Go context deadlines for HTTP, gRPC, and Postgres calls
Go context deadlines help you cap request time across HTTP, gRPC, and Postgres so slow clients or dependencies do not stall your service.
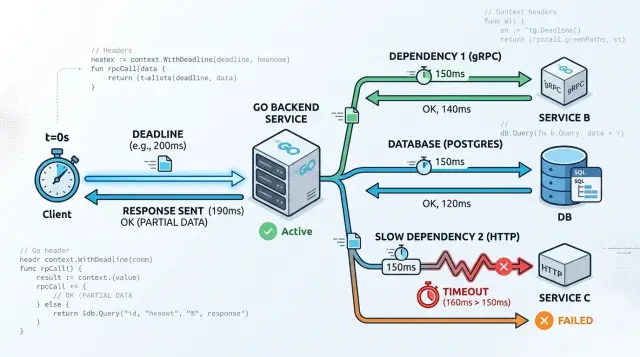
Table of Contents
Why slow requests pile up
One slow downstream call can turn a healthy service into a waiting room. A request that should finish in 120 ms can sit for 8 or 10 seconds if one HTTP call, gRPC method, or Postgres query hangs.
When requests finish fast, Go cleans up quickly. The handler returns, the goroutine stops doing work, the client socket closes, and any DB connection goes back into the pool.
A stalled dependency changes that. The goroutine keeps waiting on network I/O. The socket stays open. The DB connection may stay checked out. Nothing looks dramatic at first, but the service keeps stacking half-finished requests on top of each other.
Canceled clients make this worse. A user closes the browser tab or a mobile app gives up after 2 seconds, but your server may still be running the same work in the background. If the cancel signal does not reach every step, the server keeps calling other services and waiting for results nobody needs.
That is how pileups start:
- Goroutines sit blocked instead of serving new work
- Outbound sockets stay busy longer than expected
- DB connections stay occupied, so fresh queries wait in line
- Retries and duplicate requests add even more pressure
A fast request path hides the problem until traffic rises. Under light load, one slow call feels harmless. Under steady traffic, 50 slow calls can hold 50 goroutines, dozens of sockets, and most of the database pool. Then even simple requests start timing out because they cannot get resources in time.
This is why Go context deadlines matter so much. They do not make a slow dependency fast, but they stop one bad call from holding the whole service hostage. The goal is simple: if the client is gone, or the request has used up its time budget, the work should stop everywhere, not just at the edge.
What a deadline does in Go
A Go context carries a stop signal through your code. It can also carry a deadline, which is the exact time when work must stop. This is how Go context deadlines keep one slow step from holding the whole request open.
A timeout is just a shorter way to set that stop time. If you say "stop after 200 milliseconds," Go turns that into a deadline under the hood. Cancellation means you stop early for some other reason, such as when the client disconnects, the server shuts down, or an earlier step already failed.
context.WithTimeout fits cases where you know the budget as a duration from now. A handler might give an outbound HTTP call 300 milliseconds, no matter when the request started. context.WithDeadline fits cases where you already know the exact end time and want every child call to respect it.
Keep one parent context for each incoming request. In an HTTP handler, that usually starts with r.Context(). In gRPC, it starts with the request context that the server gives you. Every downstream call should derive from that parent, not from context.Background().
If you switch to context.Background() in the middle, you cut the chain. The user may leave, the server may time out, but your database query or remote call can keep running anyway. That is how slow clients pile up and waste memory, worker time, and connections.
When work no longer matters, stop fast. Check ctx.Done() in loops, before retries, and before starting expensive work. If the context is already finished, return ctx.Err() right away.
In practice, that error is usually one of two values:
context.DeadlineExceededwhen time ran outcontext.Canceledwhen someone stopped the work early
That quick return matters more than many teams think. If a browser tab closes, there is no reason to keep rendering a report, waiting on gRPC, or running a Postgres query for a response nobody will read.
Build one request budget from the edge
Start the clock at the public handler. If a request gets 2 seconds at the edge, every function under it needs to share that same limit. Do not let helpers create fresh timeouts as they go. A request that should die in 2 seconds can quietly sit around for much longer if each layer resets the timer.
Leave a small reserve for the work at the end. Writing the response, flushing logs, and closing resources still takes time. If your full budget is 2,000 ms, holding back 150 to 250 ms is usually a sane move.
