Go idempotency libraries for payments and sync jobs
Go idempotency libraries help payment APIs and sync jobs absorb retries, replay the same result, and keep one durable write in storage.
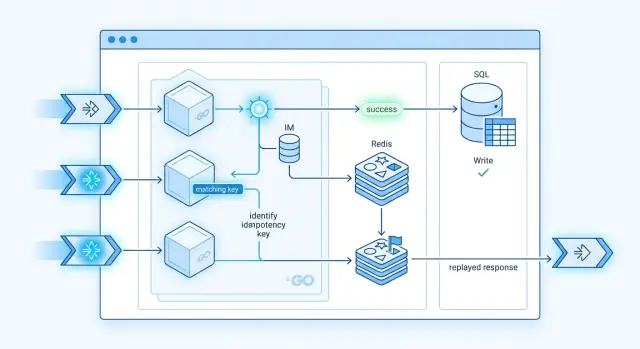
Table of Contents
Why duplicate writes happen
Most duplicate writes start with a plain failure, not a dramatic bug. A request reaches your server, your code saves the payment or inserts the row, and then the reply never makes it back to the caller. The caller sees a timeout and assumes nothing happened.
That assumption is often wrong. The write may have finished in a fraction of a second, while the network dropped the response right after. When the app retries a few seconds later, it sends the same intent again, and your handler may treat it as brand new work.
Payments make this expensive fast. A customer taps "Pay" again because the screen hangs. Your backend now gets two valid requests for the same purchase. If you create a new charge both times, you do not have a payment problem anymore. You have refunds, support messages, and a trust problem.
Sync flows break in a quieter way. An import job writes one customer record, then crashes before it marks that record as done. On restart, the job reads the same source item again and inserts another copy. One extra row sounds small until it spreads into reports, emails, and follow-up jobs.
Concurrency adds another path to duplicates. Two workers can pick up the same event at nearly the same moment because of a redelivery, a late acknowledgment, or weak locking. Each worker thinks it owns the job. Each worker writes.
The usual causes are simple:
- clients retry after a timeout
- users click the same button twice
- queues deliver the same event again
- workers restart in the middle of processing
None of this is rare. Retries are normal behavior in production systems. That is why Go idempotency libraries matter: they help your service recognize that the second request is the same action, not a new one. Without that check, one lost response can turn into a duplicate charge or a cleanup task that someone has to do by hand.
Where retries enter the flow
Retries usually start before your handler sees a problem. A client sends a request, the server does the write, and then the response gets lost or arrives too late. The client assumes the call failed and sends the same request again. That is how one user action turns into two writes.
Mobile apps do this all the time on weak connections. A phone moves between networks, the app times out, and the user taps "Pay" again because nothing changed on screen. The first request may already have reached your server.
Browsers add their own trouble. A slow checkout page invites a refresh, a double click, or a back-button submit. None of those actions mean the user wants two orders. They usually mean the page gave poor feedback.
Some retries come from systems you control:
- A queue worker finishes the database write but fails before it sends the ack. The queue thinks nothing happened and delivers the same job again.
- A cron job imports 8,000 records, stops at 7,200, and starts from the top on the next run because it did not save progress.
- An API client times out after 10 seconds, even though your server keeps working for 12 and commits the change at the end.
- A load balancer or proxy may retry an upstream call when it sees a broken connection.
This is why duplicate request handling starts outside business logic. If you only look at your payment code or sync code, you miss half the story. The retry often begins in the app, browser, queue, scheduler, or network path.
That matters when you review Go idempotency libraries. A helper that stores a key after the write is already late in some flows. You need to think about the full path: who retries, when they retry, and whether they send the same request body, the same idempotency key, or neither.
A good test is simple. Kill the response after the write succeeds, then watch what retries. You will usually find more than one source.
Idempotency and deduplication are not the same
Idempotency and deduplication solve related problems, but they do different jobs. Idempotency means the same request gets the same outcome every time. If a client sends "charge order 123 for $50" twice because of a timeout, your API should return one result, not create two charges.
