DDD-lite with gRPC between internal modules in practice
DDD-lite with gRPC keeps transport rules at module edges while your domain model stays plain, easier to test, and less tied to framework code.
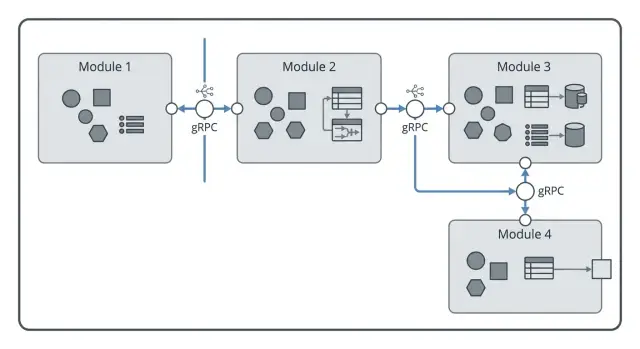
Table of Contents
The problem this solves
Teams often start with a shortcut that feels harmless: one set of structs for everything. Orders, billing, users, and notifications all read and write the same shapes, so nobody has to map fields between modules.
It feels fast for a while. Then one small change starts breaking code in places that should have nothing to do with it.
A billing team adds a transport-only field for a gRPC call. Soon the order domain carries request metadata, status wrappers, or enum values that only make sense on the wire. After that, framework details spread inward. A simple business rule like "can this order be charged?" stops being a plain function and starts depending on generated types, protobuf rules, or gRPC error handling.
The code still runs. It just gets harder to read because business logic and transport logic are mixed together.
Tests usually get worse next. If domain code knows about gRPC types, even a tiny unit test needs builders, generated fixtures, or transport setup. A test that should take a few lines turns into a small integration test. That slows the team down and makes refactoring feel risky.
You can usually spot this problem early:
- a protobuf change breaks code that never makes a network call
- modules import each other's structs just to avoid mapping
- domain tests need gRPC request objects to exercise simple rules
- internal APIs start shaping the business model instead of the other way around
A lighter DDD approach fixes this without turning the codebase into a theory exercise. The goal is practical: keep each module's domain model plain, let gRPC contracts handle transport, and translate at the edges.
That gives you a clean seam between modules. Billing can expose a gRPC contract without forcing orders to think in protobuf messages all day. The domain stays small, testable, and boring in the best way. You still get strict boundaries between modules, but you avoid heavy layers and architecture built for its own sake.
When this split works, developers can change transport rules, retry logic, or field names without rewriting business rules. That is the payoff.
What DDD-lite means in practice
DDD-lite is a small, practical version of domain-driven design. You do not need every pattern from the books. You keep the parts that help a team ship code with less confusion: clear module boundaries, shared language, and domain code that reads like the rules it handles.
In day-to-day work, each module owns its own behavior. Orders decide when an order can be confirmed or canceled. Billing decides when to create an invoice or mark it paid. That sounds obvious, but plenty of codebases blur those lines until every change touches five packages.
The "lite" part is what makes this usable. Skip the ceremony. You do not need giant diagrams nobody updates or long debates about naming when a plain name will do. If a concept helps people write and change code safely, keep it. If it only makes the folder tree look clever, drop it.
A good module has a small public surface and plain code inside. The business model should not be built from transport messages, database rows, or framework types. It should just be code with rules, state, and methods that make sense for that part of the business. That keeps tests cheap and trustworthy.
Language matters more than many teams expect. If one module says "customer," another says "account," and a third says "user" for the same thing, bugs creep in fast. You do not need perfect theory. You do need consistent words in code, contracts, logs, and team conversations.
This gives you a middle ground that works well in growing products. Modules stay independent enough to change, but the team does not drown in process. When a new developer opens the code, they should see business rules first and transport details second.
Keep the domain model plain
Your domain code should read like business logic, not networking code. A discount rule, renewal check, or fraud flag should work with plain structs and methods that describe the business in ordinary terms.
When protobuf messages leak into core packages, the model starts bending around transport needs. Generated fields, wrapper types, and serialization details creep into places that should only care about rules. Small changes become harder for no good reason.
A simple split works best. Let the gRPC handler decode the request into plain values, call domain code, then map the result back into a response. Inside the domain, pass values that tests can build fast: IDs, money amounts, dates, status values, and small structs with behavior.
Say you have a rule that blocks a refund after 30 days. The domain method should not need a gRPC request object, server context, or serializer. It should accept the purchase date, the current date, and the order state, then return a clear decision.
That keeps tests cheap. A unit test for the refund rule runs in milliseconds and never opens a port, reads a schema, or touches a network stack. You can write ten cases in a few minutes and understand failures right away.
