File naming rules for automation teams can actually use
File naming rules for automation help teams sort, search, and process documents with fewer errors before OCR or AI starts reading them.
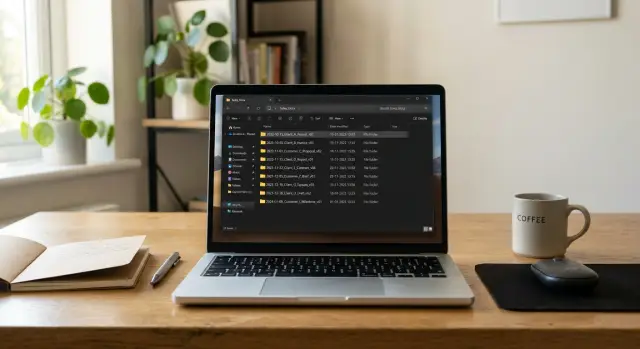
Table of Contents
Why messy file names slow everything down
Messy file names create work before OCR or AI gets a chance to help. One person saves Invoice May Final.pdf. Another uses 2024-05 ACME inv v2.pdf. A third uploads scan003.pdf. The documents might be the same type, but the system can't treat them as the same thing.
Search is usually the first thing to fail. When dates appear as 05-06-24, 2024_06_05, and June 5, people stop trusting search and start guessing. They sort by modified time, open several files, and compare them by hand. A few minutes here and there doesn't sound serious until it happens all day.
Matching breaks next. Automation works best when file names answer a few simple questions: what the file is, who it belongs to, when it was created, and which version is current. If the same customer shows up as ACME, Acme Ltd, and acme_new, the workflow can't tell whether those files belong together.
That pushes people back into manual checking. They open documents just to confirm basic details. Is this the latest copy? Is it for the right customer? Did someone already upload a corrected version? Those checks slow intake, review, approvals, and follow-up.
OCR reads the contents inside the file, but the workflow still relies on the name outside the file. A clear name helps route the document before extraction finishes. It also makes sorting, duplicate checks, and exception handling easier later. A vague name gives the system less context and creates more avoidable errors.
Good naming rules don't need to be clever. They need to be plain, consistent, and easy to follow when people are busy. When everyone uses the same pattern, search works better, handoffs get faster, and document prep stops depending on guesswork.
Choose the parts every file name needs
Most teams try to squeeze too much into a file name. That feels helpful at first, but it usually makes sorting worse. If the name carries project notes, payment status, initials, and random comments, the mess starts before scanning even begins.
Keep only the parts that help a person or a script identify the file quickly. For most teams, that means just four items:
- date
- customer name
- document type
- version, if you actually use versions
That is enough for many workflows. 2025-04-10_AcornLtd_invoice_v2.pdf is easy to sort, search, and match. Final invoice for Acorn Ltd April fixed newest one.pdf is not.
Order matters just as much as the parts themselves. Pick one sequence and keep it. If one person starts with the customer name, another starts with the date, and a third leaves out the document type, the workflow has to guess. Guessing is where mismatches start.
Extra words usually hurt more than they help. Terms like final, latest, updated, new, and scan mean different things to different people. A version number is clearer. If you don't track versions, leave that part out instead of inventing vague labels.
The pattern should fit the whole team, not one person's habits. Write it down, show a few examples, and keep it boring. Boring is exactly what you want here.
A solid starting pattern is YYYY-MM-DD_Customer_DocumentType_Version.
If one part isn't useful across the whole file set, remove it from the standard. Fewer choices means fewer cleanup jobs later.
Use one date format
Dates cause trouble fast. If one team saves files as 03-04-2025, another uses 4_3_25, and a third writes 2025-04-03, your automation has to guess what each file means. People can often work it out. Scripts get it wrong more often than you'd like.
Use YYYY-MM-DD everywhere. It sorts in calendar order without extra work, so 2025-02-01 comes before 2025-11-01, and all 2026 files land after 2025. That makes filtering, archiving, and batch processing much easier.
