Go resilience libraries for APIs: a practical starter stack
Go resilience libraries for APIs help you add rate limits, retries, and circuit breakers fast. Compare solid packages and build a safe starter stack.
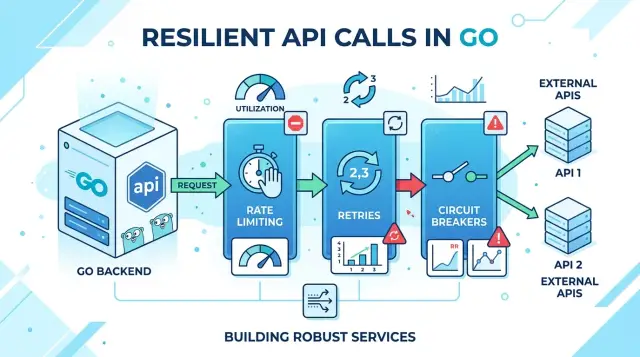
Table of Contents
What goes wrong when clients or APIs get noisy
A service can look fine in code review and still fail in production. Most of the time, the trouble starts with traffic patterns, not business logic.
One chatty client, one burst from a cron job, or one upstream API that slows down for 30 seconds can push a calm system into a queueing mess. A single customer can fill your worker pool much faster than most teams expect. If they open too many connections or send requests in tight loops, their traffic can crowd out everyone else. Other users end up waiting behind work that should have been paced, delayed, or rejected early.
Slow upstreams create a different kind of pileup. Your handlers sit on network calls, goroutines stay busy, sockets stay open, and memory use climbs. Nothing looks obviously broken at first. Requests just get slower until users start seeing timeouts.
Retries often make the incident worse. A failed request triggers another request, then another. A service that already struggles at 100 calls per second can suddenly see 300 or 500 because clients retry at the same time.
Picture a simple Go service that calls a payment API, an email API, and a CRM. The payment API gets slow, your service waits, clients retry, and the worker pool fills. Soon even the email and CRM calls start timing out because the process runs out of breathing room.
That is why users can hit timeouts even when your business logic is correct. The code does the right thing. It just does it too late, with too many requests in flight, against dependencies that already need less pressure.
What rate limiting, retries, and breakers solve
When an API or client gets noisy, failures rarely begin with one dramatic crash. Small delays pile up first. Queues grow, callers retry too much, and a weak upstream gets hit even harder.
These three tools stop that chain reaction at different points.
Rate limiting caps request flow before queues get ugly. It protects your workers, connection pools, and upstream APIs from one bursty client or a short traffic spike.
Retries handle brief failures such as dropped connections, short DNS issues, or a single 502 from a gateway. They give a request another chance when the problem is likely to disappear quickly.
Circuit breakers watch for repeated failure. When a dependency keeps timing out or returning errors, the breaker opens and blocks more calls for a while instead of hammering a service that is already in trouble.
They overlap a little, but they do not replace each other. A retry will not fix an API that is down for ten minutes. A circuit breaker will not stop your own service from taking on too much work. A rate limit will not recover a request that failed once by bad luck.
Used together, they form a simple safety net. Rate limiting controls how much work enters the system. Retries smooth out brief network trouble. Circuit breakers stop waste when a dependency is clearly unhealthy.
Timeouts and context cancellation tie the whole setup together. A timeout puts a hard upper bound on waiting. Context cancellation tells every part of the request to stop when the caller leaves, so your service does not keep spending CPU time, memory, and outbound connections on work nobody wants anymore.
If your service calls a payment API and it slows down for 20 seconds, rate limiting keeps incoming traffic from flooding your app, retries can recover a few one off failures, and the breaker stops repeated calls once the payment API is plainly in trouble.
A small Go stack that covers most cases
You do not need a big framework to make outbound calls safer. In Go, the best default is usually the standard http.Client with a few small libraries around it. That keeps behavior easy to read, test, and replace later.
For in process limits, golang.org/x/time/rate is hard to beat. It handles bursts well, stays small, and fits neatly around handlers or client call paths. If one noisy user or job starts flooding requests, you can slow that path down before it drags everything else with it.
Retries need a different tool. cenkalti/backoff gives you flexible retry timing with exponential backoff, caps, and jitter. For plain HTTP calls, hashicorp/go-retryablehttp saves time because it already wraps an HTTP client and gives you retry hooks. That makes it easier to retry transport errors or 429 and 503 responses without scattering retry loops through the codebase.
Circuit breaking is the last guard. sony/gobreaker is a good fit when one dependency starts timing out or returning errors in waves. It is small, predictable, and easy to tune. When the failure rate climbs, it stops sending full traffic into a bad dependency and gives the upstream time to recover.
