Go logging libraries for clear traces in production
Go logging libraries differ a lot in JSON output, request IDs, and setup time. This plan compares the main options for clear service logs.
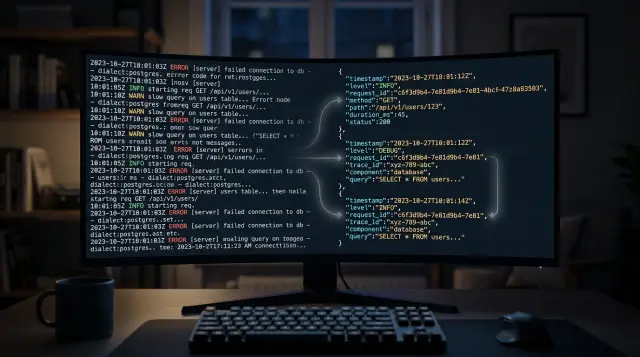
Table of Contents
Why service logs turn into noise
Most service logs fail for a simple reason: they describe isolated moments, not a request. One line says "started handler" and another says "db timeout," but nothing ties them together. During an incident, you scroll through hundreds of lines and guess which messages belong to the same user action.
The noise gets worse when a service repeats the same error at every layer. One slow database call can produce near-duplicate messages from the handler, service, repository, retry loop, and background worker. The team reads the same failure five times and still doesn't know which customer hit it, which endpoint triggered it, or how long the request took.
One useful event beats ten noisy ones. A log entry with a request ID, route, status code, latency, and error reason gives you the story in one place. A plain line like "payment failed" gives you almost nothing. You still have to hunt through surrounding logs to piece things together.
This is why teams start comparing Go logging libraries. They don't need more output. They need logs that carry context without filling the screen with duplicates.
The goal is simple: fewer lines, more context. When each event tells you who made the request, what the service tried to do, and where it failed, incidents get shorter and production feels less chaotic.
What useful traces look like
Useful traces answer three questions fast: what happened, which request it belongs to, and whether anyone needs to act on it. If a log line can't help with one of those, it usually adds noise.
A good event starts with a small set of fields that stay consistent across the service: time, level, message, and request_id. That gives you a timeline, a sense of urgency, and a way to follow one request across handlers, workers, and downstream calls. In Go logging libraries, this matters more than fancy formatting. Consistent fields beat clever messages every time.
After that, add context only when it changes the decision you'll make. Route and status help on request completion. A user identifier helps when support needs to trace one person's problem. Latency helps when you're chasing slow paths or timeouts. If every line carries every field, logs get heavy and harder to scan.
One event per action works better than a play-by-play. Log that the payment attempt started, then log the result with the outcome and reason. Don't narrate every function call, retry, and branch unless you're debugging a specific fault.
It also helps to keep different kinds of output apart. App events should describe business actions and failures. Access logs should record request summaries. Stack traces should appear only on real errors, not on normal validation failures. When those streams stay separate, you can scan a bad request in seconds instead of digging through a wall of text.
How to compare Go logging libraries
Compare each package with the same tiny HTTP handler. Log one request, one database timeout, and one panic recovery. That small test tells you more than any feature table.
Start with the raw output. Good Go logging libraries should give you clean JSON logs without extra wrappers, custom field mappers, or hand-built helpers. If a package makes basic structured logging awkward on day one, it usually stays awkward later.
Then look at request correlation. A logger should make it easy to attach a request ID, user ID, trace ID, or route name from context without turning every function call into plumbing work. If your team has to remember five manual fields on every log line, people will skip them when things get busy.
A simple scorecard works well. Can you get readable JSON in production and plain text locally with little config? Can you add request IDs from context in one obvious way? Does the API stay clear when you add fields, errors, and caller info? Does it stay fast under load, with low allocations? Can you turn on sampling so repeated errors don't flood the logs?
Setup time matters more than many teams admit. Some packages look fast in benchmarks, but they need extra glue around config, context handling, or adapters for third-party middleware. That cost shows up every time a new service starts.
Caller info is worth checking in real output, not in docs. Some libraries print file and line data in a clean way. Others add noise or make the line hard to scan. Sampling needs the same kind of test. If one broken dependency throws the same error 20,000 times, your logger should keep the signal and drop the spam.
Speed still matters, but clear logs come first. A logger that saves a few allocations doesn't help if developers avoid using it.