Keep leading zeros in months and days. Write 2025-04-03, not 2025-4-3. Computers sort text one character at a time, so missing zeros can put files in strange places.
Don't mix local date styles in one system. A US teammate may read 03-04-2025 as March 4. A European teammate may read it as 3 April. Your software has the same problem unless you add more logic, and more logic usually means more failure points.
Put the date in the same place every time. Most teams place it first because folder views sort correctly right away. If you choose another position, keep it fixed.
The difference is easy to see in real file names: 2025-04-03_Acme_invoice_v02.pdf, 2025-04-03_BrightLabs_contract_v01.pdf, and 2025-04-03_14-32_Acme_invoice_v03.pdf all sort cleanly.
Only add time when files from the same day would otherwise collide. If one customer sends three updated invoices in an hour, the date alone isn't enough. Add time in one format for those cases instead of stuffing every file name with detail it doesn't need.
This rule pays off early. Sorting works, duplicate checks get easier, and OCR starts with cleaner input.
Write customer names the same way
If one customer appears as Acme, ACME Ltd, and Acme London, your tools treat them like three different companies. That breaks sorting, matching, and search before OCR even reads the first page.
Start with a short approved list of customer names. Give each customer one exact label and use that label everywhere: inbox rules, shared folders, OCR jobs, and exports to the CRM or accounting system.
Nicknames cause trouble quickly. So do random short forms that make sense to one person and nobody else six weeks later. If the approved name is acme, don't save the next file as acmeco, acme-ltd, or acme_new.
Legal suffixes need one rule too. You can keep llc, ltd, or inc, or you can drop them. Either approach works. Mixing both does not. Most teams choose the shorter version unless two customers share the same base name.
Pick a format people will actually follow
Choose one separator for spaces and stick with it. If you use underscores, keep using underscores. If you use hyphens, keep using hyphens. Don't switch between north_star, north-star, and northstar unless one of them is the official label.
A small reference list helps more than a long policy. North Star LLC can become north_star, Blue River Inc can become blue_river, and AJ & Sons Ltd can become aj_sons.
Share that list with the people who name files and the tools that read them. The spelling has to match in every folder, upload form, template, and automation step.
When teams skip this, they end up fixing files by hand. Ten seconds per file sounds harmless. Across a few hundred invoices a month, it turns into hours.
Handle versions without confusion
Version labels fall apart when teams use words like final, final2, or latest. Those names feel clear for a day or two, then nobody knows which copy went to the customer and which one still has edits.
Use v01, v02, v03, not v1, v2, v3. The leading zero looks minor, but it keeps files in the right order when a folder grows. Without it, v10 can jump ahead of v2.
Keep version and status separate. Version answers "which edit is this?" Status answers "where is it in the process?" If people replace both with final, they lose both pieces of information.
For most teams, a small status set is enough: draft for work in progress, reviewed after someone checks it, approved when the content is accepted, and signed when a signed copy exists.
That gives you names like 2025-04-10_Acme_invoice_v03_reviewed.pdf or 2025-04-10_Acme_invoice_v04_signed.pdf. A person can read that in seconds, and a workflow can read it too.
One more rule matters: once you release a version, stop editing that file. If you need changes, copy it forward and save the next version number. Editing v03 after v04 exists breaks trust in the archive and makes historical comparisons unreliable.
Teams sometimes push back because this feels strict. In practice, it saves time. When someone asks for the approved copy from last Tuesday, you shouldn't need to open five files to find it.
Build the pattern step by step
Start with the few fields you can't do without. For many teams, that means date, customer name, document type, and version. If a field doesn't help people find, sort, or match the file later, leave it out.
Next, lock the order and don't change it. A simple pattern like date_customer_document_version works because people can scan it quickly, and scripts can split it the same way every time.
