Go service templates that avoid framework lock-in pain
Go service templates help teams keep routing, config, and observability consistent while each service stays small and free from framework lock-in.
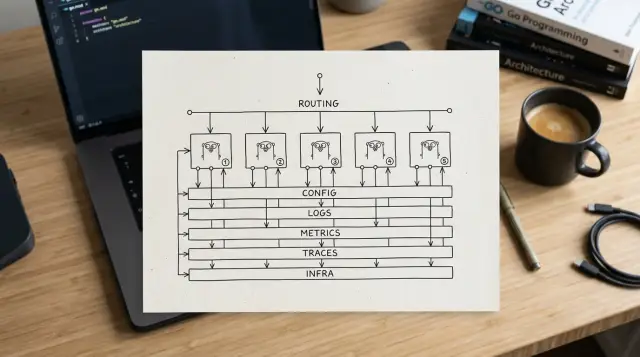
Table of Contents
Why copy-paste services drift
Copy-paste feels fast on day one. You start with one working service, duplicate it, rename a few packages, and ship. For a week or two, that works.
Then the copies start to drift. One repo gets timeout middleware and request IDs. Another skips both because the deadline is tight. A third adds a custom auth check that nobody remembers to copy later.
That is how drift starts. Not with one big architecture choice, but with a pile of small edits made by different people at different times.
Config usually breaks next. One repo uses PORT, another uses HTTP_PORT, and a third reads both because someone wanted backward compatibility. Database settings, feature flags, and API keys keep growing, but the naming never gets cleaned up. After a few months, developers have to guess which environment variables still matter and which ones are leftovers.
Logs drift even faster. One service logs plain text. Another logs JSON. A third uses different field names for the same thing, such as request_id, traceId, or just id. During an incident, that wastes real time. You cannot filter cleanly, compare services side by side, or trust that the same field means the same thing everywhere.
Code review slows down too. Reviewers stop looking only at business logic. They also check whether shutdown works the same way, whether health endpoints match the other services, and whether metrics still use the same labels. Small differences pile up, and routine reviews turn into archaeology.
A simple Go microservice setup should make the common parts boring. If every team copies a full service and edits it freely, the template becomes a snapshot instead of a standard. That is where many Go service templates go wrong.
You can feel this with only four services. A bug hits production, and the first twenty minutes disappear into questions that should have obvious answers: which logger does this service use, does it expose the same health check, which env var turns on debug mode? Drift turns simple work into detective work.
What every service should share
Small Go services stay easy to run when the boring parts look the same everywhere. Each repo should start in the same order: load config, create the logger, set up metrics and traces, build dependencies, register routes, start the server, then shut down cleanly. When every service follows that path, a new teammate does not need half an hour to find the startup logic.
Config needs one clear order too. Pick it once and keep it everywhere. A common rule is defaults first, then environment values, then secrets. It sounds minor, but teams lose real time when one service reads a timeout from HTTP_TIMEOUT, another uses SERVER_TIMEOUT, and a third ignores both because a local file wins. Config loading should be predictable.
Health and readiness checks should also mean the same thing in every repo. A health endpoint answers one question: is the process alive? A readiness endpoint answers another: can this service do useful work right now? If the database is down, readiness should fail. If the process is still running and can recover, health can stay up. That split makes deploys and incident response much less confusing.
The shared contract is simple. Services should have the same startup and shutdown flow, the same config naming and precedence rules, the same health behavior, and the same basic log, metric, and trace fields.
Observability matters most when something breaks at 2 a.m. Logs should have one shape across every service. Metrics should follow the same naming rules. Traces should carry the same request and trace fields through handlers and downstream calls. Then one dashboard can compare services without a pile of custom fixes.
That does not mean every service must use the same router forever or expose every metric under the sun. Share the contract, not every internal choice. Teams need familiar startup, config, and observability rules, while each service stays small enough to change later.
Many templates miss that balance. They try to share too much. Share the parts operators and developers rely on every day, and leave the rest alone.
What each service should decide on its own
A service works best when it owns the words, rules, and data shapes of its problem. A billing service should talk about invoices, refunds, and payment status. An auth service should talk about sessions, tokens, and roles. Once a shared template starts defining those models, every new service bends around someone else's choices.
