Go SQL libraries: raw SQL, builders, and mappers for teams
Go SQL libraries range from database/sql and pgx to Squirrel and sqlx. Compare speed, query clarity, and migration fit for growing teams.
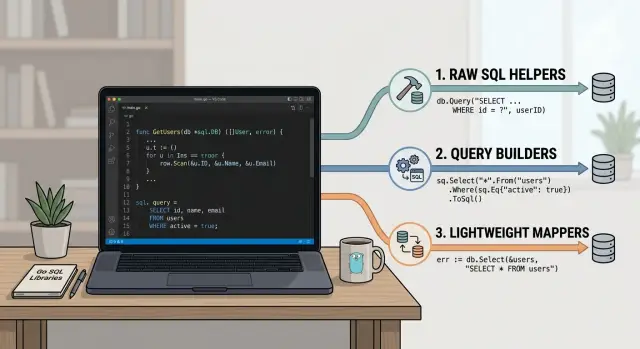
Table of Contents
Why teams look beyond full ORMs
Full ORMs feel fast at first. They hide a lot of database work behind model methods, tags, and conventions, and that looks tidy when a project is small. The trouble starts when a query slows down, a preload fetches too much data, or a join behaves in a way nobody expected. Then the team stops reading Go code and starts tracing generated SQL, driver behavior, and ORM rules.
That gap wears people down. A handler that looked simple fires three queries. A field that seemed optional starts failing because of NULL handling. A small schema change turns into a search across models, hooks, and custom mapping code. The database still does the same work, but the path from request to query gets harder to follow.
Many Go teams want the opposite. They want plain queries, clear inputs, and results that map to structs without drama. They want to open one file and see what hits the database. They want logs that match the code they wrote. When a query is slow, they want to tune that query directly instead of guessing what the ORM built behind the scenes.
Small product teams often learn this the hard way. They start with an ORM to move quickly. Six months later, they have custom scopes, eager-loading rules, model callbacks, and query patches spread across the codebase. Shipping slows down because every database change has side effects.
That is why many teams move from full ORMs to raw SQL helpers, builders, or lightweight mappers. The appeal is simple: less magic, more explicit code. You write more by hand, and that is the tradeoff. Many teams prefer that cost because the code tells the truth.
The payoff is easier debugging, simpler reviews, and a cleaner path from HTTP request to SQL query to Go struct. Once a codebase has real traffic and real maintenance work, that kind of clarity matters more than convenience.
What control means in day-to-day Go work
For most Go teams, control is straightforward. You can read the SQL without digging through layers, you can predict what the database will do, and a teammate can review a change in a few minutes. When a query slows down, there should be one obvious place to inspect.
That is why many teams stop short of a full ORM. They do not hate abstraction. They just want less hidden behavior. If a join, filter, or transaction gets complicated, the code should still look close to the SQL that runs in production.
The common styles solve that in different ways. Helpers wrap low-level work like scanning rows, handling placeholders, or managing connections while keeping the query text hand-written. Builders assemble SQL in code, which helps when filters are optional or reports branch in several directions. Mappers turn query results into structs with less repetition, but the SQL usually stays visible.
None of these styles gives you perfect control all the time. Helpers are direct but repetitive. Builders cut down on string juggling, but they can hide the final query if a team leans on them too hard. Mappers keep handlers tidy, yet they can tempt people to pile tags and magic onto every model.
A simple example makes the tradeoff clear. Say your team owns an endpoint that lists orders with five optional filters and a separate count query. A helper works well if the rules rarely change. A builder makes more sense when product keeps adding filter combinations. A mapper helps once the same result shape appears in several handlers.
The better choice is usually the one that keeps surprises low for that service. Keep SQL close to the code that uses it. Log slow queries. Check plans for the few calls that hit the database all day. No single style wins everywhere, and mixing two styles in one codebase often works better than forcing one pattern on every service.