Pick one separator and use it everywhere. Underscores are a safe choice because they are easy to read and rarely cause trouble in local folders, shared drives, or cloud storage. Mixing spaces, dashes, underscores, and dots in the same set of files creates small errors that waste a lot of time.
Write a few sample names before you roll the pattern out. Real examples expose problems faster than a policy document does.
2025-04-10_acme-corp_invoice_v01.pdf
2025-04-10_acme-corp_invoice_v02.pdf
2025-04-11_northwind_purchase-order_v01.pdf
Then test those names where your team actually works. Drop them into a local folder, a shared drive, and the cloud tool people use every day. Check whether they sort the way you expect, whether search finds them quickly, and whether your OCR or import script can split each part without guessing.
A pattern is only good if it survives boring, repeated use. If one teammate writes Acme, another writes ACME, and a third writes acme_corp, matching starts to fail. The same goes for versions. v2, ver2, and final-final are not small differences when automation depends on exact text.
If the test feels awkward, fix it early. It's much easier to change three sample file names than three thousand live ones.
Mistakes that break sorting and matching
Small naming slips create hours of cleanup. A folder can look fine to a person and still confuse scripts, OCR queues, and import rules.
One common problem is separator drift. If one file uses spaces, another uses dashes, and a third uses underscores, the folder stops behaving like a clean set. 2025-04-10_acme_v02.pdf sorts differently from 2025 04 10-acme-v2.pdf, even though both mean the same thing.
Freehand customer names cause even more trouble. One person writes Acme, another writes ACME Corp, and someone else saves Acme Ltd. The system now sees three customers, not one. That breaks matching, creates duplicate records, and fills search results with noise.
Another mistake is hiding the date or version only inside the document. A person can open the file and work it out, but automation can't sort quickly if it has to read every page first. The file name should carry enough detail to route the file before extraction begins.
Symbols create avoidable problems too. Characters like /, \, :, *, ?, ", <, >, and | can fail on some systems or change during upload. Even if one platform accepts them, another tool may strip them out and create a mismatch.
Pattern changes are the slow poison. If the team starts the year with YYYY-MM-DD_customer_v01 and switches in July to customer_YYYYMMDD_rev1, sorting breaks across the archive. Reports split into two formats, old rules stop working, and people start writing exceptions.
A simple naming pattern fixes most of this. Pick one separator, one customer format, one date style, and one version rule. Then keep it stable.
If you ever need to change the pattern, do it on purpose. Set a cutover date, rename old files in a batch, and update the rule everywhere on the same day.
A simple example from invoice intake
A clean invoice flow can start with one file name: 2025-04-03_Acme_invoice_v01.pdf. That line already tells your team four useful things without opening the file: the date, the customer, the document type, and the current version.
Now imagine someone in accounts payable checks the invoice and spots a missing purchase order number. They don't rename the whole file or add notes in the middle. They change one part only: v01 becomes v02. If the invoice needs one more correction, it becomes v03. Everyone can see the latest draft at a glance.
Once the invoice is approved, the team keeps the same base name and adds a status tag: 2025-04-03_Acme_invoice_v03_approved.pdf. That small change separates review copies from accepted copies in a way both people and scripts can read quickly.
The OCR step gets easier because the file name already sets the basics. The system can group the file under Acme, treat it as an invoice, and place it in the right date range before extraction starts. OCR still reads the actual document for totals, invoice numbers, and line items, but it no longer starts from zero.
Finance saves time in day-to-day work too. If someone needs all Acme invoices, they filter by customer. If they need this week's documents, they sort by date. If they need the approved copy, they search for _approved. No one has to open ten PDFs just to find one file.
That is the whole point. The name should answer the filing questions first. The document itself can answer the rest.
Test before rollout
A naming rule can sound clear in a meeting and still fall apart when real files start coming in. Test it with a small group before you make it the default.
Ask two people who did not design the pattern to name five real files each. Give them about ten seconds per file. If they stop to ask where the date goes, how to write the customer name, or when to add a version, the rule still needs work.