Keep the working parts close together. Handlers, storage code, and business rules should live inside the service unless two services truly run the same logic. Teams often share too early, then spend months pulling things apart when a tidy package turns into a bottleneck.
Most services need freedom in a few places: their domain model and validation rules, their database access and migration style, the third-party packages they depend on, and their own jobs, caches, or external clients.
That freedom matters more than people expect. A reporting service may want raw SQL and simple read models. A webhook receiver may need almost no storage at all. If the template forces both into the same repository layer or ORM, the template stops helping.
The same rule applies to dependencies. Choose packages per service, not per template. If one service needs a queue client, add it there. If another only reads from PostgreSQL and writes logs, keep it that small. Good Go service templates give a clean starting point, then let each service stay boring in its own way.
A simple example makes this obvious. Suppose you build auth, billing, and file import. Auth needs token signing and rate limits. Billing needs careful transaction handling. File import needs CSV parsing and a worker loop. If all three inherit the same cache layer, ORM helpers, and background job package, two of them carry code they never asked for.
Add packages only when the service has a real use for them. Every extra dependency adds upgrades, bugs, config, and mental overhead. A template should standardize routing, config loading, and logs, but it should not decide how each service thinks.
Build the template step by step
Start with the least amount of shared code you can get away with. Good Go service templates stay plain: one small main package, one config package, one observability package, and only a few rules that every service follows.
Keep main thin. Its job is to read config, create dependencies, register routes, start the server, and stop cleanly. If business logic leaks into main, every new service becomes a snowflake and the template stops helping.
Keep the shared layer narrow
The safest template uses small interfaces around startup and routing, not a giant app container. A service might expose one method to register HTTP handlers and another to run startup checks. That is enough for consistency without forcing every team into one router or one package layout forever.
Keep the router contract small on purpose. If the shared layer needs to know every feature of a specific framework, you already have lock-in. Most services only need to map paths, attach middleware, and expose health endpoints.
Load environment variables into one config struct early, then pass that struct down. Avoid scattered calls to os.Getenv across the codebase. When config lives in one place, people can see defaults, required values, and naming rules without hunting through files.
A good startup flow is short and easy to scan: parse env vars into a typed config struct, validate required settings before the server starts, build the logger and telemetry from that config, create dependencies, register routes, run one startup check, and then serve traffic.
Wrap observability lightly
Logs, metrics, and tracing should sit behind thin helpers. Think small adapters, not a large internal framework. A logger helper can add common fields like service name and version. A metrics helper can expose counters and latency timers with shared names. A tracing helper can create spans around requests and outbound calls.
That keeps daily work simple. A new service gets the same log format and the same health signal, but handler code still looks like normal Go.
Before you call the template done, add two safety nets. Write one smoke test that boots the service with test config and checks that /health returns success. Then add one startup check that fails fast on bad config or missing dependencies.
Teams that run lean systems get a lot from this style because it catches broken deploys early without much extra code. That is also why engineers like Oleg Sotnikov focus so much on simple operational rules: small, consistent checks usually beat a large internal framework.
Three services, one base
Three Go services can start the same way and still behave very differently where it counts. That is the sweet spot: shared structure, small code, and no framework lock-in.
Picture a team with orders, billing, and notifications. Each service loads config the same way, starts the HTTP server with the same middleware, exposes the same health routes, and writes logs in the same format.
A new engineer can open any repo and spot the basics fast. They can see where config comes from, how the service starts and stops, which health endpoints exist, and how logs, metrics, and traces are wired.
That sameness saves real time. You do not waste half a day figuring out why one service uses env vars, another reads YAML, and a third logs plain text with no request ID.
Same skeleton, different rules
The orders service may have stricter request handling. It checks auth on every write route and uses idempotency keys so a client can retry a purchase without creating duplicate orders. Its business rules live in the handler and service layer, not in framework magic.
Billing looks similar at startup, but its risk sits elsewhere. It calls outside payment systems, so it needs retry rules, timeout limits, and clear error mapping. The shared template can provide a basic retry helper, but billing should decide when to retry and when to stop.
Notifications has a different shape again. It may expose a small API, but much of its work happens in queue workers. It still uses the same config loader, the same logger, and the same health endpoints. On top of that, it adds worker concurrency settings and rate limits so one noisy event does not flood email or SMS providers.