Deduplication is narrower. It tries to spot repeats and ignore them. That works well for event streams, imports, webhooks, and sync jobs where the same record may arrive more than once.
The difference matters because one repeated input can still need a response. With idempotency, you often save the first result and return it again for later retries. With deduplication, you usually drop the extra event and move on. The caller may never see the original result.
Payments often need both layers together. The API layer uses an idempotency key so a retried request gets the same answer. The worker or message layer also deduplicates events, because payment gateways, queues, and webhooks can resend the same message later.
Pick the request fingerprint before you write code. That fingerprint tells your system what "the same request" means. In payments, it may be an idempotency key from the client, or a server-side combination such as merchant ID, order ID, amount, and currency. In a sync job, it may be the external record ID plus source system.
A weak fingerprint causes trouble fast. If you fingerprint only by user ID, two real purchases can collapse into one. If you fingerprint by a random retry token, the same payment can slip through twice.
Most Go idempotency libraries help with storage, locking, and replaying saved responses. They do not decide your fingerprint for you. That part is on you, and it is where many duplicate request handling bugs start.
A simple rule helps: idempotency answers the same request once and repeats the same answer, while deduplication throws away the extra copy. In payment idempotency in Go, you usually want both.
A request flow that returns one result every time
A good idempotent flow does one simple thing: it gives the same answer for the same request, even if the client sends it twice. That matters when a phone loses connection after tapping "Pay" and the app retries a second later.
The safest version starts before any side effect. Do not call the payment provider, write the order, or enqueue follow-up jobs until you check a shared store that every worker can see.
If the client sends an idempotency key, use it. If it does not, build a stable request hash from the fields that define the operation. The hash must ignore noisy data like timestamps or trace IDs, or you will treat the same request as new.
A simple flow looks like this:
- Read the idempotency record by key or hash.
- If you find a completed record, return the saved result.
- If you find nothing, create a record with a unique constraint and mark it "in_progress".
- Only the worker that wins that insert runs the write.
- After success, save the response body, status code, and any external reference, then return them.
That reservation step is where many teams slip. Two requests can arrive at the same time, and both can pass a "does it exist" check. A unique index, insert-once rule, or short lock stops that race.
When the second retry arrives, your handler should not run the business logic again. It should read the finished record and replay the same response. If the first worker still runs, you can wait for a short period and poll the record, or return a temporary status that tells the client to retry with the same idempotency key.
Postgres works well for this because it gives you transactions and unique constraints in one place. Redis can work too, but only if you treat expiration and lock timing carefully. For many teams, one durable table is the cleaner choice.
Store enough data to answer consistently. A status code alone is not enough. Save the actual result, plus the provider ID or row ID that proves the write already happened.
Go helpers worth reviewing
Most teams do not solve duplicate request handling with one package. They combine a thin HTTP wrapper, a fast cache, and a durable database rule. That mix works better than chasing a single magic fix.
When people look for Go idempotency libraries, they usually need two things: stop a handler from doing the same work twice, and return the same answer on a retry. Those are related, but they are not the same job.
A good starting point is middleware. It can read an Idempotency-Key header, build a request fingerprint, and wrap the handler before any payment or write starts. If the same request comes back a few seconds later, the middleware can return the saved status code and body instead of calling the business logic again.
That wrapper still needs a place to store state. The common choices each solve a different part of the problem:
- Redis works well for short retry windows. A
SETNXlock or a small record with a TTL can stop fast repeat calls and give quick lookups. - SQL tables with unique constraints give you durable protection. A unique index on something like
(account_id, idempotency_key)or a business identifier can block a second write even after a restart. x/sync/singleflightis useful inside one Go process. If two goroutines ask for the same work at once, it collapses them into one execution.- Queue consumers need their own guard. Store a message ID or event ID in a processed table, then acknowledge the message only after the write commits.
