Go caching libraries for fast reads and fresh data
Compare Go caching libraries for local memory, Redis, and invalidation helpers so your app reads faster without serving old data.
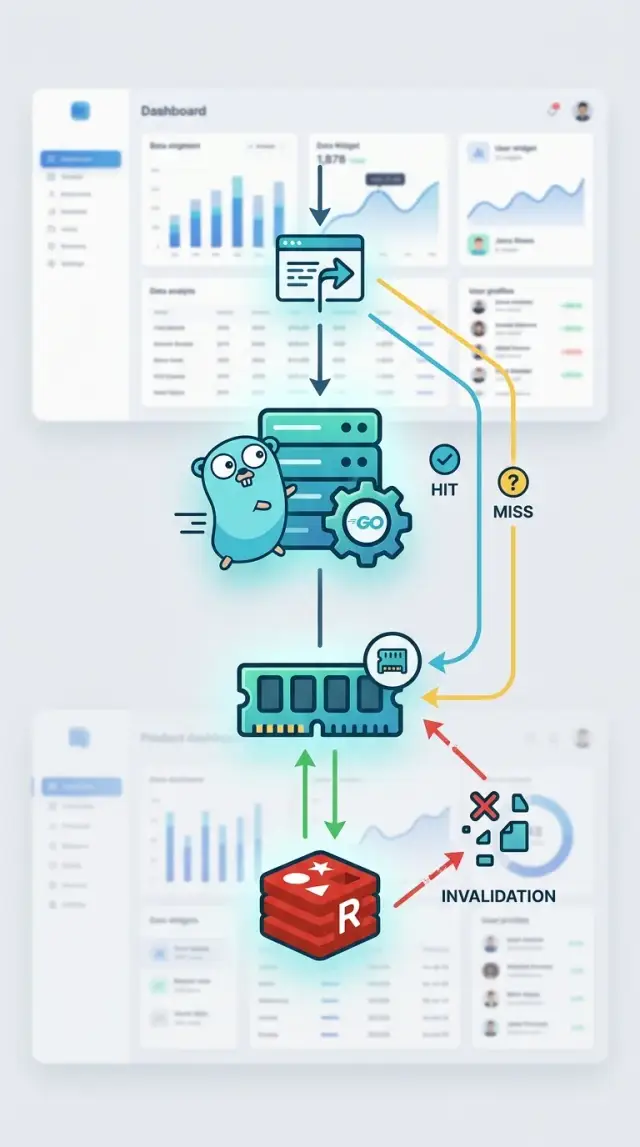
Table of Contents
Why cached reads go wrong
Traffic is rarely spread evenly. A product may have 200 screens or endpoints, but a handful do most of the work. Think of a pricing page during a launch, a product detail API during a sale, or a dashboard widget that every logged-in user refreshes all day. One query can look harmless in tests and still become expensive when thousands of people ask for the same data at once.
That is why teams reach for cache layers so quickly. The problem is not speed alone. The moment you cache a value, you create a second copy of the truth. If that copy stays old for even a few minutes, users can see the wrong price, the wrong stock count, or the wrong account setting. People forgive a slow page once. They do not forgive being charged the wrong amount.
The failure usually starts with good intentions. A team sees database load climb, adds a cache in front of the hot query, and promises to sort out freshness later. Later often never comes. The app gets faster, everyone relaxes, and stale data quietly sits in production until a promotion, config change, or inventory update exposes it.
A few patterns cause most of the pain:
- One busy page or API route gets hammered while the rest of the app stays calm.
- The database handles single requests fine, but repeated reads pile up under load.
- Cached values live longer than the business can tolerate.
- Different app instances keep different copies and drift apart.
- Expired entries trigger a burst of identical requests at the same time.
This gets worse when the data changes unevenly. A blog post can stay cached for hours with little risk. Prices, permissions, feature flags, and stock numbers cannot. Those values shape user decisions, so even a short delay creates support tickets, refunds, and a trust problem.
Caching is not risky because it is complex. It is risky because it looks simple. Reading from a cache takes one line. Deciding when that data stops being safe is the part teams often skip.
When an in-memory cache fits
An in-memory cache works best when one Go service reads the same small set of data again and again. The data should be cheap to rebuild, and each app instance can keep its own copy without causing trouble.