The win shows up when something is missing. If billing emits traces and notifications exports queue metrics, a new engineer will notice fast when orders forgets telemetry on a new endpoint. The gap is obvious because every service follows the same baseline.
That is the whole idea. Share startup, config, and observability. Let each service own its own rules.
Routing, config, and logs in practice
When a service breaks in production, the pain usually comes from weak habits, not from Go itself. Teams lose time when routes are buried, config names change from repo to repo, and logs leave out the one field they need.
Keep route groups shallow. Group once by domain, then stop. Paths like /api/v1/users and /api/v1/invoices are easy to scan. Deep nesting turns a small service into a maze. A good template makes the route map obvious in one place, even if handlers live in separate files.
This also helps you avoid framework lock-in in Go. If you swap one router for another later, the route layout should still make sense because the structure belongs to the service, not the framework.
Config needs the same discipline. Pick one prefix rule and use it everywhere. If the service is billing, use names such as BILLING_HTTP_PORT, BILLING_DB_DSN, and BILLING_QUEUE_URL. Do not mix APP_PORT, PORT, and BILLING_PORT across different services. One rule removes guesswork during local setup, deploys, and incident response.
Logs should answer simple questions fast: which request failed, which service handled it, and what error happened? Add a request ID to every request log. Add the service name too. When you log an error, include structured fields like operation name, status code, dependency, and error text. Plain text logs look easy at first, but they get hard to filter when traffic grows.
Metrics show trends that logs miss. Measure request latency, error counts, and calls to outside dependencies. If a checkout endpoint slows down, you want to know whether your handler is slow or the payment API is slow. That split saves time during an outage.
Tracing connects the full path. Start a span at the edge, right when the request enters the service. Then wrap each database query, cache call, or external API call in child spans. With that setup, three small Go services still feel readable when one user action touches all of them.
A team does not need much more than that. Keep routes flat enough to scan quickly, use one config prefix per service, log request ID and service name, track latency and errors, and start traces at ingress and around outbound calls. That level of consistency is usually enough.
How teams create lock-in
Teams usually create lock-in by accident. They start with a neat template, then turn it into a rule that every service must follow in every detail. After a few months, small Go services stop feeling small.
The first mistake is letting one web framework leak into every package. A handler imports framework types, shared code depends on them, and now even a tiny background service carries HTTP baggage it does not need. Swapping the router later becomes a rewrite.
Another common problem starts in middleware. Teams put auth, validation, tenant rules, pricing rules, and other business decisions into long middleware chains because it looks tidy. It is not. When business rules live there, nobody can tell what a request actually does without tracing five layers of wrappers.
A shared config module can create the same mess. If one package loads every env var for every service, each binary drags around settings it never uses. The result is noise, hidden coupling, and deploys where a harmless change in one service breaks startup in another.
Most of the pain comes from a few habits: centering everything on one framework, burying product rules inside middleware, collecting all env vars in one global config package, adding shared helpers before two services really need them, and changing log field names from service to service.
That last one looks minor, but it hurts daily work. If one service logs request_id, another logs reqId, and a third logs trace, dashboards and searches get messy fast. Consistent field names save real time when something breaks late at night.
The fix is deliberately boring. Keep the template thin. Share interfaces, log conventions, config patterns, and the basic startup shape. Let each service choose its own routes, package layout, and business logic.
Checks before your team adopts the template
If a template saves an hour today but traps your team next month, it is not a good template. Run a few plain tests before you make it the default.
Start a fresh service and time it. One engineer should be able to boot it, add one route, load config, and emit logs in under fifteen minutes. If that takes much longer, the template asks for too much setup.
Then ask two engineers to build the same tiny API with the template. If they end up with different route groups, folder names, or middleware order, your rules are still too vague.
After both services run, open the dashboards. You should see the same basic signals for each one: request count, latency, error rate, and service version. Then replace the router in a test branch. If that change spreads into handlers, business logic, and config loading, the router sits too deep in the code.
One more test is worth doing: delete a part nobody needs, such as queue code or extra middleware. If the team feels nervous about removing it, the template already has too much hidden coupling.