A simple starter stack looks like this:
- stdlib
http.Clientfor timeouts, transport, and connection reuse x/time/ratefor throttlingbackofforretryablehttpfor retriesgobreakeraround the weakest external dependency
That mix is enough for many teams building API integrations, internal services, or background workers. Each part does one job, and none of them forces a big rewrite.
Build the stack in this order
Start with failure boundaries, not retry code. If a request can hang forever, every layer after it adds pressure and makes the outage harder to read.
Set timeouts and context deadlines first. Give each request a total budget, then keep each outbound call inside that budget. If the caller has two seconds, one slow API should not consume all of it.
Then rate limit inbound traffic before you make outbound calls. Limits for each client work better than one global cap, because a single noisy customer should not slow everyone else down.
Add retries only for temporary failures. Timeouts, connection resets, 429 responses, and short bursts of 5xx errors are fair targets. Keep retries low and add jitter so clients do not all retry at once.
After that, put a circuit breaker around the dependency that fails often or stalls under load. When it opens, fail fast. A quick error is usually better than a queue of stuck goroutines.
Finally, log the decisions your code makes. Record retry attempts, open breaker events, and dropped requests from the limiter. Those signals tell you whether you have a bad client, a weak upstream, or a timeout that is too generous.
This order matters more than the exact library you choose. A breaker without deadlines still waits too long. Retries without limits can turn a small wobble into a spike.
A simple rule works well: reject extra work early, stop slow work quickly, and retry only when there is a good chance the next attempt will succeed.
Set limits that protect users and upstreams
A limit that is too tight annoys real users. A limit that is too loose lets one noisy client slow everyone else down. Good limits leave room for normal spikes, then cut off traffic before your app, database, or upstream API starts to wobble.
Start with burst size, not just requests per second. Many apps send traffic in clumps. A page load can trigger several calls at once, and a mobile app may reconnect and fire a short burst after weak signal. If a user usually makes two to five quick requests, a burst of one is too harsh. If a client suddenly sends 200, that is not a normal spike.
Use more than one limit when traffic comes from different places. A global cap protects your service as a whole, while limits for each tenant or IP stop one customer, bot, or bad script from taking the rest down. This matters even more when you call external services with strict quotas, because one tenant can burn the shared budget for everyone.
When you reject traffic, do it fast and clearly. Return a 429 with a short message and a retry hint if you have one. Do not let requests sit in a queue until they time out. Hanging feels like a bug. A clean 429 tells clients what happened and keeps your workers free for requests you can actually serve.
Put stricter limits around expensive paths. File uploads, report generation, and webhook fan out can eat CPU, memory, bandwidth, or third party quota much faster than simple reads. One rule set for normal endpoints and another for costly endpoints is usually enough.
After every change, watch queue length, tail latency such as p95 or p99, 429 rate, and upstream error rate. If queues grow or tail latency jumps, your limit may still be too generous. If 429s rise while the system stays quiet, you probably set the limit too low. The best setting is rarely the first one you pick.
Retry the right failures and stop fast on the rest
Retries help when a failure is brief. They make things worse when the request will never succeed. A good rule is simple: retry overload and network hiccups, but stop on bad input and auth problems.
In practice, retry 429, 502, 503, and short network errors such as connect timeouts, resets, and temporary DNS failures. Stop on 400, 401, 403, and validation errors, even if the server wraps them in a generic 4xx response.
Use exponential backoff with jitter so clients do not retry at the same moment. Start small, around 100 to 200 milliseconds, then double the wait for each attempt. Add a little randomness to every delay. That one detail prevents retry storms surprisingly well.
Set two limits, not one. Cap the number of attempts, and cap the total time you will spend retrying. Three attempts is often enough for user traffic. If the full retry budget is two seconds, stop when you hit two seconds even if you still have attempts left. Users care about the full wait, not how many times your code tried.
POST requests need extra care. GET is usually safe to retry. POST is not always safe because the first call may have succeeded even if your client never saw the response. If you retry a charge, an order, or a signup, you can create duplicates.
Retry POST only when you know the operation is idempotent. That usually means one of two things: the API accepts an idempotency key, or your own system can detect and ignore duplicates. If neither is true, fail fast and return a clear error.
For most Go services, this policy is enough: retry a few short lived failures, back off with jitter, and give up quickly on permanent ones.
Put circuit breakers around weak dependencies
A circuit breaker stops your service from hammering something that is already failing. It helps most with dependencies outside your control: payment gateways, email providers, fraud checks, or a slow internal service owned by another team. If one of those starts timing out, a breaker can stop a small problem from eating all your goroutines and request budget.
