Go validation and decoding libraries for safer handlers
Go validation and decoding libraries help reject bad input early, keep handlers short, and make Go request parsing easier to test and maintain.
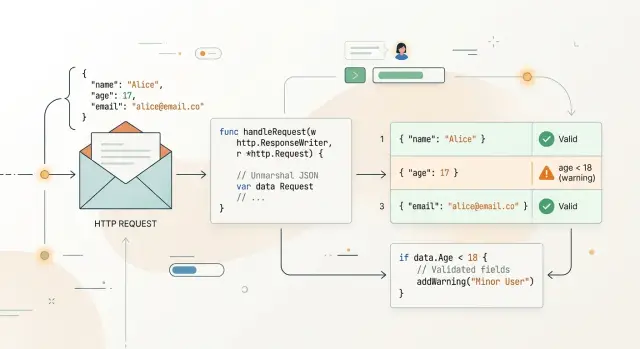
Table of Contents
Why bad input causes real bugs
Most handler bugs start before your business logic runs. A client sends "age": "ten" instead of a number, or leaves "email" blank, and the handler keeps going. The code might not fail right away, which makes the bug harder to trace.
JSON makes this worse because it still looks clean when it is wrong. A typo like "frist_name" can slip through if your decoder ignores unknown fields. The request looks valid, but the client never sent the field you expected.
That kind of mistake spreads fast. You save bad data, return the wrong error, or hit a failure three functions later. By then, nobody wants to debug the original request.
Empty required fields cause a different problem. The payload decodes into a Go struct just fine, but zero values leak into business logic. One missing email or ID turns a short handler into a pile of checks that every downstream function repeats.
Type mismatches are just as common. Query params and form values arrive as strings, yet handlers often expect ints, booleans, or dates. If conversion and validation sit next to database calls and service code, the handler grows for the wrong reason: it is doing too many jobs.
A signup endpoint shows the pattern. It expects an integer age, a non-empty email, and no extra fields. If the handler decodes loosely, "age":"18" may fail in one place, an empty email in another, and "emial" may not fail at all. Users get inconsistent errors, and the team gets messy code.
That is why Go validation and decoding libraries help so much. Strict JSON decoding in Go catches unknown fields early, and Go request validation keeps missing or malformed data out of the rest of the app. The result is simple: shorter handlers, clearer errors, and fewer bugs that hide for weeks.
Split decoding from validation
Go validation and decoding libraries make more sense when you treat decoding and validation as two separate jobs. Decoding takes raw input from the request and turns it into a Go struct. Validation checks whether the values in that struct meet your rules.
That split sounds small, but it changes the shape of a handler. A decoder answers questions like "Is this JSON valid?" and "Can I map these fields into this struct?" A validator answers different ones: "Is email empty?" "Is the password too short?" "Did the client send a value outside the allowed range?"
When you mix both steps into one block of code, handlers grow fast. You start with parsing, then add field checks, then custom error messages, and soon one endpoint has 40 lines of defensive code before it does any real work. Keeping the steps separate makes the handler read in a cleaner order: decode, validate, run business logic, write response.
Tests get easier too. You can test the decoder with broken JSON, wrong types, or missing query values. Then you can test validation with plain structs, without building full HTTP requests every time. That saves time, and the failure tells you exactly what went wrong.
A signup endpoint is a good example. If the body contains malformed JSON, the decoder should reject it before the validator runs. If the JSON is valid but the email is empty or the password has only five characters, validation should catch that next. Each step has one job.
Clear boundaries also make it easier to swap tools later. You might keep the same struct and business logic, but replace the body decoder or move from hand-written checks to a validator package. The handler stays short because each part does less. That is usually the difference between code that feels easy to trust and code that keeps surprising you.
JSON body decoders that fail fast
Most Go handlers do fine with the standard library. encoding/json plus json.Decoder is often enough, and it keeps one more package out of your project.
json.Decoder fits request handling better than json.Unmarshal because it reads straight from r.Body and lets you turn on stricter rules. That matters when you want bad input to fail early instead of slipping through and causing odd bugs later.
The first rule to enable is DisallowUnknownFields(). Without it, a client can send {"emali":"[email protected]"} and Go will quietly ignore the typo if your struct expects Email. Your handler may accept the request, but the user gets a broken result. Strict JSON decoding in Go avoids that kind of silent failure.
UseNumber() helps when numbers must stay exact. It matters most when you decode into map[string]any or other dynamic types. Without it, the decoder turns numbers into float64, which can mangle large IDs and other values you do not want rounded.