Raw SQL helpers: database/sql and pgx
Most Go teams start with database/sql for a reason. It is in the standard library, it keeps the stack small, and it makes every query easy to see. If you want control over SQL, transactions, and connection use, this baseline still works well.
database/sql also fits gradual change. A team can keep existing SQL, move one package at a time, and avoid a big rewrite. That matters when you already know your schema and you do not want a tool that hides joins, filters, or transaction boundaries behind a large API.
The tradeoff is obvious once you have used it for a while. You write the query, run it, scan every field by hand, handle NULLs, and repeat that pattern again tomorrow. Small apps can live with that. Bigger codebases often end up with a lot of similar scan code and a few helpers that only partly reduce the repetition.
For PostgreSQL-heavy projects, pgx often feels better than staying close to database/sql alone. It gives you stronger PostgreSQL support and exposes features teams actually use, including better type handling, batch work, COPY, and PostgreSQL-specific behavior that generic drivers tend to smooth over. If your app leans on arrays, JSONB, or high write volume, that extra control is usually worth it.
pgx also gives teams a more direct PostgreSQL mental model. You spend less time fighting the lowest common denominator and more time using the database you actually picked. For a product with heavy reporting, background jobs, or event ingestion, that saves real time in both coding and debugging.
A simple rule works well. Use database/sql when you want the smallest abstraction and broad driver compatibility. Use pgx when PostgreSQL sits at the center of the app and you want its full feature set. Stay with raw SQL helpers when your team reads SQL comfortably and wants explicit behavior.
The cost stays the same either way. Raw SQL helpers keep logic visible, but they do not remove manual mapping. Developers still need discipline around query reuse, naming, and tests. Without that, a clean data layer turns into scattered SQL strings and copy-pasted scan blocks, which is just ORM sprawl in a different shape.
Query builders for dynamic queries
A builder helps when the shape of a query changes often. That happens in real products more than people expect. An admin search page starts with status and email, then gains date ranges, team filters, sort options, and one more checkbox every other sprint.
Writing every variation by hand gets messy fast. You end up with long if chains, string joins, and a pile of nearly identical SQL. A good builder keeps that logic readable while still letting the team control the final query.
This is where builders usually earn their place: admin search screens with many optional filters, report pages with date ranges and sorting, exports where users can pick columns or limits, and optional joins such as adding account or billing data only when needed.
The win is not magic. The win is structure. Instead of stitching raw strings together, you add conditions step by step and keep parameters separate from SQL text. That lowers the chance of broken placeholders and makes review easier.
Optional joins are a good example. If a report only needs customer data sometimes, a builder can add that join only when the filter asks for it. That is much cleaner than keeping three or four separate query templates that drift apart over time.
Still, builders do not excuse weak SQL habits. They can make bad queries easier to write, and that is still bad. If the team ignores indexes, selects every column, or keeps piling on joins without checking the plan, the builder will not save them.
A few habits matter more than the library. Log the final SQL and arguments in development. Check query plans for slow report screens. Keep filters predictable and name them clearly. Stop when the builder reads worse than plain SQL.
My bias is simple: use a builder for changing filters, not for every query in the codebase. Straightforward reads and writes often stay clearer in raw SQL. Builders fit the awkward middle ground where queries are real SQL, but the conditions change often enough that hand-built strings become a maintenance problem.
Lightweight mappers that keep SQL visible
Lightweight mappers are often the middle ground that feels easiest to live with. You keep writing SQL by hand, but you stop wasting time on repetitive Scan calls and column ordering bugs.
sqlx is the usual example. It sits close to database/sql, so the mental model stays simple. You write the query, pass arguments, and map the result into a struct with db tags.
type UserRow struct {
ID int64 `db:"id"`
Email string `db:"email"`
Role string `db:"role"`
}
var user UserRow
err := db.Get(&user, `
SELECT id, email, role
FROM users
WHERE id = $1
`, userID)
That small step removes a lot of boilerplate. It also keeps the SQL easy to read in code review. Nobody has to guess what the library generated, and debugging stays direct when a query gets slow or returns the wrong shape.
Other mapper-style tools, such as scany with dbscan, follow the same idea. They map rows into structs without turning your codebase into a web of models, hooks, and hidden query behavior. They work best with small structs that match one query result at a time.