Slog for teams that want the standard path
slog gives Go teams a structured logger in the standard library. That matters. You get log levels, named fields, and a common API without adding another package to every service. For a new codebase, that usually means fewer debates and a faster start.
The handler model is simple and useful. You can use a text handler for local work, where humans need to scan logs quickly, and switch to a JSON handler in production, where log tools need clean fields. The log calls stay the same. You change the handler at startup and leave the rest of the code alone.
slog also works well with request correlation, but you still have to wire it. Middleware can put values like request_id, user_id, or trace_id into context. Then your logger or handler can read those values and attach them to each record. That keeps a payment failure, retry, and timeout under one thread instead of scattering them across the log stream.
The rough edge appears when you want custom field rules. Renaming fields, hiding secrets, changing time formats, or flattening error data often means writing a custom handler or using ReplaceAttr carefully. slog can do it, but the standard path stops feeling quite so simple once your logging rules get strict.
slog fits best when you're starting a new service, want structured logging without extra dependencies, and don't need heavy customization on day one. It's a sensible default for teams that want readable code now and room to grow later.
Zap for strict structured logs
zap fits teams that want logs to stay predictable under load. It writes JSON fast, keeps overhead low, and nudges developers to log named fields instead of dumping loose text into a message.
The split between Logger and SugaredLogger is the first thing to understand. Logger uses typed fields such as zap.String("request_id", id) or zap.Int("status", 500). That style is a bit more verbose, but it keeps logs clean and easy to query. SugaredLogger is quicker to write with calls like Infow, so it works well when a team wants zap without forcing everyone into the typed API on day one.
zap is also good at keeping field names steady. If the team agrees on request_id, user_id, route, and duration_ms, those names can stay the same across handlers, jobs, and internal clients. That consistency matters more than people expect. Once logs contain req_id, requestId, and trace for the same idea, filtering turns into guesswork.
Request correlation is straightforward. Middleware reads an incoming request ID or creates one, then builds a child logger with logger.With(zap.String("request_id", id)). Each handler uses that child logger, so every line for the same request carries the same field without repeating it by hand.
zap does ask for more setup than lighter options. You need to choose a config, encoder, timestamp format, caller settings, and which levels should include stack traces. That's extra work, but it pays off in busy services where many requests hit the system at once.
It works especially well for HTTP APIs with steady traffic, background workers with retries and failures, teams that rely on JSON logs in a central log store, and services where several developers need the same log shape. Among Go logging libraries, zap is a strong fit when you care more about clean structure and repeatable output than the fastest possible setup.
Zerolog and logrus in real teams
zerolog is a good fit when you want compact JSON logs and very little ceremony. Its output is clean, machine-friendly, and small enough that high-volume services don't waste space on extra text. In a busy API, that matters. Smaller log lines are easier to ship, store, and search.
Inside handlers, zerolog feels fast because fields chain naturally. You create a logger with a request ID, route, or user ID once, then keep adding fields as the request moves through the service. That style works well for request correlation. A payment handler can attach request_id, order_id, and customer_id early, then every later log line carries the same context without much repetition.
logrus feels more familiar to many Go teams, especially if they started with classic WithFields patterns years ago. It still gets the job done, and its API is easy to read. But it feels older now. It leans on patterns that came before slog and before the current push toward stricter JSON logs.
The ecosystem story is mixed in a practical way. logrus has a long trail of hooks, examples, and third-party packages, so it often survives in older codebases with shared wrappers and custom integrations. zerolog has solid middleware support, especially for HTTP services and context-aware logging, so it tends to fit new services better when clean structured output matters from day one.
Raw speed isn't always the deciding factor. Migration cost can matter more. If your team already has logrus wired into middleware, alerts, and internal packages, swapping it out may create weeks of dull cleanup work. If you're starting fresh, zerolog usually gives you clearer JSON logs with less baggage.
Add request correlation step by step
A request ID earns its keep on the worst day, not the best one. When a payment call returns 500 and two other services join the path, one ID lets you pull the whole story in seconds.
Start at the edge. Accept an incoming request ID if you trust the caller and the format looks sane. If not, generate your own in the first middleware or gateway. Do this before any business code runs. If each handler creates its own ID, request correlation breaks right away.
Store that ID in the request context and return it in a response header. Then support, frontend, and backend teams can all search the same value. If a customer says, "my card was charged but the page failed," that one ID can connect the API log, the retry job, and the outbound call to the payment provider.