A simple split might look like this:
- 2,000 ms total from the handler
- 700 ms for one outbound HTTP call
- 500 ms for one gRPC call
- 400 ms for Postgres
- 200 ms kept in reserve
The numbers will change by service, but one thing should not change: child operations get less time than the parent, never more. With Go context deadlines, the parent request tells every downstream call how much time is left.
Pass ctx through function arguments all the way down. func loadAccount(ctx context.Context, id string) is easy to read and hard to misuse. Global state makes deadlines easy to forget, and hidden request state gets messy fast.
Check the remaining budget before you start extra work. If only 80 ms are left, skip optional enrichments, background-like side work, or a second dependency call that probably will not finish. It is better to return a smaller result quickly than to push the whole request past its limit.
Log the remaining time when the request branches. For example, log it before a DB query, before an HTTP call, and before any fan-out work. Those numbers show whether your budget is realistic. They also make one common problem obvious: an early slow call can eat most of the budget and leave every later step with no chance to succeed.
Pass deadlines into HTTP calls
An outbound HTTP call should use the same clock as the incoming request. If your handler has 800 ms left, the next service should not get 30 seconds by accident.
Create the request with http.NewRequestWithContext. That ties DNS lookup, connect, writing the request, waiting for headers, and reading the body to the request budget.
transport := &http.Transport{
ResponseHeaderTimeout: 500 * time.Millisecond,
DialContext: (&net.Dialer{
Timeout: 200 * time.Millisecond,
}).DialContext,
TLSHandshakeTimeout: 200 * time.Millisecond,
}
client := &http.Client{
Transport: transport,
}
req, err := http.NewRequestWithContext(ctx, http.MethodGet, upstreamURL, nil)
if err != nil {
return err
}
resp, err := client.Do(req)
if err != nil {
return err
}
defer resp.Body.Close()
That split matters. The context sets the total budget. The transport timeouts stop a call from hanging in one network step, such as a slow connect or a server that accepts the socket but never sends headers.
http.Client.Timeout often causes trouble when you already use contexts. It wraps the whole exchange with its own timer, which can fire at a different moment than your request budget. That makes errors harder to read and can cut off a response body while your context still has time left. In most services, let the context own the end-to-end deadline, and use transport settings for the network phases.
A client disconnect and an upstream slowdown are not the same failure. If the browser or caller goes away, r.Context() is canceled. Stop work fast and do not retry. If your upstream call times out while the client is still connected, that usually means the dependency is slow. Log those cases separately. They point to different fixes.
Always close the response body, even when the status code is 500 or you plan to ignore the body. If you skip Close, idle connections do not return to the pool, and slow leaks turn into connection pressure under load. That is how one bad dependency starts to drag the whole service down.
Carry deadlines through gRPC
When a gRPC handler gets a request, the clock has already started. Read the deadline from the incoming context and treat it as the total budget for everything your handler does after that.
If you call another gRPC service, pass the same ctx downstream. That keeps one bad dependency from stretching the whole request past the client's limit. It also makes Go context deadlines work the same way across service boundaries instead of stopping at the first hop.
Creating a brand new timeout for each downstream call is a common bug. A request that should die after 800 ms can quietly run for 800 ms per retry, per dependency. That is how slow clients pile up. Retries need to live inside the original budget.
A simple pattern works well:
- check whether the incoming context already has a deadline
- pass that exact context into every downstream RPC
- retry only if enough time remains for one more useful attempt
- skip fan-out calls when the remaining budget is too small
The last point matters more than people think. If only 20 ms remain, a fan-out call to three services will probably fail three times and add noise to your logs. Return a partial result, use a fallback, or stop early. A fast, honest failure is better than extra load.
You should also record timeout outcomes in a way people can read quickly. codes.DeadlineExceeded means the clock ran out. codes.Canceled usually means the caller gave up or the parent request ended. Log the RPC method, the downstream service, and how much time remained when the call started. That makes it much easier to see whether the problem sits in your service or farther down the chain.
A small example: your API gets 1 second total. The handler spends 150 ms on auth, then calls a profile service and a billing service. If the profile call takes 700 ms, the billing call should see the tiny remaining budget and either skip work or fail fast. It should not start with a fresh 1 second timer.