Put twenty sample files in one folder and sort by name. The order should make sense at a glance. Then try to break the pattern on purpose. If two people can both create 2025-03-08_Acme_Invoice_v1.pdf for different documents, you need one more field, such as an invoice number or intake ID.
Check scanned documents too. Many teams build a clean rule for digital files, then let the scanner keep names like Scan001.pdf or IMG_4472.pdf. That split causes trouble later because the matching rules no longer work across the whole set.
Finally, feed a few sample file names into the tool that will process them. Mixed separators, random abbreviations, and uneven customer names often confuse extraction faster than people expect.
A short pilot usually exposes the weak spots. One person will shorten a customer name, another will skip the version, and the scanner will dump a generic file name into the same folder. Better now than after rollout.
What to do next
Put the rule where everyone can see it. A short shared page is enough. Show the exact pattern, explain each part, and add a handful of real examples people can copy.
Then roll it out in small steps:
- Test the rule in one live folder that gets new files every day.
- Add simple checks in upload forms or intake scripts so bad names get blocked or fixed early.
- Connect OCR or AI extraction only after the pattern stays clean for a week or two.
- Move old files in batches instead of trying to rename the whole archive at once.
A live folder tells you more than a workshop ever will. You'll see where names get cut off, where staff shorten customer names, and where version numbers start drifting again. Fix those weak spots, then test once more.
If several teams share the same intake path, an outside review can save a lot of rework. Oleg Sotnikov at oleg.is helps startups and smaller businesses tighten file rules, OCR handoffs, and automation workflows before a bigger migration or system change.
The goal is simple: new files arrive clean, old files get fixed in batches, and your automation starts with names it can trust.
Frequently Asked Questions
Why do file names matter if OCR reads the document anyway?
Because the file name helps your system sort and route the document before OCR reads the page. A clear name cuts down on guessing, duplicate checks, and manual opening of files just to confirm who they belong to or which copy is current.
What should a standard file name include?
Start with the basics: date, customer name, document type, and version if your team tracks versions. A simple pattern like 2025-04-10_acme_invoice_v02.pdf gives people and scripts enough context without stuffing the name with notes.
Why should we use YYYY-MM-DD for dates?
YYYY-MM-DD sorts correctly in folders and avoids date confusion between teams. 2025-04-03 means one thing everywhere, while 03-04-2025 can mean two different dates depending on who reads it.
How should we write customer names?
Pick one approved label for each customer and use it everywhere. If the customer is acme, keep using acme instead of switching between Acme, ACME Ltd, and acme_new, or your matching rules will split one customer into several names.
Should we use final or latest in file names?
Skip words like final, latest, and new. They stop making sense fast. Use clear version numbers such as v01, v02, and keep status separate with tags like approved or signed when you need them.
When do we need to add time to a file name?
Add time only when the date alone cannot separate files from the same day. If one customer sends three invoice updates in an hour, a time stamp helps. If not, leave it out and keep the pattern simple.
Which characters should we avoid in file names?
Avoid characters that break on some systems, such as /, \, :, *, ?, ", <, >, and |. Stick to letters, numbers, underscores, and hyphens so the name survives uploads, shared drives, and imports.
What should we do with files named Scan001.pdf or IMG_4472.pdf?
Do not let scanners dump generic names into the same workflow. Rename scanned files into your standard pattern right away, or add a rule in the scanner or intake step that replaces names like Scan001.pdf before the file reaches OCR.
Do we need to rename our whole archive at once?
No. Start with new files first, then rename old files in batches. That gives you a clean cutoff, avoids a huge cleanup job, and lets you fix the pattern early if the first batch exposes problems.
How can we test a naming rule before rollout?
Test it with real files and real people. Ask a few teammates to name sample documents quickly, sort them in one folder, and run them through your import or OCR flow. If people hesitate or the tool guesses wrong, tighten the rule before rollout.


