GitLab CI cache rules for monorepos on cheap runners
GitLab CI cache rules for monorepos cut job time on cheap runners when teams cache dependencies by language, skip full workspaces, and prune old layers.
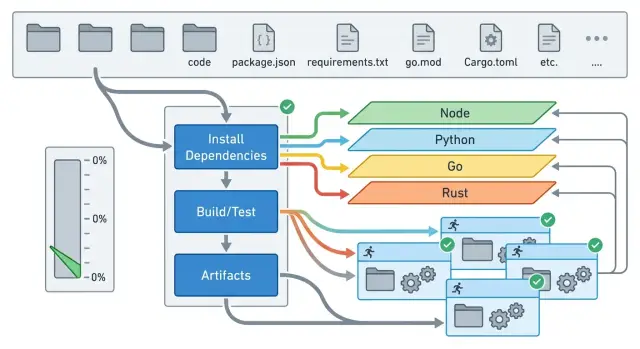
Table of Contents
Why monorepo caches get messy fast
A monorepo looks tidy in Git. Its cache rarely does. One repository can hold a React app, a Go API, a Python worker, Terraform files, and a mobile build. Each part pulls different dependency folders, package manager files, and build artifacts. If you treat all of that as one cache, the archive turns into a junk drawer.
That is why GitLab CI cache rules for monorepos need more care than a single app pipeline. A frontend test job does not need Go module files. A backend lint job does not need a Node package cache. When every job shares one cache key, runners keep downloading files they will never read.
The usual mistake is caching the whole checkout or large chunks of it. That feels easy at first. It also grows fast. Lockfiles change, generated files pile up, and temporary build output slips in. Soon the cache includes dependency folders, compiled assets, test leftovers, and random tool state from several languages at once.
Then the runner pays for it every time. Cheap GitLab runners usually have slower disks, less CPU, and tighter network limits. A large cache can take longer to download and unpack than the actual install step it was supposed to skip. A 1 GB archive on a small runner can burn a minute or more before tests even start.
The problem gets worse as the repo grows. One team updates Node packages, another changes Python tools, and a third adds a Rust service. If all jobs push to the same broad cache, each change churns the archive for everyone else. Pipelines feel random: one run is quick, the next one drags because the runner pulled a pile of useless files.
A simple example makes it clear. Imagine a docs change triggers a light backend check, but the job still restores frontend packages, mobile build caches, and old compiled output. The runner did work, but none of it helped that job finish sooner.
A cache should remove repeated dependency downloads. If it turns into a moving snapshot of the whole repo, it stops being a shortcut and becomes overhead.
Cache dependencies, not the whole checkout
A cache should hold files that are slow to download and safe to reuse. In a monorepo, that usually means package manager folders and dependency stores, not the full project tree.
On cheap GitLab runners, a full checkout cache often hurts more than it helps. GitLab packs source files, temp files, test reports, and old build output into one large archive. The runner then spends time compressing and unpacking junk that your job did not need.
Good cache targets are the folders your tools use to keep downloaded packages. Think of the pnpm store, npm cache, pip cache, Cargo registry, Maven repository, or Gradle dependency cache. Those folders change less often than your code, so they give you repeat speed gains without bloating storage.
Keep build output out of shared cache paths. Folders like dist, build, target, coverage, and generated SDK directories fill up fast and go stale even faster. When one job restores old compiled files from another branch, the failure can look random, which makes the problem annoying to trace.
If a job needs generated files, recreate them inside that job when possible. Generating Prisma types, API clients, or code from schemas usually takes seconds. Rebuilding them from source is often cheaper than chasing a broken cache that came from yesterday's run.
Artifacts solve a different problem. Use them only when the next job must read the exact files produced by the previous job, such as a compiled app, a test bundle, or a generated report. Cache is for reusable dependency layers. Artifacts are for direct handoff.
A simple rule works well: cache what you download, rebuild what you derive, and pass only required outputs between jobs. That keeps GitLab CI cache rules for monorepos practical, especially when runners have small disks and slow CPUs.
Split caches by language and tool
When a monorepo holds JavaScript, Python, Go, and Rust in one place, one shared cache turns into a junk drawer. A front-end job should not pull a Python cache, and a Go build should not drag around Rust artifacts it will never use. On cheap GitLab runners, that extra restore and upload time can cancel out the speed gain.
Give each package manager its own cache path. For npm or pnpm, cache the package store or download cache, not node_modules for the whole repo. The store changes less often, compresses better, and works across more jobs. Give it its own cache path and a cache key based on the lockfile for that part of the repo.
Python needs the same split, but the line is even sharper. Keep pip downloads in their own cache, and keep virtualenv folders out of shared caches. A virtualenv bakes in interpreter paths, compiled wheels, and runner-specific details. It goes stale fast, especially when the base image changes.
Go and Rust also work better when you split downloads from build output. For Go, cache module downloads such as the module cache, and keep compiled binaries separate. Binaries depend on OS, architecture, and build flags, so they age badly. For Rust, keep the Cargo registry and git data apart from the target directory. The registry is usually a good shared cache. The target folder can get huge and often only helps the same job on the same runner image.