This is where the boundary pays for itself. Contracts stay at the module edge, where translation belongs, and the domain stays free to change with the business. If you rename a protobuf field or swap transport later, the rule itself does not care.
Teams that move fast often learn this after a painful refactor. Once every rule depends on generated types and service plumbing, test setup grows and changes feel risky. Plain domain code is easier to reason about, easier to test, and much easier to run without network or serialization.
Use contracts only at the edges
Inside one codebase, protobuf should stay in the transport layer. Treat .proto files like envelopes. They define what crosses a module boundary, not how the business rules work. Pricing logic, order rules, and state changes should live in plain structs or classes that know nothing about gRPC.
A clean boundary usually has one small adapter on each side. The adapter receives a protobuf request, handles transport concerns, and maps fields into domain input. After that, the domain code works with its own types. It returns a domain result, and the adapter maps that result back into a protobuf response.
This feels boring, and that is good. If a field name changes in a .proto file, you want one mapping function to change, not fifty files across the module.
Generated message types cause trouble when they leak inward. They pull transport details into tests, tie your code to a serializer, and make refactoring slower. A handler like CreateInvoice(ctx, *billingpb.CreateInvoiceRequest) (*billingpb.InvoiceResponse, error) is fine at the edge. The code under it should look more like CreateInvoice(input CreateInvoiceInput) (Invoice, error).
The same rule applies to outbound calls. Do not let the rest of a module import a generated client and call it directly. Wrap it behind a small interface that matches the module's real need. For billing, that might be "charge an order," "check billing status," or "reserve credit." The interface belongs to your module. The gRPC client is only one implementation.
There is a simple test for whether the boundary is in the right place. If you can unit test the rule without a protobuf message, network stub, or generated client, the design is probably healthy. If every test starts by building transport messages, the edge has leaked into the core.
This also keeps change cheap. You can replace gRPC later, or call the same module in process, and the domain code stays the same. That is how internal boundaries survive the first rush to ship.
Split one module at a time
This gets easier when you split one small module first, not the whole codebase at once. Pick a part with one clear job, such as billing, notifications, or user sessions. If a module has five different reasons to exist, it is still too big.
A simple order helps.
Start with domain types. Write plain structs or classes that describe the business idea, not the wire format. An order ID, a money value, or a payment request should make sense in tests without gRPC, a database, or generated code around them.
Then add a small service interface. This is the surface other modules use. Keep it narrow. A billing module may only need methods like reserve funds or capture payment. If the interface starts to look like a full admin panel, cut it back.
After that, create protobuf messages for transport, not for the domain. These messages should fit what callers send and receive over the boundary. They do not need every internal field, and they should not expose private state just because it already exists.
From there, map the incoming request to domain input in the gRPC handler. The handler should turn strings, numbers, and enums into plain domain values, then call the service. Keep this layer boring. Boring code is easier to trust.
Finally, map domain output back to the response and return only what the caller needs. If the mapping feels messy, the contract is often too wide or the domain type is doing transport work by accident.
A small example makes this concrete. Say the orders module asks billing to reserve $49. The gRPC request may carry an order_id, amount, and currency. The handler converts that into plain domain input, the billing service decides whether the reservation is allowed, and the response sends back a reservation ID plus a status.
That split gives you two clean test paths. Domain tests call the billing service directly. Transport tests check validation and mapping. When both stay short, the boundary is probably in the right place.
A simple example with orders and billing
Picture two internal modules. Orders decides whether an order can exist. Billing decides what money should be charged and when an invoice should be issued. They talk to each other, but they do not share their inner rules.
A customer places an order for three seats on a monthly plan. The order module checks its own rules first: does the customer exist, is the plan active, and can this order move from draft to confirmed? That work stays inside the order module as plain code and plain objects. No gRPC request types should appear in that logic.
The order module might build a domain object like Order, calculate its own status, and save it. After that, it sends a small request to billing. That request is only transport. It is not the order model.
An invoice request often needs just a few fields: order_id, customer_id, currency, line items with quantity and unit price, and due_date. That is enough for billing to do its own job. Billing should not receive the full order aggregate, a pile of internal flags, or status history just because gRPC makes it easy to serialize more data.
Billing then applies its own rules. It can decide whether to group line items, add tax, round totals, or reject the request because the currency is unsupported. Those rules belong to billing, not orders.
The same separation works in the other direction. Orders owns order status changes. Billing can report facts such as invoice_created or payment_failed, but it should not reach in and set order.status = paid. Orders should translate that external fact into its own state change using its own rules.
That small gap between plain domain code and gRPC contracts is where this approach stays clean. You can test order creation without spinning up a server. You can test billing rules without mocking half the system. And when the contract changes, you edit the edge, not the heart of the module.
