams often test the happy path only. The boring admin actions matter just as much. If an engineer on call cannot replay failed webhooks at 2 a.m. without editing code, you have a tool gap.
A small drill helps. Stop your worker for a minute, send one test event, bring it back, and watch the system recover. You want boring results: one stored event, several logged attempts, and one successful processing record. If you cannot prove that with logs and IDs, fix it before customers find the gap.
What to do next
Pick one webhook provider and map the whole path on one page. Show where your Go service receives the request, checks the signature, stores the raw body, logs the attempt, and sends failures to retry. That document will save more time than another helper package.
If you are comparing Go webhook libraries, keep the first version narrow. Start with one provider, one event type, and one flow that one engineer can debug without hunting through three services.
A sensible next sprint usually includes four small jobs:
- Verify the payload signature before your code parses JSON or touches business logic.
- Write one delivery log for every attempt with time, event ID, status, and error text.
- Put failed deliveries into a small retry queue and add a replay command.
- Review secrets, log retention, and replay rules with the team.
Keep the retry queue boring. A database table or Redis can do the job for a long time. If a deploy breaks one handler for 15 minutes, you want a single place to see what failed and replay only those events.
Write down your duplicate rule too. If the same event arrives three times, your service should check the event ID and do the work once. Teams often skip that rule because it feels obvious, then spend a week cleaning up duplicate orders or repeated emails.
When the setup starts to spread into custom glue, stop and clean it up. Oleg Sotnikov can help design a cleaner Go backend for webhook verification, retries, and tracing as a Fractional CTO or advisor. Keep the whole system simple enough that one engineer can trace a failed event from request to replay without guessing.