That usually means hot lookups such as parsed config files, feature flags, plan limits, permission maps, or small reference tables. If your API checks the same values on every request, keeping them in RAM can cut a few milliseconds each time and remove a lot of database noise.
This is often the simplest option among Go caching libraries because there is no network hop and no extra service to run. If the process restarts, the cache disappears too, but that is fine when the service can refill it in a few seconds.
A good example is a Go service that routes AI requests and reads model settings, prompt templates, or per-team limits on every call. Those objects are small, read-heavy, and easy to load again from the source of truth.
The library choice depends on how much data you keep and how you want eviction to work.
- Ristretto fits busy services with lots of repeated reads and a cache that must decide what stays under pressure.
- BigCache is a good pick when you store many entries and want to keep memory overhead low.
- Freecache makes sense when you want a fixed memory cap and simple behavior.
Short TTLs matter when values change often. A feature flag or pricing rule that may change during the day should probably live for 30 to 60 seconds, not several hours. Short TTLs limit stale reads without giving up most of the speed gain.
One warning: this setup fits best inside a single service boundary. If five app instances all need the exact same value at the exact same moment, each one will still keep its own cache copy. That is fine for many product settings and repeated lookups. It is a poor fit for shared state that must stay tightly synced across nodes.
When Redis makes more sense
Redis starts to win when your Go app runs on more than one instance. An in-memory cache in Go is fast, but each process keeps its own copy. That is fine on one server. It gets messy when six API instances all cache the same customer record and only one of them sees an update first.
A shared cache fixes that split view. Every app instance can read the same cached value, use the same TTL, and drop the same entry when data changes. You still need to think about freshness, but you stop fighting cache drift between servers.
Good fits for Redis
Redis is a better choice when the cached data needs to live outside a single process. Common examples include:
- session data for logged-in users
- rate limit counters shared across all API nodes
- expensive query results that take seconds to build
- short-lived feature flags or tenant settings used by many workers
This matters even more when traffic jumps around. A load balancer might send one user to app instance A on one request and instance D on the next. With local memory only, those requests can behave differently.
For Redis clients for Go, most teams end up choosing go-redis or rueidis. go-redis is widely used and easy to pick up. rueidis is a strong option if you want very high throughput and low overhead. Either one gives you networked cache access, which is the real shift here.
A realistic product case: a SaaS app stores account limits, billing status, and dashboard summaries in cache. If those values sit in local memory, one rollout or pod restart wipes part of the cache while other instances keep old values. Redis gives the whole fleet one shared place to read and refresh them.
Plan the boring parts early. Redis feels simple until connection pools are too small, timeouts are too loose, or memory fills up faster than expected. Decide up front:
- how many connections each service can open
- how long reads and writes may wait
- which eviction policy matches your data
- how large cached values are allowed to get
Those choices affect latency more than the client library name. If you expect several app instances, background workers, or jobs that must agree on the same cached state, Redis is usually the safer default.
How invalidation helpers reduce stale reads
Most stale cache bugs come from doing too much too early. A simple cache-aside flow works well on read paths that are easy to understand: check the cache, load from the database on a miss, then store the result with a short TTL. That keeps the logic plain, and plain code breaks less often.
Many Go caching libraries give you storage and TTLs, but freshness usually depends on the small helpers around them. The first helper to add is singleflight in Go. If 200 requests miss the same item at once, singleflight lets one request fetch it while the rest wait for that result. Your database gets one query instead of 200, and users still get a fast response.
A product admin panel shows why this matters. Say an admin updates a plan price from $29 to $39. If the app only waits for TTL expiry, some users will still see the old price for a minute or two. That is enough to cause support tickets.
The safer pattern is to publish a change event when the admin saves the edit. The API that handles the update already knows what changed, so it can send a small event like "plan:123 updated". Cache workers or app instances can react right away and delete or refresh that item. That is a practical form of cache invalidation in Go because it moves the cache as soon as the source of truth changes.
Versioned keys help when the object shape changes, not just the data. If you cached plan:123 yesterday as one JSON structure and today the code expects a different one, old entries can break reads in odd ways. A prefix like v3:plan:123 avoids that mess. New code reads new keys. Old keys expire on their own.