Create a child logger once per request. Add fields such as request_id, route, and method there. Every later log line can inherit them, which keeps JSON logs clean and steady. Handlers should only add local facts when they learn them, such as user_id, order_id, or provider name.
Log errors once, close to the place where you know the final status code and route. That's often a small wrapper around your handler. Include the error, status, and duration. Skip the habit of logging the same failure in middleware, service code, and the database layer. Three copies of one error get noisy fast.
Keep the same logger moving through the whole path. Pass it into handlers, jobs started by the request, and outbound HTTP calls. Forward the request ID in headers or message metadata so the next service can keep the chain alive.
A simple payment API example
A customer taps Pay, and your service receives POST /checkout. The handler creates a request ID like req_9f3a, loads the cart, asks the payment provider to charge the card, and writes the order to PostgreSQL. If every log line carries that same ID, you can follow one checkout from start to finish in seconds.
Each line should keep the same small set of fields so the story stays readable: request_id, method, route, customer_id or cart_id, payment_id, amount, status, error, and duration_ms.
Noisy logs usually read like this:
starting checkout
calling provider
db write ok
slow query
payment failed
Those lines tell you almost nothing. You don't know which request failed, whether the charge happened before the database write, or whether the slow query belongs to the same customer.
Compact JSON logs tell the whole story:
{"level":"info","msg":"checkout_started","request_id":"req_9f3a","method":"POST","route":"/checkout","customer_id":"cus_42","cart_id":"cart_88"}
{"level":"info","msg":"payment_authorized","request_id":"req_9f3a","payment_id":"pay_771","amount":1299,"duration_ms":412}
{"level":"warn","msg":"order_insert_slow","request_id":"req_9f3a","order_id":"ord_901","duration_ms":1840}
{"level":"error","msg":"receipt_email_failed","request_id":"req_9f3a","error":"smtp timeout"}
Now the slow request is clear. The payment succeeded in 412 ms, but the order insert took 1840 ms. The email step failed after that, so support can tell the customer, "Your payment went through, but the receipt is delayed."
That same request ID also makes traces useful across services. If the API, worker, and database logs all include req_9f3a, one search shows the full path instead of a pile of unrelated noise.
Mistakes that bury the signal
A noisy log stream usually comes from habits, not from the logger itself. Even good Go logging libraries can't help much if every layer writes the same failure, dumps half the request, and uses a different name for the same field.
One common mistake is logging one error four times. A database timeout starts in the storage layer, then the service layer logs it again, then the handler logs it again, then middleware adds one more entry. You don't get four facts. You get one fact repeated four times, which makes incident review slower.
Another mistake is dumping whole objects into JSON logs. That often pulls in passwords, tokens, raw customer data, or giant payloads. It also makes search worse. If a payment request fails, log the order ID, customer ID, amount, retry count, and the error. Skip the full body unless you're in a short-lived local debug session.
Field names also matter more than teams expect. If one service writes request_id, another writes reqId, and a third writes trace, your filters break. Pick one set of names and keep them stable across services.
A few rules help. Log an error once at the boundary where someone can act on it. Treat debug logs as temporary diagnostics, not normal business events. Add IDs to jobs, retries, queue messages, and background tasks. Keep field names the same in every service. Log small, specific facts instead of whole structs.
Async work often gets ignored. A retry worker that logs "payment failed" without job ID, attempt number, or parent request ID is almost useless. When a system gets busy, that missing context costs real time.
Quick checks before you commit
A logging choice gets sticky fast. Once logs feed alerts, dashboards, and on-call habits, swapping the package later costs more than most teams expect.
When you compare Go logging libraries, start with output. If your service already ships logs into a log tool, JSON from day one is usually the safer bet. Plain text is nice on a laptop, but production tools need stable fields like level, service, request_id, and error.
Then test request correlation in a real handler. Add a request ID in middleware, call two internal functions, and check whether every line keeps the same ID without awkward plumbing. If the API fights you here, people will stop adding context when they get busy.
Use a short gut check. Can a new teammate read one handler and understand the logging call right away? Can your tests assert on a few fields instead of matching whole log lines? Do your current tools parse timestamps, nested fields, and errors the way this library emits them? Can you attach request_id in every handler without passing five extra arguments?
The testing part trips teams more often than they expect. Full log snapshots break on tiny format changes, and then nobody trusts the tests. It's usually better to decode the log output and check a few fields, like level, message, and request_id.
One last check is boring, but it saves real pain. Run sample logs through the tools you already use and confirm that search, filters, and alerts work with the fields this package emits. If your parser drops half the context, the nicest API in the world won't fix production noise.