This matters more than most teams admit. A template often looks clean when one person builds it, but the real problems show up when two people use it in parallel. One puts health checks under /internal, the other uses /system. One logs request IDs in middleware, the other adds them in handlers. Those small differences turn into drift after three or four services.
Good Go service templates keep the shared parts boring. Routing should live in a thin adapter layer. Config should load the same way every time. Logs and metrics should use the same field names, so nobody has to guess what service, env, or trace_id mean in production.
The most useful test is still simple: swap the router, keep the handlers. If that works with only a small edit near the edge of the service, you avoided framework lock-in. If it takes a day, the template is too opinionated.
The safest template is usually smaller than people want.
Rolling it out without drama
Start with one new service, not a rewrite. Pick something small but real, like an internal webhook receiver or a background worker, and build it with the template from day one. That gives the team a safe test without dragging old code into the experiment.
A good pilot should touch the parts that usually drift first: routing, config loading, logs, health checks, and basic metrics. If the service goes live and nobody argues about folder layout or log fields for two weeks, that is a good sign. If people keep working around the template, fix the template before you spread it.
Write down a short rule set and stop there. Most teams need only a few rules: every service starts the same way and exposes the same health endpoints, config follows the same source order and naming style, logs include the same base fields, metrics and traces follow one naming pattern, and teams can swap routers, storage, or job runners behind a small local interface.
Do not add rules for problems your team has not actually hit yet. Thin rules survive. Thick rule books get ignored.
After the first month, review drift on purpose. Compare the pilot with a second service and ask simple questions: which shared parts did people keep, which parts did they bypass, and which files stayed untouched? Delete dead code fast. If a helper package looked smart in the template but nobody used it, cut it.
That review also tells you whether your Go service templates are staying small. If shared code starts pulling business logic into one common package, split it back out. A template should save setup time, not hide coupling.
A practical rhythm works well: pilot in week one, write the rules in week two, ship a second service in weeks three and four, then do a drift review at the end of the month. By then, the team usually knows whether the template helps or just adds ceremony.
If you want an outside review before rolling it out more widely, oleg.is is a good example of the kind of Fractional CTO work that fits here. Oleg Sotnikov focuses on architecture, observability, and lean AI-first engineering, which is often most useful when the template is still small enough to change in a day.
Frequently Asked Questions
What should every Go service share?
Share the boring operational parts. Use the same startup flow, config loading rules, health and readiness behavior, and the same basic fields in logs, metrics, and traces so every repo feels familiar.
What should each service decide on its own?
Let each service own its domain model, validation, storage choices, outside clients, and job logic. A billing service, auth service, and import worker should start the same way, but they should not share business rules just because a template can hold them.
How much code should a Go service template include?
Keep it smaller than you want. A thin main, one typed config package, and light observability helpers usually cover most of the value without turning the template into a framework.
How do I avoid framework lock-in?
Keep framework types near the edge. If handlers, business logic, or shared packages depend on one router too deeply, swapping it later will hurt. A small local adapter around routing keeps that choice easier to change.
How should I standardize config across services?
Pick one naming rule and one precedence rule, then keep them everywhere. Load defaults first, then environment values, then secrets, and avoid mixing names like PORT, APP_PORT, and service-specific variants across repos.
What is the difference between health and readiness checks?
Health should answer whether the process is alive. Readiness should answer whether the service can do useful work right now. If the database is down, readiness should fail even if the process still runs.
What observability should every service have by default?
Start with request ID, service name, status, error text, and operation name in logs. Track request count, latency, and error rate in metrics, then add spans at request entry and around database or outside API calls so you can follow one request across services.
How can I tell if the template is too opinionated?
Time a fresh setup. One engineer should boot a new service, add a route, load config, and write logs fast. If the template fights simple work or removing unused parts feels risky, it has grown too large.
Should I put business logic in middleware or shared packages?
No. Put auth checks, pricing rules, tenant logic, and other product decisions where the service code can show them clearly. Long middleware chains and early shared packages hide behavior and create coupling.
What is the safest way to roll out a new template?
Start with one small real service, not a rewrite. Use it for a few weeks, compare it with a second service, and keep only the shared parts people actually use. If the team keeps bypassing a helper, delete or simplify it.