A small rule saves a surprising amount of time: if a job never touches a language, skip that cache completely. A docs job usually does not need Cargo. A lint job for one Node package does not need Go modules. Pulling 700 MB of unused cache to avoid 30 MB of downloads is a bad deal.
This split makes GitLab CI cache rules for monorepos much easier to live with. Cache hits stay cleaner, storage stays smaller, and when one cache goes bad, you can clear that layer without wiping everything else.
Pick cache keys that expire at the right time
Cheap runners punish bad cache keys twice. You lose time on cache misses, then you keep paying for old archives that nobody reuses. A good cache key should change when dependencies change, not every time someone edits app code.
For most dependency caches, lockfiles are the cleanest trigger. In a monorepo, package-lock.json, pnpm-lock.yaml, poetry.lock, go.sum, or Cargo.lock tell you when the dependency layer actually changed. A README edit, a CSS tweak, or a small refactor should not force a full cache refresh. That is one of the most useful GitLab CI cache rules for monorepos.
If your runners do not share the same environment, include that in the key too. Native modules can differ across Alpine and Ubuntu, and the same problem shows up across amd64 and arm64. If you skip the OS, image, or architecture in the cache key, one branch may restore a cache that looks valid but breaks in odd ways.
A small pattern like this works well:
cache:
key:
files:
- package-lock.json
prefix: "node-$CI_JOB_IMAGE-$CI_RUNNER_EXECUTABLE_ARCH-v3"
The lockfile controls when the cache changes. The prefix separates environments. The v3 suffix gives you a manual reset switch.
Branch fallback helps, but only when dependency sets stay fairly stable. If most feature branches use the same packages as main, a fallback can save a lot of time on small runners. If branches often add native packages, swap language versions, or test major upgrades, branch fallback turns into a trap. You restore an old cache, then spend ten minutes debugging something that is really just stale dependencies.
The manual version suffix matters more than many teams expect. After a major Node, Python, or base image upgrade, bump v3 to v4 and move on. That one change clears dead weight fast and avoids weeks of half-broken caches.
A simple rule works well: tie caches to lockfiles, add environment details when builds differ, use branch fallback only for stable dependency layers, and rotate a version suffix when the ground shifts.
A simple setup that works on small runners
Small runners punish lazy caching. If one job zips the whole workspace, every later job pays for it in download time, upload time, and disk use. A cleaner setup keeps caches narrow and boring.
Start by writing down what each job actually installs. In many monorepos, that list is shorter than people think. Your frontend job may only need pnpm, a Python worker may only need pip, and a Go service may only need Go modules. If a job does not install a tool, do not give it that cache.
A mixed monorepo often works well with a split like this:
- Node jobs cache the pnpm or npm store, with a cache key based on the lockfile
- Python jobs cache the pip or Poetry download folder, with a cache key based on requirements or poetry.lock
- Go jobs cache the module download directory, with a cache key based on go.sum
Keep it to one cache path and one cache key per language. That rule feels strict, but it prevents the usual mess where one cache quietly collects unrelated files for months.
Test jobs should usually pull only. They benefit from warm dependencies, but they should not upload fresh caches on every run. That cuts cache churn fast, especially on cheap GitLab runners where network and disk are both limited.
Install jobs can push updates, but only when lockfiles change. In practice, that means a small prepare job for each language with rules tied to the right files. If package versions stay the same, the cache stays the same too. That is the whole point of dependency layer caching.
If you want a plain rule of thumb for GitLab CI cache rules for monorepos, use this: test jobs read caches, install jobs refresh them, and each language owns its own cache.
Then watch the numbers for one week. Track average job time, cache size, and how often jobs miss the cache. If a cache saves 15 seconds but grows by several gigabytes, drop it. Small runners do better with fewer caches that stay predictable.
A realistic example from a mixed monorepo
Picture a repo with four parts: a Next.js frontend in apps/web, a Python API in services/api, a Go worker in workers/queue, and docs in docs. The team uses cheap GitLab runners with small disks, so they keep caches narrow. Each job restores one dependency layer, then builds from a fresh checkout.
The frontend job caches the pnpm store, not node_modules and not the whole app folder. The lockfile controls the cache. If pnpm-lock.yaml changes, the cache changes too. If the team only edits UI code, the job reuses the store and skips another full dependency download.
Python gets the same treatment. The API job caches wheel downloads in a folder like .cache/pip and ties that cache to requirements.txt. It does not cache the whole virtual environment. That keeps the cache smaller and avoids strange failures when the runner image or Python version changes.
The Go worker caches module downloads from go.sum. Go already handles module state well, so the cache can stay focused on GOMODCACHE instead of the whole build tree. Rebuilds stay quick, and old module data does not bleed into unrelated jobs.
The docs job is the exception. If it only builds Markdown or a small static site, skipping dependency caches is often the better call. A clean run is simpler, and the job usually finishes fast anyway.
web:
cache:
key:
files: [apps/web/pnpm-lock.yaml]
paths: [.pnpm-store]
api:
cache:
key:
files: [services/api/requirements.txt]
paths: [services/api/.cache/pip]
worker:
cache:
key:
files: [workers/queue/go.sum]
paths: [.go/pkg/mod]
docs:
cache: []
This is what GitLab CI cache rules for monorepos look like when they work on a small budget. One repo can hold several languages, but each job restores only the folders it can actually use. That keeps monorepo pipeline speed up without filling runner storage with stale junk.