A UserListRow can differ from UserDetailRow. That is usually better than one giant User struct that tries to fit every endpoint, report, and background job. Teams often resist this at first, but small result structs make changes safer.
Lightweight mappers feel better than full ORMs when your team wants clear SQL, custom joins, common table expressions, or database-specific features without a fight. They also fit well when you already have raw SQL helpers and want a smoother developer experience instead of a full rewrite.
They are not magic. You still design queries, manage transactions, and think about indexes. For many teams, that is a good trade. You save time on tedious row mapping, but you keep control over what hits the database.
How to choose for your codebase
Start with the database you already run and the queries you already ship. Teams often pick a library by taste, then spend months undoing that choice. Your schema, query volume, and failure points should matter more than trend or habit.
Split your query work into a few real buckets. Stable queries, dynamic queries, and write-heavy paths usually want different tools. A login query or a fixed billing report can stay close to raw SQL. A search screen with ten optional filters often gets easier with a builder. Busy write paths usually benefit from direct SQL and explicit transactions because every extra layer hides timing and lock behavior.
If your team already works well with database/sql, do not assume you need a bigger jump. In many codebases, database/sql plus a small helper, or sqlx for scanning convenience, is enough. If you use PostgreSQL heavily and want tighter control, pgx often feels cleaner than adding a mapper on top of everything.
Pick one default style for most new code, then allow a few exceptions. Use raw SQL for fixed queries and hot paths. Use a query builder for filter-heavy screens and report endpoints. Use a lightweight mapper only when it removes repetitive scan code without hiding SQL. Write those rules down in your repo, not in someone else's head.
That default matters more than teams expect. Once every service uses a different pattern, review quality drops. New developers waste time learning house rules that change from folder to folder.
Test the choice in one service before you spread it across the codebase. Migrate a small but real slice of work, such as an internal admin API or a billing module. Then check four things: query clarity, test effort, review speed, and how painful schema changes feel. If that pilot stays boring in a good way, you probably found the right fit.
A realistic team example
A five-person product team starts with a Rails app that uses ActiveRecord for almost everything. It works, but the team gets tired of hidden queries, surprise joins, and model callbacks that change checkout logic in places nobody expects.
They decide to move two parts of the product to Go first: checkout and reporting. The split is practical. Checkout has a small set of stable queries, while reporting changes every month because product and finance teams keep asking for new filters.
For checkout, the team picks raw SQL with pgx for the payment, order, and inventory flow. Those queries touch money, stock, and transaction boundaries, so they want every SELECT, UPDATE, and COMMIT to stay visible in code review. When someone changes a discount rule, reviewers can read the SQL and spot the risk in a minute.
Reporting gets a different treatment. The reporting screens let users filter by date range, order status, country, and sales channel. Writing that with plain string concatenation gets messy fast, so the team uses a query builder for those endpoints. The SQL shape still stays clear, but nobody has to hand-build ten versions of the same WHERE clause.
They use a lightweight mapper for read models and small admin tools. An internal page that lists failed payments, or a support screen that shows recent refunds, does not need a heavy pattern. A tool like sqlx saves some row-scanning boilerplate without hiding the query itself. That is often the sweet spot in the database/sql vs sqlx choice.
The team writes down three rules and sticks to them: stable business flows use raw SQL, dynamic search and reporting use a builder, and internal reads and admin pages can use a lightweight mapper.
This mix keeps the migration calm. Reviews stay short because each pull request has an obvious shape. Nobody has to guess what the ORM generated, and nobody tries to rebuild Rails inside Go. That matters more than picking the "best" tool.
Mistakes that recreate ORM sprawl
Teams usually do not choose a messy data layer on purpose. It happens one shortcut at a time. A service starts with database/sql, then someone adds sqlx for scanning, another person adds a query builder for one report screen, and a fourth package sneaks in for migrations or generated models. Six months later, nobody knows which style is the default.