Trip the breaker when failure is persistent, not when one request gets unlucky. A simple rule is to open after five consecutive failures for low volume calls. For busy endpoints, error rate usually works better, such as opening if half of the last 20 calls fail. Pick one rule, watch it in production, then adjust.
Keep the open period short. Ten to thirty seconds is often enough to let an upstream recover without blocking traffic for too long. After that, let a small number of half open probe requests through. One or two probes is usually plenty. If they pass, close the breaker. If they fail, open it again quickly.
Fallbacks help only when they tell the truth. Return cached exchange rates, stale product data, or a simpler response when that still lets the user finish the task. Do not fake success for payments, identity checks, or writes that must happen exactly once.
Track breaker state like any other production signal. Count opens, half open probes, rejected calls, and recovery time. Put those events in logs and metrics so you can see whether the breaker helped or just hid a deeper issue.
Do not wrap every function. Use breakers around weak dependencies with a clear failure mode and real blast radius. A pure in process helper does not need one. Neither does a fast local call that already fails loudly and cheaply.
A simple example: one service, three external calls
Picture a SaaS app when a customer upgrades a plan. The request hits your Go service, and that service talks to Stripe to charge the card, an SMTP provider to send the receipt, and a customer webhook endpoint to notify other systems. These calls should not share the same rules. If you treat them the same, one slow dependency can drag down the whole request.
Stripe is the strict one. A payment call should use a short timeout and very few retries. If Stripe does not answer in time, fail fast and show the user a clear message. Waiting 20 seconds and retrying five times usually makes things worse. You risk duplicate work and a checkout page that feels broken.
Email is different. The user does not need to wait for SMTP. Put the email job on a queue and return the HTTP response first. Then let a worker retry with backoff in the background. If the mail server has a short outage, the worker can recover without slowing down the app.
Webhooks need the most protection. One noisy tenant can trigger hundreds of outbound calls in minutes after a bulk import or sync job. Put a rate limiter in front of the webhook client for each tenant so one customer cannot crowd out the rest. Then wrap the webhook sender in a circuit breaker. If one destination starts timing out or returning errors, the breaker opens and stops the flood.
A sensible starting point is simple. Stripe gets a two to three second timeout and at most one retry. SMTP runs through an async queue with several background retries. Webhooks get a limiter for each tenant plus a breaker on the client.
That split keeps user requests fast, protects upstream services, and stops one bad webhook target from burning through workers and connections.
Common mistakes that turn small failures into outages
Even with good libraries, bad defaults can still knock a service over. Most outages start small: one slow upstream, one bursty client, one timeout that lasts a bit too long. Your own protection code can turn that into a much bigger problem.
The most common mistake is stacked retries. If your HTTP client retries three times, your service layer retries three times, and a job runner retries again, one failed call can turn into nine or more requests. Under load, that becomes a traffic spike you created yourself. Retries need one owner. Every other layer should fail fast.
Teams also trip over shared limiters. If you put one rate limiter in front of unrelated traffic, a noisy path can block healthy requests. A login burst should not slow webhook delivery. A flaky partner API should not eat the budget for normal user traffic. Split traffic by route, caller, or dependency when the risk is different.
Circuit breakers can misfire at startup. A service boots, health checks fire, DNS is still warming up, and the breaker opens before real traffic even starts. Give the service a short warm up window or ignore startup probes when they do not match normal request flow.
Upstreams often tell you what to do next. If they send a Retry-After header and you ignore it, you hammer a struggling API at exactly the wrong time. Respect the delay, cap it, and move on when the wait is too long for your user.
DNS and TLS failures catch many teams off guard because they test only 500s and timeouts. Real systems also fail before the request reaches the server.
A safer default is simple: keep retries in one layer, scope limiters to the traffic they protect, give breakers a startup grace period, and test DNS, TLS, and connection errors before release. That small discipline prevents a lot of ugly nights.
Quick checks before you ship
A service can look fine in local testing and still fail fast under real traffic. Before release, check the guardrails around every outbound request, not just your happy path.
Start with timeouts. Every call to an external API should have one, even if the client library already has defaults. If one provider hangs for 30 seconds, that delay can spread through your whole service and tie up workers that should handle other users.
This pre ship checklist catches most bad surprises:
- Give every outbound call its own timeout, shorter than the total request deadline.
- Put a hard cap on every retry loop. Two or three tries is usually enough.
- Make every rate limiter return a clear error, or an HTTP
429for clients. - Export breaker state so you can see when it is open, closed, or half open.
- Run at least one load test that includes both traffic spikes and a partly failing upstream.