Prefix or tag deletes sound neat, but they get expensive fast. Deleting "all plans for tenant 42" can touch a lot of entries, especially in Redis or a busy in-memory cache in Go. Use broad deletes only after you measure their cost under real traffic.
A good order is simple:
- Use cache-aside on calm, read-heavy endpoints.
- Add singleflight before traffic spikes force your hand.
- Emit change events from every write path.
- Version keys when your payload format changes.
- Measure bulk invalidation before you rely on it.
That stack stays boring, and boring caches usually stay fresh.
Pick a cache strategy step by step
Start with the reads that cost you the most. Look at slow pages, busy API endpoints, and database queries that run again and again. If one product page gets 10,000 reads a day and changes twice, that is a better cache target than an admin screen that five people use.
Then label each read by how it behaves. Some data stays stable for hours, like a public pricing page or feature list. Some changes often, like inventory, balances, or order status. Some is user-specific, which means a shared cache can leak the wrong data if you get the cache key wrong.
A simple way to sort them is this:
- Stable: good for longer TTLs
- Fast-changing: short TTLs, or clear the cache on every write
- User-specific: cache only with careful keys, or skip it at first
- Expensive to build: stronger reason to cache
- Sensitive or easy to get wrong: stricter rules, more logging
Do not start with three cache layers. One layer is usually enough for the first version. For many teams, that means an in-memory cache in Go for cheap, repeated reads inside one service. If several app instances need the same cached data, Redis often makes more sense.
Set TTLs from business rules, not guesses. Ask a plain question: "How wrong can this data be, and for how long?" A marketing page can stay cached for 30 minutes. A seat count for a live booking flow probably cannot.
You also need one clear owner for invalidation. After a write, who clears or refreshes the cached item? Put that rule next to the write path, not in somebody's head. If a product price changes in the admin panel, that same update flow should clear the cached price.
Last, measure the result. Log hit rate, miss rate, and reports of stale reads. If hit rate stays low, the cache may not help much. If stale read reports go up, your rules are too loose. Good Go caching libraries save database work, but only when you keep the rules simple enough to trust.
A simple product example
Picture a SaaS billing page for one customer account. It needs three things on every load: the current plan, this month's usage, and the latest invoices. These data types change at different speeds, so they should not share one cache rule.
The plan is a good fit for an in-memory cache in Go. A plan record is small, and most accounts do not change plans often. Each app worker can keep plan limits in local memory for a few minutes and read them in microseconds.
Usage is different. If several workers record API calls, seats, or storage updates at the same time, local memory on one worker will drift from the others. Redis makes more sense because every worker reads and updates the same counters.
That matters on busy accounts. If a customer sends 5,000 requests in ten minutes, the billing page should still show usage that is close to current. Shared counters in Redis handle that far better than per-worker memory.
Invoices usually sit in the middle. New invoices do not appear every second, but billing data still needs care. A short cache can help, but many teams simply read invoices from the database and cache only the list for a brief period.
Now look at a plan upgrade. An admin changes an account from Starter to Pro, which raises limits right away. If the old plan stays in cache until a timer expires, the customer may see the wrong limits and hit errors they should not get.
Good cache invalidation in Go is simple here: clear that account's plan cache as part of the admin update flow. Do it at the same moment you write the new plan. Event-based clearing is safer than waiting for a five-minute TTL.
singleflight in Go helps when traffic spikes. If 40 requests hit the same billing page after a user opens a few tabs, you do not want 40 identical reads for the same account. One request fetches fresh data, and the others reuse that result.
This split is practical and easy to reason about. Keep slow-changing plan details in local memory. Put shared usage counters in Redis. Clear caches when the business event happens, not later. That is where Go caching libraries save time without making stale data a daily problem.
Mistakes that cause stale data
One common mistake is caching a whole response when only one small field changes often. A product page might include a name, photos, specs, price, and stock count. If stock updates every minute but the full response stays in cache for ten minutes, shoppers see the wrong number even though most of the page was safe to cache.
Split data by how often it changes. Cache product details longer, then fetch stock or price with a shorter TTL or a refresh on write. That small choice prevents a lot of confusing bugs.