A small shared helper
One shared decode helper keeps every JSON endpoint on the same rules. It also keeps handlers short.
func decodeJSONBody(r *http.Request, dst any) error {
dec := json.NewDecoder(r.Body)
dec.DisallowUnknownFields()
dec.UseNumber()
if err := dec.Decode(dst); err != nil {
return err
}
if err := dec.Decode(&struct{}{}); err != io.EOF {
return errors.New("body must contain a single JSON value")
}
return nil
}
That second decode catches extra junk after the first JSON object, which is easy to miss.
A helper like this gives every handler the same behavior. It rejects unknown fields, keeps large numbers exact, rejects multiple JSON values in one body, and decodes into a typed struct instead of loose maps. When a team skips this step, every handler grows its own parsing rules. That is where inconsistent errors start.
Query and form decoders worth knowing
gorilla/schema is still a practical choice for query strings and form data. It turns url.Values into a struct, so your handler stops juggling Get(), Atoi(), and repeated if blocks. That keeps noisy parsing code in one place and makes the request shape easy to review.
It also handles repeated params cleanly. If a request sends tag=go&tag=api&tag=backend, you can decode that straight into []string instead of splitting strings by hand. The same idea works for checkbox groups in forms, where one field can send several values.
type SearchInput struct {
Query string `schema:"q"`
Tags []string `schema:"tag"`
Page int `schema:"page"`
Limit int `schema:"limit"`
}
func readSearchInput(r *http.Request) (SearchInput, error) {
input := SearchInput{
Page: 1,
Limit: 20,
}
dec := schema.NewDecoder()
dec.IgnoreUnknownKeys(false)
if err := dec.Decode(&input, r.URL.Query()); err != nil {
return SearchInput{}, err
}
return input, nil
}
The default values matter. Put them in the struct setup code, not in scattered fallback logic later in the handler. When a reviewer opens the file, they should see Page: 1 and Limit: 20 right away.
For form posts, call r.ParseForm() and decode r.Form the same way. You get one pattern for both query and form input, which keeps your handlers consistent. Teams usually write fewer bugs when every request path follows the same shape: decode, validate, return field errors, then run business logic.
Use the same error format for body, query, and form input. If JSON errors return one shape and query errors return another, clients end up with extra conditionals for no good reason. A simple format is enough:
source:body,query, orformfield: the input namemessage: a plain-English problem
That means page=abc in the query string and an invalid email in a form can fail in a familiar way. The transport changes, but the contract stays the same. That small bit of consistency makes APIs easier to test and much less annoying to use.
Validation packages that fit different teams
Among Go validation and decoding libraries, two packages cover most day-to-day needs: go-playground/validator and ozzo-validation. Both help you reject bad input early, but they feel different when you read and maintain the code.
Use go-playground/validator when your team likes struct tags and your rules are mostly simple field checks. It keeps common rules close to the request struct, which makes small handlers easier to scan. A signup request with fields like email, password, and age can carry most of its checks right on the struct.
Use ozzo-validation when you want rules in Go code instead of tags. This style is easier to read when rules depend on other fields, change often, or need custom logic. Some teams prefer it because the validation reads like normal code, not a compact tag language.
If your request shapes stay fixed and your rules are familiar things like required, email, min, or max, go-playground/validator is usually a good fit. If your validation has branches, custom messages, or rules tied to business context, ozzo-validation is often easier to live with.
Keep basic field rules close to the request struct when you can. That usually means length, format, required fields, and allowed values stay near the input type. It saves time because a reader does not need to hunt through service code to learn why a request failed.
Validate right after decoding, before any service call or database work. If the request is missing an email or sends an invalid date, return the error there. Do not start a transaction, call another service, or build extra objects first. That habit keeps handlers short and cuts off a whole class of avoidable bugs.
A good rule of thumb is simple: put request-shape checks at the edge, then pass clean data deeper into the app. Your business code gets smaller, and the error path gets much easier to trust.
A simple handler flow
A handler gets easier to trust when it follows the same order every time. Most Go validation and decoding libraries fit into this pattern, and the pattern matters more than the package name.
Start by capping the request body before you read it. A small limit, such as 1 MB for a normal JSON form, blocks accidental huge payloads and cheap abuse. It also makes failures clear: the request is too large, so the handler stops early.
Then decode into a request struct that belongs to the endpoint. Do not decode straight into your domain model. A signup request might have password_confirm, raw strings, or optional fields that your business objects should never carry. Keeping transport data separate makes the next step much cleaner.
