DTO sprawl in backend APIs with clearer boundaries
DTO sprawl in backend APIs adds duplicate mapping and blurry rules. Learn how to separate controllers, jobs, and handlers with less churn.
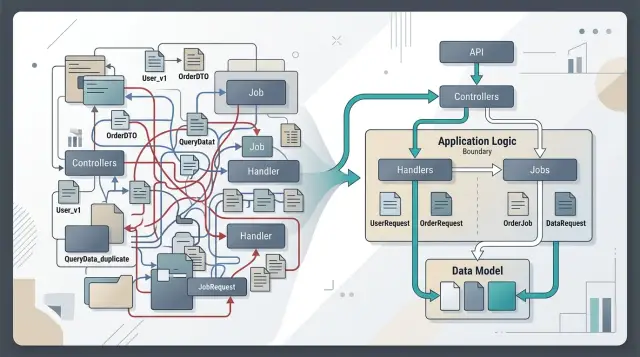
Table of Contents
Why the same object keeps getting copied
It usually starts with one harmless copy. A controller reads a request body, turns it into a DTO, passes another DTO to a service, and then a job gets its own version because async code should not depend on web models. Nothing looks wrong yet.
Then one field changes. Maybe customerNote becomes note, or phone splits into countryCode and number. One small edit now touches the request class, service input, job payload, event body, test fixtures, and mapper methods. The data barely changed, but the update spreads through half the codebase.
Names drift even when the shape stays the same. OrderUpdateRequest, UpdateOrderInput, OrderPatchCommand, and OrderJobData can all carry the same fields in a slightly different order. After a few months, nobody knows whether those names describe real business meaning or old accidents that never got cleaned up.
That drift causes a bigger problem than extra typing. Copies make rules disappear. If only managers can change a discount, where should that check live? Teams often split it across controllers, mappers, handlers, and jobs because every layer owns its own version of the data. The code still runs, but the rule has no clear home.
Short term, this feels fast. You copy a class, rename two fields, and move on. The pull request stays small, and you avoid a harder discussion about boundaries. Later, the cleanup bill shows up.
Every new flow needs another mapper. Tests grow around copies instead of behavior. Refactors slow down because people worry about breaking one of the quiet duplicates they forgot existed.
This kind of sprawl rarely comes from one bad choice. It grows from many tiny "just for now" decisions. Each copy saves ten minutes today. After enough of them, a simple field rename can eat half a day, and nobody can say which object owns the truth.
Where copies usually pile up
Most teams do not create ten versions of the same object on purpose. The copies appear one layer at a time.
A controller reads JSON into UpdateOrderRequest. A queue job wraps the same fields into UpdateOrderJob. An internal handler asks for UpdateOrderCommand. Then the API sends back OrderResponse, which often looks a lot like the first request.
At the HTTP edge, this feels normal. Request bodies need parsing, validation, and clear error messages. A separate shape for outside input makes sense there. The trouble starts when that edge model keeps traveling inward. Instead of mapping once, people keep cloning the structure and renaming it.
Queues make the problem worse. Job payloads usually need a stable serialized shape. That is a real boundary. But teams often copy every field from the request, even when the worker only needs an order ID, actor ID, and a small patch. Now the same update exists in two or three near-identical types. A week later someone adds couponCode to one and forgets the others.
Handler inputs pile up next. Service methods and command handlers often accept their own DTOs because each layer wants to look clean on paper. In code, it turns into a relay race of mapping functions that do little more than copy names.
Responses can quietly double the count again. Many APIs return a model that mirrors the request shape, even when the client only needs status, timestamps, and the fields that actually changed. That symmetry feels neat, but it bloats the codebase.
A simple rule helps: keep separate models only where the boundary is real. External input is one boundary. Queue transport can be another. Internal code usually needs fewer shapes than people think.
If you inspect a flow and see the same five fields copied through controller, job, handler, and response, that is the problem. The waste is not just extra classes. It is the drift between them, the missed field, the stale validation rule, and the hour lost tracing which object is the real one.