Mistakes that waste time and storage
The most common cache mistake is treating the whole workspace like something every job should restore. In a monorepo, that grows fast. Temporary files, test output, tool state, and dependency folders pile up until each job spends more time unpacking junk than doing real work.
node_modules causes this a lot. Teams cache it once, then attach it to lint, test, build, and deploy jobs. That feels convenient, but it bloats every restore and eats disk on small runners. A lighter cache, such as the package manager download store, usually gives most of the speed with far less baggage.
A single cache key across all branches causes a different mess. Old files stick around after lockfiles change, and feature branches can pull stale dependencies from unrelated work. The job may still pass, which makes the problem harder to spot. Use keys tied to dependency files, and add branch scope when shared state starts causing surprises.
Another bad habit is letting every job push the cache back. If four jobs restore the same archive and all upload it again, the runner keeps compressing near-duplicate data. That creates churn with no real gain. Pick one install job to refresh the cache. Let the other jobs read it only.
Build output should stay out of long-lived caches. Saving dist, build, or target folders can hide slow compile steps and broken incremental builds. If another job needs that output, pass it as an artifact for that pipeline run instead of keeping it around for days.
Old cache keys also build up quietly. Cheap runners do not fail on day one. They just get slower week by week until restores drag and disk alerts start showing up.
A safer pattern is simple:
- Cache dependency layers, not the full checkout.
- Split caches by language or tool.
- Let one job write the cache.
- Remove old cache keys on a schedule.
With GitLab CI cache rules for monorepos, boring rules usually win. If restore time stays predictable and disk use stops creeping upward, the cache is doing its job.
Quick checks before you keep a cache rule
Good GitLab CI cache rules for monorepos are boring. You should be able to explain each one in a few seconds: what it saves, how often it hits, and what makes it expire.
Start with repeat work. If a job installs the same packages on most runs, caching can help. If that job already finishes fast, or the package manager uses its own local reuse well enough, the extra cache step may add more time than it saves.
A simple test works well:
- Compare install time with and without cache on three normal pipeline runs.
- Check the cache archive size, not just the folder size in the job.
- Change one lockfile and see which jobs lose their cache.
- Measure restore time on the actual runner, not on your laptop.
- Read the rule again and ask if a new teammate would understand it.
Size matters more than people expect. If a cache archive grows to 1 GB to avoid downloading 250 MB, that is usually a bad trade on cheap GitLab runners. Compression, upload, restore, and storage all cost time. Dependency layer caching works best when the cache stays smaller than the network work it replaces.
Isolation matters too. One lockfile change should break one cache, not every cache in the repo. A Python requirements change should not flush a Node cache. A Rust update should not force Java jobs to start cold. If your cache key mixes unrelated files, fix that first.
Then check the restore path. Some runners have slow disks, weak CPUs, or shared storage. On those machines, unpacking a large cache can take longer than reinstalling packages from a nearby registry mirror. Measure the real restore time before you keep the rule.
Last, check if the rule will still make sense in two months. Monorepos change fast. Teams split folders, switch package managers, or stop using a tool. Add a short comment near unusual cache keys and review them now and then. If nobody can explain why a cache exists, delete it and see if anyone misses it.
What to do next
Start by deleting any cache that stores the whole workspace. That kind of cache looks convenient, but on cheap GitLab runners it usually turns into slow uploads, stale files, and bloated storage. Replace it with one small dependency cache in one job, then run the pipeline a few times and compare the results.
Keep a short note for every cache path you keep. If nobody can explain why a path exists, it probably should not stay.
- List the exact path.
- Note which job uses it.
- Write what it saves, such as npm packages, pip wheels, or Gradle files.
- Record what should invalidate it, such as a lockfile change.
- Remove anything that saves little time or grows without control.
This habit matters more in a monorepo because old cache rules stick around for months. A package gets removed, a tool changes, or one team stops using a language, and the cache still keeps eating space. Good GitLab CI cache rules for monorepos are a bit boring by design: small scope, clear purpose, easy to delete.
After that, set one monthly check. Look at three numbers only: cache size, cache hit rate, and average job time. If a cache saves 10 seconds but stores several gigabytes, cut it. If a cache misses most of the time, fix the key or remove the rule. If job times improve but runner disks fill up, prune more aggressively by language and tool.
A simple rule helps: every cache should earn its place. Dependency layer caching usually does. Full checkout caching usually does not.
If your team is still paying too much for slow pipelines, get another set of eyes on the setup. Oleg reviews cache rules, runner sizing, and CI/CD design with a practical focus on cost and speed. A short consultation can spot the usual waste fast, especially in mixed monorepos where small cache mistakes spread across every job.
The best next step is small and measurable: remove one broad cache, keep one narrow cache, and check the next five pipeline runs.