Stop Postgres work on time
A request that times out in 2 seconds should not leave a 30-second SQL query running in Postgres. If it does, that query still holds a connection, may keep locks open, and can block fresh work behind it. That is how one slow path turns into a pool problem.
Use the context-aware database calls every time: QueryContext, ExecContext, and BeginTx with the same ctx that came from the request. That lets Go context deadlines reach the database layer instead of stopping at your handler.
rows, err := db.QueryContext(ctx, q, args...)
_, err = db.ExecContext(ctx, stmt, args...)
tx, err := db.BeginTx(ctx, nil)
When the context expires, Postgres can stop the work instead of finishing a query nobody needs anymore. That matters most during spikes. A few stuck queries can eat the whole pool, and then even fast requests wait for a free connection.
Transactions need extra care. Keep them short. Do the minimum work inside them, then commit or roll back right away. If you open a transaction, call another service, then come back to update rows, you increase the chance that a canceled request leaves locks around longer than needed.
Server-side limits help too. A statement timeout gives you a second brake in case app code misses something. Many teams set a default timeout for risky queries or use SET LOCAL statement_timeout inside a transaction. Keep that limit a bit lower than the full request budget, or at least close to it, so the database fails fast.
During testing, watch more than error logs. Check:
- active connections in the pool
- wait time for a free connection
- count of canceled queries
- transaction duration under load
A simple slow-query test tells you a lot. Fire requests that trigger a delayed query, cancel half of them, and watch whether the pool recovers in seconds or stays pinned. If it stays pinned, your timeout chain still has a gap.
A simple request flow example
Imagine an API endpoint called /quote. One request comes in, the handler asks a pricing service over gRPC for the latest number, and then it writes a small audit record to Postgres.
The full request gets 800 ms. Inside that budget, the pricing call gets 300 ms, and the SQL query gets 150 ms. In Go, child contexts cannot outlive the parent, so each step stays inside the same clock.
func (s *Server) Quote(w http.ResponseWriter, r *http.Request) {
reqCtx, cancel := context.WithTimeout(r.Context(), 800*time.Millisecond)
defer cancel()
priceCtx, cancelPrice := context.WithTimeout(reqCtx, 300*time.Millisecond)
price, err := s.pricing.GetPrice(priceCtx, &pb.PriceRequest{})
cancelPrice()
if err != nil {
http.Error(w, "pricing service timed out", http.StatusGatewayTimeout)
return
}
dbCtx, cancelDB := context.WithTimeout(reqCtx, 150*time.Millisecond)
_, err = s.db.ExecContext(dbCtx, `insert into quote_audit(price) values($1)`, price.Value)
cancelDB()
if err != nil {
http.Error(w, "database write timed out", http.StatusServiceUnavailable)
return
}
}
On a healthy day, the pricing service might answer in 90 ms and Postgres might finish in 40 ms. The whole request ends well under the 800 ms budget.
Now change one thing. The pricing service stalls for 2 seconds.
The handler does not wait 2 seconds. The gRPC call hits its 300 ms deadline, Go cancels the context, and the request returns a 504 with a plain message such as "pricing service timed out". The outer handler still has time left, but it stops work because the dependency already failed.
That early stop protects the rest of the service. The code never reaches ExecContext, so it never grabs a Postgres connection. Your DB pool stays free for requests that still have a chance to succeed.
If a request does reach Postgres and the query drags past 150 ms, ExecContext cancels it on time. The query stops, the connection goes back to the pool, and the handler returns a clear error instead of hanging until the client gives up.
Mistakes that break timeout chains
Most timeout bugs come from code that quietly cuts the original context in half. You start with a 2 second budget at the edge, but one helper, one retry loop, or one generic error wrapper turns that budget into guesswork.
A common mistake is creating context.Background() inside a helper. That helper no longer knows when the client gave up, so its HTTP call, gRPC request, or Postgres query can keep running long after the user is gone. In Go context deadlines only work if every layer accepts ctx and passes the same chain forward.
Another problem is resetting the timeout at each layer. A handler gets 2 seconds, then the service adds another 2, then the database layer adds 2 more. On paper every call has a timeout. In practice the whole request can drag on far past the limit you meant to enforce.