A good flow looks like this:
- Limit body size.
- Decode JSON, query, or form data into a request struct.
- Reject unknown fields and wrong types at decode time.
- Run validation and collect field-level errors.
- Call business logic only with clean, typed data.
The third step saves a lot of time later. If the client sends age: "twenty" or adds a field your API does not accept, fail right there. Strict JSON decoding in Go helps you catch those mistakes before they leak into logs, database calls, or weird nil checks deeper in the app.
Validation comes after decoding because it works best on typed data. Once the struct is filled, you can check things like required fields, email format, length limits, or allowed values. If two or three fields are wrong, return all field errors together. People fix forms faster when they see the full list in one response.
The common mistake is mixing these stages. A handler decodes a little, validates a little, then calls business code and hopes the rest gets caught there. That spreads rules across the codebase. Keep the handler strict at the edge, and pass only clean data inward. Your service code stays smaller, and bugs show up closer to the real cause.
Example: a signup endpoint
A signup handler is a good place to get strict. The request is small: email, password, and an optional referral code. That makes it easy to reject bad input early and keep the rest of the code clean.
A request type might look like this:
type signupRequest struct {
Email string `json:"email" validate:"required,email"`
Password string `json:"password" validate:"required,min=8"`
ReferralCode string `json:"referralCode" validate:"omitempty,alphanum"`
}
With strict JSON decoding in Go, the handler should fail on unknown fields before validation runs. If a client sends "pasword" instead of "password", that is not a minor typo. It means the server never received the field it needs. A decoder with DisallowUnknownFields() can stop the request right there and return a direct error.
That gives the client a useful response instead of a vague "invalid request":
{
"errors": {
"pasword": "unknown field"
}
}
If the JSON shape is valid, go-playground/validator can check the contents. A blank email should fail. A password with only five characters should fail. The referral code can stay optional, but if the client sends one, you can still check its format.
The response can stay simple and specific:
{
"errors": {
"email": "email is required",
"password": "password must be at least 8 characters"
}
}
After that, the handler has an easier job. It does not need to guess what is missing, patch up field names, or pass half-broken data deeper into the app. It can build a trusted input object and call the service layer with confidence.
That last step matters. The service should receive data that already passed decoding and validation. Then the service can focus on business rules, such as checking whether the email already exists or whether a referral code is still active, instead of cleaning up request mistakes from the network edge.
Mistakes that make handlers hard to trust
Handlers go wrong when they accept too much, do too much, and expose too much. The code may look short at first, but the bugs get expensive fast.
A common mistake is decoding request data straight into a database model. That ties external input to fields you never meant to expose. A user sends one extra JSON field, and now your handler can overwrite internal flags, status values, or timestamps that should stay under server control.
Using one struct for everything causes the same mess. The body, query params, and stored record have different jobs. If you reuse one struct across all three, you blur the line between "what the client may send" and "what the app may store." Small apps survive this for a while. Bigger apps usually regret it.
Accepting unknown fields to look flexible is another bad trade. It sounds friendly, but it hides client bugs. If the client sends "emial" instead of "email", strict JSON decoding in Go should reject it early. Silent acceptance turns a clear error into broken behavior later.
Trouble also starts when one block of code handles auth checks, parsing, validation, business rules, and database writes together. Then every failure looks the same, and every edit risks a new bug. Split the flow into steps: identify the user, decode input, validate it, run the action, then build the response. That makes tests smaller and handler code easier to read.
Error messages need care too. Raw decoder errors help developers during local testing, but they often leak field names, internal types, or parser details to clients. Return a clean message instead, such as invalid request body or email must be a valid address, and log the full error on the server.
Good Go validation and decoding libraries help, but they do not fix a messy design on their own. The safer pattern is simple:
- use a request struct for input only
- reject unknown fields
- validate after decoding
- map clean input to your domain or database model
- return small, clear client errors
That pattern adds a few lines. It removes a lot of doubt.
Quick checks before you ship
A good setup for Go validation and decoding libraries only works if every handler follows the same rules. If one endpoint uses strict JSON decoding and another quietly ignores junk fields, bugs slip in fast.
Start with the request shape. Give each endpoint its own request struct, even when two endpoints look similar. A signup request and a profile update request may share fields, but they do not mean the same thing, and they rarely age the same way.
Release checklist
Before you ship, check these points across the whole app:
- Each endpoint has one request struct with names and tags that match the API contract.
- All handlers call the same decode helper, and that helper rejects unknown JSON fields by default.