Draw the boundaries before you name the types
Teams often copy objects because they never name the boundary they are crossing. One object enters the controller, then the same shape leaks into services, jobs, and event handlers. After a few months, nobody knows which fields matter and which ones just came along for the ride.
A cleaner approach is to give each boundary its own small contract. The network sends one shape. Business logic uses another. Background work carries a third, often smaller payload. That does not mean you need layers of ceremony. It means each layer gets only what it can use.
Problems usually start when a request model becomes the default object everywhere. That is convenient for a week and annoying for years. Clients send optional fields, nested blobs, and naming choices that make sense on the wire, not inside your code.
A short set of rules is enough:
- Request DTOs describe what a client may send: field names, formats, and nullability.
- Service inputs describe what the business logic needs to decide.
- Job payloads carry only the facts a worker cannot safely recalculate later.
The second rule matters most. Your business logic should not care whether the API called a field user_id, userId, or wrapped it inside a larger object. Map that once at the edge. Then pass a small input that matches your domain language.
Background work needs even more discipline. Jobs often live longer than requests, so they should carry stable data. Prefer IDs, timestamps, and a few fixed values over full request snapshots. If the worker can load fresh data, let it do that. If it cannot, include only the fields that must survive.
Keep one written rule for each boundary, and keep it short enough that a teammate can remember it. For many teams, this is enough: controllers validate and map, services decide, jobs carry the minimum.
A good test is simple. If an email job only needs order_id and template, do not send the whole order update object into the queue.
Refactor one painful flow first
This problem rarely disappears in a big rewrite. It shrinks faster when you fix one flow that already hurts: an endpoint with too much mapping code, too many near-identical types, and too many handoffs.
Pick the path that annoys your team every week. A good candidate has a controller DTO, a service DTO, a job DTO, and maybe one more copy for an event handler, all carrying almost the same fields.
Keep the first pass simple:
- Choose one endpoint and trace the full path from request to database write, queued job, and follow-up handler. Write down every object shape along that path.
- Keep the transport DTO at the edge. Let it deal with HTTP names, query strings, nullable fields, and input validation. Do not pass that same object deeper into the app just because it already exists.
- Convert the request into one inward-facing shape. That can be a command like
UpdateProfileor a domain object if the use case fits. - Cut job payloads down to IDs and the few facts workers need right now.
- Leave old copies in place until tests pass. Then delete the unused DTOs and mapping code in one cleanup commit.
This works because each layer gets one job. The controller reads transport data. The application layer handles intent. Jobs carry only what background work needs.
A profile update flow makes the point. The request may include strings like display_name and timezone. The controller validates them, then creates UpdateUserProfile. A queued avatar refresh job only needs userId and avatarVersion, not the whole request body.
Do that once, and the next refactor gets easier. Teams usually find that one cleaned-up endpoint removes a surprising amount of mapping code and makes later changes much less annoying.
A simple order update example
An admin opens the orders screen and changes an order from "paid" to "shipped". This is where the mess often starts: one request object enters the controller, then the same shape gets copied into a service object, a queue payload, and a response object, even though each layer needs something different.
Keep the controller close to HTTP. It should read raw fields like orderId, status, and maybe an optional note, then validate them as request data. If status is missing or invalid, the controller should stop there and return an error. That check belongs at the edge because it is about user input, not business rules.
After that, the controller should build a small command for the handler. Something like ChangeOrderStatus(orderId, newStatus, changedBy) is enough. The handler does not need headers, query params, or the full request body. It only needs the data required to decide whether the order can move to the new status.
The split is straightforward:
- The controller reads and validates raw request fields.
- The handler gets a small command with business data.
- The job gets only
orderIdand an event name likeorder_shipped. - The response model is built after the work is done.
Inside the handler, the code loads the order, checks the rules, updates the status, and saves it. If the order is already cancelled, the handler rejects the change. If the update succeeds, it can queue a background job for email or audit logging.