Retries cause trouble too. If ctx.Err() already says context deadline exceeded or context canceled, stop there. Retrying after the budget ended does not rescue the request. It just adds more work to a system that is already under pressure.
Logs often make this worse. If every timeout becomes a generic 500, you lose the reason the request failed. You want logs that say whether the client canceled the request, your own deadline expired, or an upstream dependency timed out first. That detail saves a lot of time when you debug slow paths.
Tests get skipped in the exact place where bugs hide. Many teams test happy paths and a few slow dependencies, but they never test canceled client connections. That leaves a blind spot: the browser closes, the phone app switches networks, or the proxy gives up, and your service still keeps the database busy.
A small checklist helps:
- Accept
ctxin every helper that does I/O - Derive shorter child deadlines only when you need them
- Check
ctx.Err()before each retry - Log timeout and cancel errors with the real cause
- Add tests that cancel the client request mid-flight
If one slow partner service can still keep your goroutines, DB sessions, or workers busy after the caller left, the timeout chain is broken somewhere.
Quick checks before rollout
Most timeout bugs come from one missing ctx, not from the timeout value itself. A service can pass normal tests and still jam up when one downstream call slows down.
Run these checks in staging with added delay, or in production behind a safe flag. You want proof that one stuck dependency cannot hold the whole service open.
- Start one request budget at every public entry point. Each HTTP handler and gRPC method should begin with a parent context that has a deadline. If an incoming request already has a shorter deadline, keep the shorter one.
- Pass the same
ctxthrough every outbound call. Your HTTP clients, gRPC clients, and Postgres queries should all use it directly. One helper that swaps incontext.Background()can break the chain. - Separate canceled requests from timed out requests in logs.
context.Canceledusually means the client left early.context.DeadlineExceededusually means your code, database, or another service took too long. - Watch pools while you force slowness. Hold a Postgres query open, delay an HTTP dependency, or slow a gRPC server. Connection counts, pool wait time, goroutines, and latency should rise a little and then level off, not keep climbing.
- Fire alerts before saturation starts. Alert on timeout rate, pool waits, queue growth, and rising in flight requests before CPU is pinned or the service stops answering.
A small test tells you a lot. Set one dependency to sleep for 10 seconds, give the request a 2 second budget, and send traffic for a few minutes. If Go context deadlines are wired correctly, callers should fail fast, Postgres work should stop, and the service should keep taking new requests.
If that test leaves busy database connections behind, growing goroutine counts, or a wall of identical timeout logs, fix that before rollout. Those are early signs that slow clients will pile up under real traffic.
Next steps for your service
Pick one request path that hurts when it slows down. A good first target is often a handler that calls an external HTTP API, then a gRPC service, then Postgres. Trace the full timeout budget from the edge to the last query and write down the numbers. If the client gets 2 seconds, every downstream call needs a smaller slice of that time.
Do that on one path before you touch the whole codebase. Teams often try to add Go context deadlines everywhere at once, then spend a week guessing which timeout fired first. One path gives you clean data and fewer surprises.
A small rollout usually works best:
- Set one request budget at the HTTP edge and pass the same context through every call.
- Add tests that force a slow HTTP dependency, a slow gRPC call, and a slow SQL query.
- Check that each layer stops work early and returns a clear error.
- Watch logs, connection pool stats, and latency after each change.
The tests matter more than most teams expect. A timeout chain can look fine in code and still fail in production because one helper uses context.Background(), one client has its own longer timeout, or one query ignores cancellation until it hits the database. Slow tests catch that fast.
When you review results, look for two things. First, did tail latency drop when one dependency got stuck? Second, did your service free resources fast enough? Postgres pool wait time, open connections, goroutine count, and upstream retry noise usually tell the story.
Keep the logs plain. Record the request deadline, the remaining budget before each outbound call, and the error that came back. That is often enough to spot where time disappears.
If your team wants a second set of eyes, Oleg Sotnikov provides Fractional CTO support for Go services, infrastructure, and AI-augmented engineering. His background includes running production systems with lean infrastructure, high uptime, and practical automation, so this kind of timeout cleanup fits the work he already does.
Once one hot path behaves well under pressure, copy the same pattern to the next busiest path. That is usually where the real win shows up.