Redis is fast, but it should not be your final line of defense for payments. TTLs expire, caches get flushed, and networks fail at bad times. If charging a card or creating an invoice matters, keep a durable record in SQL and put the side effect and idempotency record in the same transaction when you can.
singleflight is handy, but it is easy to misuse. It only helps inside one process. If your API runs on three pods, each pod can still execute the same request unless Redis or SQL blocks it.
Queue workers have the same issue in a different shape. A broker may deliver the same message twice after a timeout or worker crash. If a sync job imports customer ext_123, record that external ID or message ID in a table with a unique constraint before you say the job is done.
The practical pattern is simple: middleware for request capture, Redis for fast retry suppression, SQL for the final yes-or-no decision, and singleflight for noisy bursts inside one instance. That stack is boring, which is why it holds up under retries.
Payment example: charge once, answer twice
A customer taps "Pay", the card processor accepts the charge, and then the network drops the response on the way back. Your API looks like it failed, but the money already moved. A few seconds later, the app retries the same checkout call.
That second call must carry the same idempotency key. Your Go service checks that key before it talks to the payment gateway again. If it finds a finished record for that key, it skips the charge step and returns the saved result from the first call.
A simple record usually stores:
- the current status
- the response body you want to return
- an expiry time
- the idempotency key itself
In practice, the first request writes a "processing" record, sends the charge, then updates the record to "succeeded" or "failed" with the exact response body. When the retry arrives, the handler reads that row and sends the same JSON back to the client. The customer sees one answer, even though the endpoint got hit twice.
That matters for payments because "probably charged" is not good enough. If the second request reaches the gateway again, you can bill the same order twice. If you return the first stored response instead, the checkout stays boring, which is what you want.
A small example makes it clear. Say order 4819 is for $49. The first POST /checkout times out after the gateway returns charge ID ch_123. Your service stores the success status, the gateway result, and an expiry time such as 24 hours. The app retries with the same idempotency key. Instead of creating charge ch_124, your API returns the original success payload with ch_123.
The expiry time keeps the table from growing forever. Pick a window that covers real retries and support cases. For payments, teams often keep these records longer than they expect, because customers retry late and finance teams ask questions even later.
Sync example: import one record once
A CRM sync often fails in a very ordinary way. The source system sends a customer update, the network times out, and then the same update arrives again a few seconds later. If your worker treats both deliveries as new work, you get two writes, messy logs, and sometimes two customer rows.
A safer worker gives each incoming change a stable identity. For sync jobs, that usually means the external customer ID plus a version number or source timestamp. If the CRM says customer crm_4821 changed at 2026-04-12T10:15:00, that pair should describe one change only, even if the worker sees it twice.
A simple worker rule
Store one local customer row per external ID, and make the database enforce that rule. Then let the worker apply updates only when the incoming version is newer than the one already saved.
In practice, the flow is simple:
- The worker receives customer
crm_4821with version17. - It checks whether version
17for that external ID was already applied. - If not, it runs an upsert on the customer row.
- If yes, it skips the write and records a duplicate hit.
That upsert matters. Without it, two retries can race and insert two rows before your app code notices. A unique index on the external ID stops that at the database level. The version or timestamp adds one more guard so an old retry cannot overwrite a newer update.
This is where deduplication for sync jobs differs from a plain retry check. You are not only blocking exact duplicates. You are also deciding which update wins when events arrive out of order.
Your job log should make that visible. One entry says the worker applied customer crm_4821 version 17. The next entry, for the same version, says duplicate hit and no change written. That log is boring, and boring is good. It means the same customer update can hit your endpoint twice and still leave the database in one clean state.
Mistakes that still create duplicates
Even with good Go idempotency libraries, duplicates still slip through when the request fingerprint or storage rule is wrong. Most bugs come from small choices that look harmless during testing and fail under real retry traffic.
A common one is hashing fields that change on every retry. If your hash includes a timestamp, trace ID, random nonce, or request receipt time, the same business action gets a different idempotency value each time. The user clicks "Pay" once, the client retries, and your server thinks it got two separate requests.