That job should not receive the whole order object. Send only the order ID and the event name. When the job runs five minutes later, it can load fresh data instead of trusting an old copy.
The response for the admin screen should also stay separate. Build it at the end from the updated order and shape it for the UI. Maybe the screen needs id, status, updatedAt, and a message like "Order marked as shipped". That is a response model, not a domain model, and not a job payload.
It looks like a small change, but it cuts a lot of noise. Each layer gets a small object with a clear job, and the order stops changing shape every time it moves through the code.
When reuse helps and when it hurts
Reuse is fine when two layers mean the same thing by the same fields. If your service and your job worker both deal with a plain "invoice to send" object, one type may be enough. You do not need a fresh wrapper every time data crosses a file or package boundary.
Trouble starts when teams reuse a type just because it looks close enough. A controller request object often carries transport noise: query params, raw strings, nullable fields, pagination details, auth context, or flags added for one endpoint. That shape may fit HTTP, but it usually does not fit the domain.
A simple rule helps: keep one type when the meaning stays the same, split it when the meaning changes. "User profile update request" and "profile update command" sound similar, but they are not always the same object. The request may allow partial input and loose formats. The command should be stricter and easier to trust.
You can usually reuse a type when both layers need the same fields, the same validation rules apply, field names mean the same thing, and neither layer is carrying protocol-specific extras.
If one layer adds transport concerns, split the types early. That includes headers, status codes, raw JSON names, retry counters, message metadata, or fields that exist only because one endpoint sends them. Those details spread fast. Soon you get a shared struct with 25 fields, half optional, and nobody knows which five matter in each path.
That kind of reuse saves a few minutes now and wastes hours later. People add another nullable field instead of asking whether the model still makes sense.
Small conversions are usually the better trade. A short mapping function is boring, and that is good. It makes the boundary visible. It also gives you one place to clean input, set defaults, and reject values that should never reach the domain.
If a conversion feels repetitive, check the model first. The fix may be better boundaries, not a bigger shared type.
Mistakes that keep the sprawl alive
One common mistake is copying shapes by name, not by meaning. An OrderDto in a controller might mean raw user input, while an OrderDto in a worker means trusted data that already passed checks. Same name, different job.
Another mistake is adding fields "just in case." A small request object slowly picks up status flags, internal notes, calculated totals, and response labels. Nobody wants to remove a field later, so each layer accepts more than it needs. The object looks convenient, but it stops saying anything clear.
Validation often spreads the problem further. The controller checks that a field exists. The service checks it again with a slightly different rule. A background job repeats the same logic because queue messages can come from another path. After a few months, one rule lives in three places and nobody knows which one is correct.
A better split is simpler. Put input validation near the edge, then let deeper layers enforce business rules that belong there.
Queues create another pile of copies. Teams often send full objects because it feels faster than fetching data again. That shortcut ages badly. Once the message shape changes, old jobs break, or workers need awkward fallback code. In most cases, send an ID and let the worker load fresh data. Send a full snapshot only when the exact state at queue time matters.
Response models also cause damage when people treat them like domain models. API responses exist for clients. They are often flatter, renamed, or packed with display-friendly fields. Domain models exist for business logic. If you mix them, a small API change can ripple into handlers, jobs, and core rules.
Before you add another DTO, ask one plain question: does this object carry a new meaning, or is it just another copy with a slightly different field list? If the meaning did not change, the new type probably should not exist.
Quick checks before you add one more DTO
Most of this mess starts with a reasonable thought: "this layer should have its own object." Sometimes that is true. Often it is just copy-paste with a new name.
A quick review helps. Take one flow, like an order update. The request enters the controller, a job goes to the queue, and a handler writes to the database. Before you add one more type, check whether the new layer really needs a different shape or just fewer fields.
Ask a few direct questions:
- What must this layer know that the previous layer should not carry?
- If the answer is "nothing," why create a new type?
- If a layer only needs to hide a few fields, can you drop those fields at the edge instead of cloning the whole object?
- Who validates each field, and can a new teammate find that rule quickly?