Retries need extra care. A retry without a cap can turn a small slowdown into a pileup. A retry with no delay or jitter can do the same thing even faster. If a dependency returns a clear client error, stop right there. Save retries for timeouts, temporary network errors, and a small set of 5xx responses.
Circuit breakers are easy to add and easy to ignore. Do not stop at whether the breaker opens. Make sure you can see when it opens, how long it stays open, and whether probe requests recover cleanly or fail again.
One test tells you a lot. Simulate ten times normal traffic for a few minutes while one upstream slows down and another returns intermittent 500s. If your service sheds load cleanly, caps retries, and keeps latency predictable, your starter stack is probably in good shape.
Next steps for your team
Pick one outbound client and one upstream API first. That gives you a safe place to prove the pattern before you touch every service. If the first rollout works, the rest of the team will copy it quickly.
Use that first pass to settle the basics: one rate limiter, one retry policy, one circuit breaker, and one place for metrics. Keep the code boring. The goal is to remove guesswork, not build a custom resilience framework.
A small rollout usually goes well when the team picks a client that already causes timeout pain, writes table tests for retry rules and breaker thresholds, ships behind a flag or to a small share of traffic first, and reviews dashboards after release to tune the numbers from real traffic.
Table tests matter more than many teams expect. They force clear rules like retry 429 and temporary network errors, but never retry a bad request. Do the same for the breaker. Decide how many failures trip it, how long it stays open, and what a successful recovery looks like.
After the staged rollout, check what actually changed. Look at timeout rate, upstream error rate, request latency, and how often retries or breaker opens happen. Real traffic will show edge cases that local tests miss. Some limits will feel too strict. Others will be too loose.
If you want a second pair of eyes on service boundaries, timeouts, or infrastructure defaults, Oleg Sotnikov at oleg.is does Fractional CTO work with startups and small teams. That kind of review can help you settle on shared patterns without turning reliability work into a long internal side project.
Frequently Asked Questions
Do I need rate limiting, retries, and a circuit breaker?
Use all three if your service talks to external APIs or deals with bursty clients. Rate limiting controls how much work enters, retries recover short failures, and a breaker stops calls to an upstream that keeps failing.
If you only add one thing, start with timeouts and request deadlines. They keep slow calls from tying up your whole service.
What should I add first in a Go service?
Start with timeouts and context deadlines. After that, add inbound rate limits, then small retries for temporary failures, and then a breaker around the weakest dependency.
That order keeps slow work from piling up before you add more logic.
Which Go libraries make a good starter stack?
A simple Go setup works well for most teams: http.Client for timeouts and connection reuse, golang.org/x/time/rate for throttling, cenkalti/backoff or hashicorp/go-retryablehttp for retries, and sony/gobreaker for a failing upstream.
That stack stays small and easy to test.
How do I pick a rate limit that won’t annoy real users?
Begin with normal traffic, then leave room for short bursts. If users often send two to five quick requests, allow that burst and block traffic that goes far beyond it.
Use more than one limit. A global cap protects the whole service, and per-tenant or per-IP limits stop one noisy client from slowing everyone else down.
Which failures should I retry?
Retry short-lived problems like 429, 502, 503, connect timeouts, resets, and temporary DNS issues. Stop right away on bad input, auth failures, and most 4xx responses.
Keep the retry count low and add jitter so clients do not retry at the same moment.
Is it safe to retry POST requests?
Not always. GET usually works fine to retry, but POST can create duplicate charges, orders, or signups if the first call actually succeeded.
Retry POST only when the API supports idempotency keys or your system can detect duplicates safely.
When should a circuit breaker open?
Open it on repeated failure, not on one unlucky request. For low traffic, five failures in a row can work. For busy paths, a failure rate rule often fits better, such as half of the last 20 calls failing.
Keep the open window short, then let one or two probe requests test recovery.
Should every external call use the same timeout and retry policy?
No. Payments, email, and webhooks need different rules. A payment call should fail fast with a short timeout and very few retries. Email usually belongs on a background queue. Webhooks need per-tenant limits and often a breaker too.
If you treat them the same, one slow dependency can drag down the whole request.
What mistakes turn a small failure into an outage?
Stacked retries cause a lot of pain. If the HTTP client retries, the service retries, and the job runner retries, one failure can turn into a flood of extra calls.
Shared limiters also create trouble. A noisy route or tenant can block healthy traffic if everything shares one bucket.
What should I test before I ship this setup?
Check every outbound call before release. Give each one a timeout shorter than the full request deadline, cap retries, return clear 429 responses, and export breaker state to logs or metrics.
Then run a load test with a traffic spike and a slow or flaky upstream. You want to see clean load shedding, short waits, and no retry storm.