- The app creates one validator instance and reuses it, instead of building rules in every handler.
- Every handler returns errors in the same shape, with the same field names and status logic.
- Tests cover missing fields, wrong types, and extra fields that clients should not send.
That second point saves more time than people expect. If a client sends "emial" instead of "email", strict decoding should fail at once. Silent acceptance feels friendly at first, then turns into a support problem two weeks later.
One shared validator instance also keeps the code calmer. Custom rules, tag names, and translated messages stay in one place. Handlers stay short because they decode, validate, and pass clean data to the service layer.
Keep the error format boring and consistent. If one handler returns {"error":"bad request"} and another returns a list of field problems, clients need special-case code for no good reason. Pick one format and use it everywhere.
Tests do the final cleanup. For a signup endpoint, send an empty body, a string where an integer belongs, and one extra field that your struct does not allow. If all three cases fail in the same clean way, your handler is probably ready.
What to do next
Start with the handlers that receive the most traffic or carry the most risk. Signup, login, checkout, password reset, admin imports, and public webhooks usually deserve attention first. A bad decode path in one of those endpoints can waste support time for weeks.
Pick three or four handlers and read them line by line. If a handler mixes JSON parsing, defaults, validation, business rules, and error formatting in one block, clean that up before you add more endpoints. Small fixes there often remove copy-paste problems across the rest of the codebase.
After you compare Go validation and decoding libraries, stop shopping and choose one small stack your team will actually use. Teams get more benefit from consistent request handling than from chasing the "best" package.
A solid next pass looks like this:
- use one helper for JSON decoding and make it reject unknown fields
- use one decoder for query or form input instead of hand parsing
- validate request structs in one place, with the same tag rules everywhere
- return the same error shape for every bad request
- add table tests for both accepted and rejected input
Do that before you add another batch of endpoints. If every new handler follows the same pattern, reviews get faster and bugs get easier to spot. New engineers also ramp up faster because they do not need to guess how each endpoint handles bad input.
It can also help to get an outside review of your request pipeline. A fresh pair of eyes often spots weak points that a team stops noticing, like fields that silently drop on decode, error messages that change from route to route, or validation rules living in the wrong layer.
If your team wants that kind of review, Oleg at oleg.is does this work as part of fractional CTO advisory. For backend teams, a short architecture pass on request handling and API error design can save a lot of cleanup later.
The best outcome is boring code: short handlers, strict input rules, and errors that look the same every time.
Frequently Asked Questions
Why should I split decoding from validation?
Split them because they solve different problems. Decoding checks whether the request shape and types match your struct. Validation checks whether the decoded values make sense, like a blank email or a short password. When you keep those steps apart, handlers stay small and failures point to the real problem faster.
What does DisallowUnknownFields actually do?
It tells the JSON decoder to reject fields your struct does not define. That catches typos like emial right away instead of silently dropping them and causing odd behavior later.
Why use json.Decoder instead of json.Unmarshal in handlers?
json.Decoder reads straight from r.Body, so it fits HTTP handlers better. It also lets you turn on strict rules like DisallowUnknownFields() and UseNumber(), which help you fail early on bad input.
When do I need UseNumber()?
Use it when you decode into dynamic types like map[string]any and you need exact numbers. Without it, Go turns numbers into float64, which can hurt large IDs or values that should stay exact.
How should I handle query params and form data?
A shared decoder like gorilla/schema keeps query and form parsing out of your handler logic. You decode into a struct, set defaults in one place, and stop repeating Get(), Atoi(), and error checks in every route.
Should I decode requests straight into my database model?
No. Decode into a request struct that belongs to the endpoint. That keeps transport fields like password_confirm away from stored fields and stops clients from touching values they should never control.
What order should a safe handler follow?
Cap the body size first, then decode into a request struct, reject unknown fields and wrong types, run validation, and call business logic only after that. This order keeps request mistakes at the edge of the app.
What should my API error responses look like?
Keep one boring format everywhere. Return the input source, the field name, and a plain message the client can fix. Clients should not need one parser for JSON errors and another for query or form errors.
Which validation package should I choose?
Pick go-playground/validator if your team likes struct tags and mostly checks things like required fields, email format, and length. Pick ozzo-validation if you want rules in Go code because they change often or depend on other fields.
What should I test before I ship a handler?
Test the cases that break real handlers: malformed JSON, wrong types, missing required fields, extra fields, and oversized bodies. Also check that every route returns the same error shape, so clients get predictable failures.