Using several libraries in one service is not automatically wrong. The problem starts when each team member solves the same problem with a different tool. Reviews get slower, bugs get harder to trace, and new developers spend their first week learning house rules that were never written down.
Another mistake is hiding SQL inside helper layers that nobody reads. A function like GetActiveUsers() looks clean until it calls three other helpers, adds silent filters, and changes behavior based on flags from elsewhere in the code. The SQL still exists. It just moved to a place where people stop checking it.
The same pattern shows up with query builders. They help when filters are truly dynamic. They are a poor fit for a plain query with one join and two conditions. If a simple SELECT turns into a long builder chain, the code got worse, not better. Most developers can read SQL faster than a stack of chained method calls.
The warning signs are familiar: similar queries use different libraries in the same package, reviewers discuss Go code but skip the SQL itself, developers need helper functions to understand basic filtering, and query builders appear in places where raw SQL would be shorter.
Tests do not save you from bad queries. A test can pass while a query still scans too many rows, hides an accidental cross join, or depends on database behavior that will hurt during growth. Teams should review SQL as carefully as they review Go code. Read the query text, check the shape of the result, and ask whether the next person will understand it in a minute.
If you want control without ORM sprawl, pick one default style per service, write it down, and make exceptions rare. That rule sounds boring. It also keeps the codebase calm.
Quick checks before you commit
Pick one real query path before you choose a library. Use a simple read, a write, and one query with optional filters. A tool can look clean in a demo and still feel awkward once your team starts changing it every week.
The first test is simple: can a new teammate read the query quickly? Open the code and ask someone who did not write it to explain what hits the database, which fields get scanned, and where errors go. If they need to jump through helpers, generated code, and custom wrappers just to understand one query, that friction will spread.
Logs matter just as much as code style. When something slows down in production, your team needs to see the final SQL, bound arguments when they are safe to print, and timing. If a builder or mapper makes the query nicer to write but harder to inspect, debugging gets expensive. Pretty method chains do not help when nobody can see the exact statement the database ran.
Check migrations next. Teams often miss this part. If you already write migrations in plain SQL, a library that keeps SQL visible will usually fit better. If the library pushes you toward a very different style than your migration files, you may end up with one way to change schema and another way to query it. That split gets annoying fast.
Tests should cover the boring cases, because that is where many data bugs live: empty result sets, NULL values in optional columns, scan errors from wrong field types, and changed column order or missing fields.
A small test table will expose a lot. Try one nullable timestamp, one JSON column, and one left join that sometimes returns nothing. That setup tells you more than a feature grid.
If the library stays readable, shows real SQL in logs, fits your migration habit, and survives these tests without odd workarounds, it is probably a safe choice.
Next steps for a clean move
A clean move starts small. Do not swap data access across the whole codebase in one pass. Pick one service and one query type first, such as a read-heavy list endpoint or a single write path with clear inputs and outputs. That gives the team one real test instead of a long debate.
Choose something boring on purpose. A search screen with optional filters is good for a query builder. A simple account lookup is better for raw SQL or a small mapper. Keep the old pattern in the rest of the app while you test the new one. Reviews stay simpler, and you avoid a week of mixed styles.
Write one short team rule before you merge anything. Keep it plain enough that a new developer can follow it on day one: use raw SQL for fixed queries that need to stay easy to read, use a builder only when filters, sorting, or joins change at runtime, use a lightweight mapper when scanning rows is repetitive but the SQL should stay visible, and keep transactions, migrations, and error handling explicit.
After two or three weeks, check the work, not opinions. Look at pull request review time, query bugs found in testing or production, and how much code changed when a field or filter moved. If one approach saves a few lines but makes reviews slower, that trade usually is not worth it.
For many teams, the right answer is a mix. database/sql or pgx can handle steady paths, while a builder handles the few queries that change shape. That keeps your data layer from turning into another abstraction nobody wants to touch six months later.
If this choice also affects product speed, cloud spend, or a larger refactor, an outside review can help. Oleg Sotnikov at oleg.is works with startups and small teams on Go architecture, infrastructure, and fractional CTO work, and this kind of migration fits that scope well.