Long TTLs also trick teams because load tests make them look great. Reads get faster, the database gets quiet, and the graphs look clean. Then real users start changing plans, prices, permissions, or inventory, and the cache keeps serving old data long after the write finished.
Write paths cause more trouble than reads. Teams usually remember the main API update, but forget the admin panel, CSV imports, background jobs, billing syncs, or support tools. If any of those paths skip cache deletes or refreshes, stale data slips in through the side door.
Shared cache keys create another mess. If you cache dashboard data under a broad key like user_profile and the response includes role, region, or feature flags, one user's version can leak into another user's request. That bug is easy to miss in testing and ugly in production.
Cache keys need to match the real shape of the data. If a response depends on user ID, account ID, locale, or plan, the key should include it. If the data should stay private, do not store it under a shared key.
Redis adds its own failure mode. Many teams assume Redis is always fast, so they skip timeouts and fallback rules. When Redis slows down, every request waits on it, retries pile up, and the cache turns into the outage.
Set short timeouts and decide what happens on a miss, a timeout, or a partial failure. A plain fallback to the database is usually better than hanging the request or serving bad data.
Most stale reads do not come from Go itself. They come from simple choices that looked harmless in testing. Good Go caching libraries help, but fresh data depends on careful invalidation, scoped cache keys, and strict timeout rules.
Quick checks before rollout
A cache that feels fast in a test can still confuse real users. Before you ship, write down one plain answer for every cached value: where does the true value live? If your team cannot name one database table, service, or API as the source of truth, stale reads will turn into long debugging sessions.
Writes need one path too. When a user changes a plan, profile, stock count, or feature flag, one part of the app should update the record and clear or refresh the cache entry. If several handlers can change the same value in different ways, one of them will miss the cache step.
Redis failure should slow the app down, not take it offline. Decide that behavior before rollout. Many teams fall back to the database, keep a small in-memory cache in Go for hot reads, or skip cache reads until Redis recovers. Login, checkout, and account updates should still work.
Metrics keep this honest. Even good Go caching libraries can hide trouble if nobody watches the numbers.
- Track hit rate to see whether the cache pays for its added code.
- Track p95 latency to catch slow reads before users complain.
- Track cache errors for get, set, and delete calls.
- Track stale-read reports by request, user, or endpoint.
Support also needs a simple explanation path. If a customer says, "I changed my plan and still saw the old one," someone on the team should be able to check logs and explain the sequence in plain words. For example: the write reached the database, the app failed to clear one cache entry, one request read old data, and the next refresh fixed it. If support cannot explain that story, rollout is early.
One last test catches a lot: change a value, then read it from two app instances in a row. That small check often finds weak spots in local caches, Redis clients for Go, and cache invalidation in Go before customers do.
What to do next
Start with one hot endpoint. A product page, exchange rate lookup, or account summary is enough. Add caching to that one read path, then compare p50 and p95 latency, database queries, and error rate before and after.
If the cache cuts read time by 60 ms and drops database load by 30 percent, you have a clear win. If stale data shows up, you can fix one narrow case instead of untangling the whole app.
Write the rules down while the test is still small. Keep one short note with the TTL, invalidation trigger, and fallback behavior for each cached value. If the cache misses, do you fetch from the database and repopulate it? If Redis is slow, do you serve the last known value for 30 seconds or bypass the cache?
A simple rollout checklist helps:
- Set a memory cap for your in-memory cache in Go and watch evictions.
- Estimate Redis costs with production-like traffic, not local tests.
- Add metrics for hit rate, miss rate, stale reads, and cache warm-up.
- If cold misses pile up, use singleflight in Go to stop duplicate fetches.
Traffic grows faster than most teams expect. A cache that feels small in staging can eat gigabytes in production once popular records pile up, and a Redis bill can climb for boring reasons like memory, replicas, and cross-zone traffic.
Use a case that affects real users. If the same product record gets read thousands of times an hour but changes twice a day, cache that read and invalidate it on update. That pattern is easier to reason about than trying to cache everything at once.
If your team wants a second opinion, Oleg Sotnikov can review cache design, infra tradeoffs, and rollout steps as a Fractional CTO. That kind of review is often cheaper than fixing a bad cache after it reaches production.