What to choose for your team
Most Go logging libraries can write JSON and print errors. That doesn't make them equal in real production work. Pick the one your team will use the same way when a request fails, alerts fire, and someone needs to trace one user action across several services.
slog is the safest default for many teams. It's part of Go itself, so it feels familiar, and new developers can read it quickly. If you want standard library alignment and a simple path to structured logging, slog is usually the right call.
zap fits teams that want stricter habits. It works well when you care about fixed field names, clean JSON logs, and a mature setup that people have used in production for years. It asks for more discipline up front, but that often pays off once several services share the same logging rules.
zerolog is a good pick when log volume is high and you want compact JSON logs with very low overhead. Busy APIs and workers often benefit from that. If your team likes a lightweight style and doesn't mind its API choices, it can be a practical option.
Keep logrus only when migration cost is higher than the gain. Many teams still run it without major pain. Still, if you're starting fresh, the newer options make request correlation and structured fields easier to keep consistent.
A simple rule works well: pick slog for the default long-term path, zap for stricter structure and mature production patterns, zerolog for compact JSON and speed, and keep logrus only when replacing it would waste time.
Don't choose from benchmark charts alone. The right logger should match how your team writes handlers, reviews code, and debugs incidents.
Next steps
Pick one service that already gets real traffic. Don't push a new logging style across every codebase at once. Set one JSON schema, one request ID format, and a small set of fields that appear on every important log line, such as service, route, request_id, level, duration_ms, and error.
Write a thin middleware layer before logging spreads into handlers, workers, and helper packages. That middleware should create or read the request ID, attach shared fields, and keep names consistent. Most Go logging libraries work well once those rules are clear.
Then let the service run for a week and review the logs with real traffic in front of you. Noise usually shows up fast. A chatty health check, retry loop, or validation path can bury the lines you actually need during an incident.
That review usually finds a few easy fixes. Remove logs that repeat on every normal request. Keep error fields consistent instead of changing names by package. Log one summary for retries instead of every failed attempt. Make sure request_id stays present from the entry point to the database call.
If the team still argues about logger choice, stop debating package names for a moment. Pick the rules first, then choose the tool that fits them with the least friction. slog is often enough. zap or zerolog make sense when you want tighter control or lower overhead.
If you want a second opinion before this spreads through production, Oleg Sotnikov at oleg.is works with startups and small teams as a Fractional CTO and can help shape a logging and tracing setup that stays readable under load.
Frequently Asked Questions
Which Go logger should most teams start with?
Start with slog if you want the simplest long-term path. It ships with Go, gives you structured fields, and lets the team use one familiar API without extra packages.
When does zap make more sense than slog?
Pick zap when you want stricter JSON logs and steady field names across several services. It needs more setup than slog, but teams often like that trade when they care about typed fields and predictable output under load.
Is zerolog a good choice for high-volume services?
zerolog works well when your API or workers write lots of logs and you want compact JSON with very low overhead. It also feels natural when you want to attach request context once and keep adding fields as the request moves forward.
Should I replace logrus in an older codebase?
Keep logrus if the service already depends on it and replacing it would waste time. For a new service, slog, zap, or zerolog usually make structured logs and request correlation easier to keep consistent.
How do I add request IDs without touching every function?
Use middleware at the edge to accept or create one request_id, store it in context, and build a child logger with that field. Then handlers and downstream calls can reuse the same logger instead of adding the ID by hand on every line.
What fields should every request log include?
Keep the shared fields small: time, level, message, and request_id. Add route, status, duration_ms, and a user or order ID only when they help someone understand or act on the event.
Where should I log an error?
Log the failure once near the boundary where you know the final route, status code, and duration. If the handler or request wrapper writes that event, the service and storage layers should return the error instead of logging the same thing again.
Should production logs use JSON or plain text?
Use JSON in production so your log tools can filter fields like request_id, service, and error without guesswork. Keep plain text for local work if your team reads logs in a terminal and wants faster scanning.
How many log lines should one request create?
Aim for one event per meaningful action, not a play-by-play of every function call. A start event and a result event usually tell the story better than ten near-duplicate lines from retries, helpers, and middleware.
How should I test a logging library before choosing it?
Run a tiny real test before you commit. Log one request, one timeout, and one panic recovery, then check the raw output, request correlation, and whether your current search and alert tools parse the fields you care about.