Mistakes that create tight coupling
Coupling usually starts with a shortcut that looks harmless. A team reuses a protobuf message as a business object, skips one mapper, and saves an hour. A few months later, a field added for transport rules changes domain code in three modules.
That happens because protobuf messages are contracts, not business types. They carry transport concerns: optional fields, wire formats, backward compatibility, naming rules, and enum values that exist for API stability. Your domain model should stay plain. It should read like business code, not like a generated schema.
Another common mistake is database reach-through. One module needs data, so it reads another module's tables directly. It feels fast. Then the table shape changes, a hidden report breaks, and nobody knows who owns the fix. If a module can read another module's tables, the boundary is mostly fake.
Teams also create one large contract that tries to cover every use case. The result is a bloated proto file full of fields that only one caller needs. Soon every request and response looks similar, but each one means something different. That kind of contract ages badly because nobody wants to remove anything.
Transport enums cause a quieter problem. A proto enum starts as a wire detail, then domain rules begin to switch on it. Now business decisions depend on transport values. Renaming or splitting an enum becomes risky, even when the business model wants different terms.
Shared helper packages can hide the damage for a while. You often see names like common/mappers or proto_utils. Nobody really owns them. Everybody edits them. Mapping bugs pile up there because no module treats that code as part of its own job.
A few warning signs show up early:
- domain tests need generated protobuf types
- one module reads another module's tables for "just one query"
- proto files grow faster than domain code
- helper packages know too much about several modules
Oleg Sotnikov often frames this problem in a simple way: architecture gets messy when ownership gets blurry. If one team cannot change a contract, table, or mapper without surprising another team, the modules are already coupled. The fix is usually plain and worth it: keep domain objects inside, map explicitly at the edge, and give every contract a clear owner.
Checks before you ship
A module is usually ready when you can change it without waking up three other parts of the system. That is easy to say and easy to fake. A few direct checks catch most boundary problems before they turn into rework.
Run business rule tests without a gRPC server, database, or network. If you can create an order, apply a discount, or reject bad input in memory, your domain code is still plain.
Replace a real gRPC client with a tiny fake in unit tests. If the test only needs a couple of returned fields, the module depends on a contract, not on transport setup.
Read the contract file on its own. It should describe request and response data for transport, not your full business state, private rules, or internal object shape.
Check data ownership. Orders should own order data and order rules. Billing should own invoice data and payment rules. One module should not reach into another module's tables or internal structs.
Ask a new developer to find the boundary quickly. They should be able to spot where the domain code lives, where the gRPC contract lives, and which imports are allowed within a few minutes.
A small example helps. Say billing needs the final amount for an order. The orders module can return order ID, currency, line totals, and status through gRPC. Billing can use that data to decide whether to create an invoice. Billing should not import the orders domain types just because they already exist.
This is where teams often go wrong. They put business meaning into the contract, copy that contract deep into domain code, and then tests start needing servers and generated clients. The code still works, but every change gets slower.
One rule is worth keeping in mind: if a unit test for one business rule needs a network port, the boundary is already blurry. Fix that before you ship. It is a small cleanup now and a painful rewrite later.
Next steps for a growing codebase
A growing codebase gets messy in small ways first. Generated request types slip into business rules, tests start needing gRPC setup, and a small change in one module spills into others. If you are using this style, fix that drift one boundary at a time.
Skip the full rewrite. Pick one seam that already hurts, usually a module with frequent changes, slow tests, or unclear ownership. Freeze the current contract, then trace every place where protobuf or generated gRPC types appear outside handlers and clients. That gives you a real map of the coupling instead of a guess.
Most teams end up with the same first batch of work. Move generated types out of domain services and entities. Add mappers next to handlers and gRPC clients. Keep use cases and domain code on plain structs or objects. Rewrite tests so they call the domain model without transport setup.
Those mapping layers should stay boring. They copy fields, convert enums, and deal with wire-format defaults. They should not decide prices, permissions, retries, or state changes. If a mapper starts growing branches, the boundary is blurry again.
After the first cleanup, make regressions harder. Keep generated code in its own package and treat imports into domain code as a review smell. Even a simple rule in code review helps: domain packages do not know what gRPC looks like.
This usually pays off faster than teams expect. A contract can change without breaking half the business tests. A domain rule can change without regenerating clients. New developers also read the code with less friction because the business logic looks like business logic.
If you want an outside review before the coupling gets worse, Oleg Sotnikov at oleg.is works as a fractional CTO and startup advisor. He helps teams review module boundaries, infrastructure choices, and practical AI-first development workflows without turning the codebase into an academic project.