- If this is a queued payload, will old messages still work after the schema changes?
Separate objects make sense when boundaries are real. An external API contract, a public event, and a domain model often need different rules. Internal hops inside the same use case usually do not.
A small amount of repetition is normal. Confusing ownership is the real cost. When names, fields, and validation rules line up, the code gets easier to change, and new DTOs stop appearing out of habit.
What to do next in a real codebase
This problem usually shrinks when a team audits one feature path and fixes it all the way through. Pick one flow that people touch often, such as "update order" or "create invoice," and trace it from the HTTP request to the controller, service, job, handler, and database write.
Write down every type that appears on that path. Then count every mapping. The number alone is useful. A request object that becomes a controller DTO, then a service DTO, then a job payload, then a handler input usually means the code learned to copy first and explain later.
A simple audit can fit on one page:
- list each object in the flow in order
- note where fields change names or shapes
- mark why each mapping exists
- remove mappings that only rename fields with no boundary reason
Some mappings are fine. Validation at the edge is fine. A job payload may need a smaller shape than the request. A domain model may need rules that the transport type should never carry. Keep those. Question the rest. If nobody can explain why a mapping exists, it probably should not.
Naming rules help more than most teams expect. Use one pattern for transport types, one for commands, and one for domain models. Names like UpdateOrderRequest, UpdateOrderCommand, and Order are plain, but they reduce drift. People stop guessing whether OrderDto, OrderData, and OrderPayload mean different things.
Code review is where this either sticks or falls apart. Before any new DTO lands, ask one direct question: does this type protect a boundary, or does it just move the same data again?
If your team is too close to the problem to judge it clearly, an outside review can help. Oleg Sotnikov at oleg.is works with startups and smaller companies as a fractional CTO, and this kind of boundary cleanup is exactly the sort of practical architecture problem he helps untangle without forcing a full rewrite.
Frequently Asked Questions
How can I tell if DTO sprawl is hurting my API?
You probably do if the same fields show up in request classes, service inputs, job payloads, and response models with small name changes. Another clear sign is when a simple rename forces edits in mappers, fixtures, handlers, and queue code all at once.
When does a separate DTO actually make sense?
Create a new DTO when you cross an actual boundary and the meaning changes. HTTP input, queue transport, and client responses often need their own shapes. Inside one use case, keep one inward-facing object if the fields and rules stay the same.
Should I pass the request DTO straight into my service?
Usually no. Request DTOs carry transport details like raw field names, optional values, and parsing rules. Map them once in the controller, then pass a smaller command or input object that matches your business language.
What should I put in a queue job payload?
Keep the payload small and stable. Send IDs, timestamps, and the few values the worker must keep from that moment. If the worker can load fresh data later, let it do that instead of trusting a full request snapshot.
Where should validation live?
Put input validation at the edge, where you parse and reject bad requests. Keep business rules in the handler or service, where you know the current state and can make decisions like whether an order may move to a new status.
Do I need separate response models?
Yes, when the client needs a shape that differs from your domain. A response model can flatten fields, rename them, or add UI-friendly text. Build it at the end instead of reusing domain objects or job payloads.
How do I clean this up without a big rewrite?
Start with one flow that annoys the team often. Trace it from controller to database write, job, and follow-up handler. Keep the transport DTO at the edge, create one inward-facing command, trim the job payload, and delete old copies after tests pass.
Should every layer have its own mapper?
No. Map only at boundaries that need different rules or different shapes. If two layers mean the same thing by the same fields, another mapper just adds noise and another place for drift.
What naming pattern helps keep boundaries clear?
Use plain names that tell you where the object belongs. UpdateOrderRequest for HTTP input, UpdateOrderCommand for application intent, and Order for the domain keeps the flow readable and cuts guessing.
What simple rule can my team use before adding one more DTO?
Ask one direct question before you add a type: does this object protect a boundary, or does it just copy the same data again? If the meaning did not change, skip the new DTO and keep the path simple.