Local memory causes another quiet failure. It works on one laptop and breaks in production the moment you run two app instances, restart a pod, or deploy a new version. One server remembers the first request, another server does not, and both write. For payment idempotency in Go, you need shared storage that survives restarts.
Expiry settings also cause trouble. Teams often keep deduplication records for a few minutes because that feels safe and cheap. Then a slow mobile network, queue delay, or gateway timeout pushes the retry past that window. The second attempt arrives after the record expired, so the system creates the same charge or import again.
Order matters too. If you call the payment gateway before you reserve the idempotency record, two workers can race each other. Both hit the gateway, then both try to save the result. By then the damage is done. Reserve the idempotency record first, mark it in progress, then call the external system.
500 errors need extra care. A 500 from your app does not always mean "nothing happened." Your code may return an error after the payment provider already accepted the charge or after the database committed the row. If you treat every 500 as safe to retry, duplicate request handling fails right where it matters most.
A safer rule looks like this:
- Build the deduplication value from stable business fields only.
- Store records in shared, durable storage.
- Keep them long enough for the slowest realistic retry.
- Reserve the record before side effects start.
- After a 500, check whether the first attempt already finished before retrying.
That last step saves a lot of pain in sync jobs too. If an import worker crashes after writing row 842 out of 1,000, a blind retry can write row 842 twice unless the job can ask, "Did I already do this exact write?"
Quick checks before you ship
Even with solid Go idempotency libraries, small gaps still create duplicate writes. Test the flow with at least two app instances. If instance A handles the first request and instance B gets the retry, both must read and write through one shared store. A local map works in a demo. It fails the moment you scale.
Keep the format of the idempotency key stable across every client. If your mobile app sends one shape and your web app sends another, one action can turn into two records. Pick one format, document it, and reject bad keys early. Boring rules work better than clever ones.
The replay path should match the original result exactly. If the first call returned 201 with a JSON body, the second call should return that same 201 and that same body. Do not switch to 200, and do not add a note that says the response came from cache. Small differences like that break callers and hide bugs.
Before release, check these points:
- Every app instance uses one shared store for idempotency records.
- Every client builds the same idempotency key for the same action.
- A replay returns the same status code and response body as the first success.
- Your metrics count hits, misses, locks, and expiries.
- A scheduled cleanup job removes old records before the table grows out of control.
Metrics tell you where the flow drifts. A jump in misses often means one client changed how it builds keys. Rising lock counts can mean slow handlers or workers that never finish. Expiry numbers tell you whether your cleanup job runs on schedule.
One last test catches a lot: send 20 identical requests at once. You want one write in storage and 20 matching responses. If you get anything else, do not ship yet.
What to do next
Start with the endpoint that costs the most when it runs twice. For many teams, that is "create payment", "create invoice", or "import record". Fix one painful path first instead of trying to make every handler perfect at once.
Keep the first version plain. Add one store that saves an operation ID, the request fingerprint, the status, and the final response. That single step does more than adding three middleware packages and hoping they agree. Some Go idempotency libraries can help with headers, locks, or cache wrappers, but the store is the part that decides whether a retry returns the first answer or writes again.
Then try to break it on purpose. Send the same request twice. Kill the worker after it writes to the database but before it answers. Force a client timeout and retry while the first call still runs. Ask someone on your team to double-click the submit button five times. These tests are simple, and they catch the bugs that usually create duplicate charges or duplicate imports.
A short checklist keeps the work focused:
- pick one endpoint with real business cost
- store the operation state before side effects
- replay the saved response for the same request
- test timeout, retry, restart, and concurrent submit paths
Sync jobs need the same treatment. A restarted importer should see "already processed" and move on. It should not guess.
If you want an outside review, Oleg Sotnikov can help as a Fractional CTO. He works on API design, lean infrastructure, and AI-augmented development setups, so he can review the request flow and the production behavior together.
Start with one endpoint this week. A small table with a unique constraint and a saved response beats a clever design that still lets two charges through.


