DDD-lite in Go without a framework: package structure
DDD-lite in Go without a framework helps you arrange packages, place interfaces, and handle transactions without fighting plain Go code.
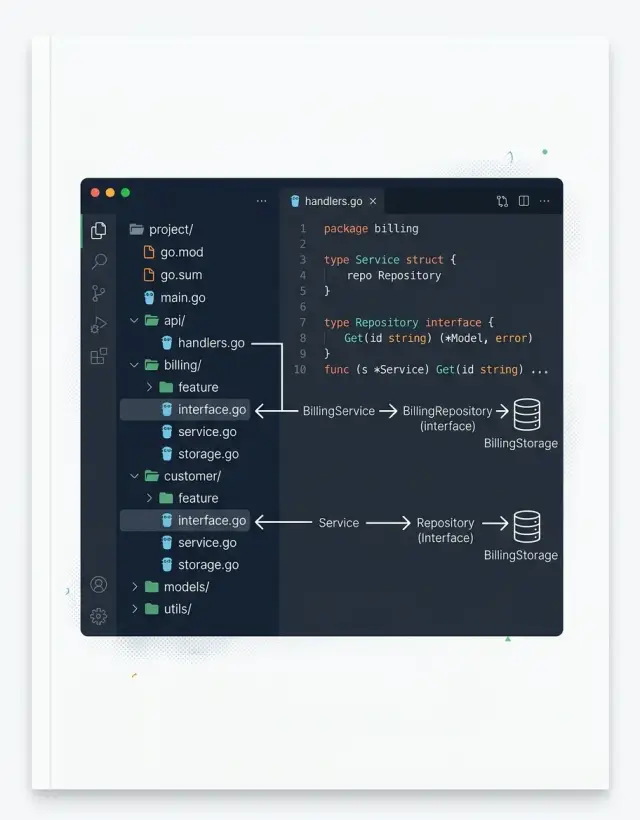
Table of Contents
Why plain Go projects get messy
A lot of Go projects start with tidy folders like handlers, services, and repositories. It looks clean on day one. A few months later, one business action is split across half the codebase, and nobody can read the full flow without jumping through five files.
That folder style hides the work the program actually does. A user places an order, renews a subscription, or invites a teammate. Those are real actions. But the code gets grouped by technical role, so the business story disappears.
The next problem is leakage. SQL rows, database errors, and storage-specific types slowly creep upward. A handler starts checking fields that came straight from a query. A service returns something shaped like a table row. Soon the HTTP layer knows too much about the database, and changing the schema feels risky.
Then even a small change spreads everywhere. Say you add one rule to checkout: block orders when stock is reserved but not confirmed. That sounds local. In a messy codebase, it can touch the handler, a service, two repository methods, a shared model, and three test setups. The rule is simple. The structure makes it expensive.
Tests usually suffer next. When business rules depend on live database calls, even basic tests get heavy. You should not need Postgres running just to check whether an order total gets a discount. But teams end up there because the rule lives inside query code or depends on database types.
The result is familiar:
- reading one use case takes too long
- simple changes touch too many files
- tests turn slow and brittle
- database choices leak into business code
That is why a lighter DDD style appeals to so many Go teams. The point is not to add more patterns. The point is to keep the code for one piece of work close together, so the flow stays obvious and the rules stay easy to test.
What DDD-lite means in plain Go
Most Go projects get worse when they copy a full pattern catalog. You end up with folders named after ideas instead of work, and the business rules hide behind wrappers, mappers, and storage code.
DDD-lite keeps the part that matters: the code should match the business. If the app handles orders, billing, or access rules, those concepts should appear clearly in the code. You do not need aggregates, factories, and repositories everywhere just because a book used them.
A simple test helps: can you open one package and understand what rule it owns? If checkout decides whether an order can be paid, that rule should live close to checkout code, not inside a database package or scattered across handlers.
Small packages usually work better than one big domain layer. One package might own order checkout. Another might own invoicing. Each package can have a few plain types, a service or two, and some functions that enforce rules. That is often enough.
Start with behavior, not storage. Think about what the code must protect or decide. An order cannot be paid twice. A discount expires on a given date. A user without permission cannot approve a refund. Once those rules are clear, add the database shape that supports them. If you start from tables, the code often turns into nothing but moving fields around.
Plain Go types already do most of the work. A struct with methods, a constructor when it helps, a small interface when a caller needs one, and normal error handling can carry a lot of weight. You do not need framework magic to model real behavior.
For example, an Order type can know whether it is payable. A checkout service can ask for stock, reserve items, and save the result. The database code still matters, but it stays in a supporting role. That keeps the model easier to read and much easier to change when the rule changes next month.
Pick package borders that match the work
This approach starts with one user action. Pick something concrete, like "create order", and shape packages around that work. If you start with layers such as models, services, and utils, the code usually drifts into a pile of shared pieces with no clear owner.
A better border is the feature itself. The order code should live together because it changes together. Validation, pricing checks, stock rules, and the command that runs the flow usually belong near each other, even if they call different storage or delivery code.
For an order flow, a small layout like this works:
internal/
order/
create.go
cancel.go
order.go
repository.go
http/
order_handler.go
postgres/
order_repo.go
queue/
order_events.go
The order package owns the business work. HTTP handlers turn requests into calls. Postgres code saves data. Queue code publishes messages. Each edge package does one job, then gets out of the way.
This matters when the product changes. Say you add a "reserve stock before payment" rule. If order logic sits in one feature package, you change a few files and move on. If half the rule lives in handlers, some in SQL helpers, and some in a shared service package, you spend an hour just finding the real flow.
Big shared packages are usually a warning sign. A package named common, shared, or helpers starts small, then every feature imports it. After that, changing one rule feels risky because the dependency chain reaches everywhere.
A good gut check is simple. If a new developer asks, "Where does creating an order live?" you should answer with one package, not five. When package borders match real work, Go code stays simple. It is easier to read, easier to change, and harder to break by accident.
Put interfaces where you use them
When one package needs help from another, the package with the need should define the interface. That package owns the contract. The storage or API package only implements it.
This keeps the direction clear. Your business code says, "I need these two or three methods," instead of importing a big repository type and bending the logic around it.
A checkout package is a good example. It may need to load a customer, save an order, and reserve stock. That is a small, clear contract. If you reuse a shared repository interface with ten methods, the package starts depending on details it does not use.
Small interfaces also make tests much less annoying. You can write a tiny fake with only the methods the use case calls. That usually takes a few minutes. Faking a large interface turns into busywork.
Return domain values from those methods, not database rows or ORM models. If the checkout flow works with Customer, Order, and StockReservation, return those types. Do not leak CustomerRow or OrderRecord into the application code. When the schema changes, the storage package should absorb that change, not every caller.
This style works best when interfaces stay close to the use case. The package that runs the workflow knows what it needs better than a shared interfaces folder ever will.
That top-level folder looks neat at first, then it fills up with vague names like Repository, Store, and Service. Soon unrelated packages depend on the same contracts, and simple changes get harder because too many parts share abstractions that are too broad.
Keep the rule boring:
- define the interface in the package that calls it
- keep the method set small
- use domain types in method signatures
- let implementation packages adapt to that contract
Code stays easier to read when each package asks for exactly what it needs and nothing more.
Keep transactions in the application layer
A transaction should cover one use case. No more, no less. If "checkout order" touches stock, payment state, and the order record, the application service should open one transaction and control it from start to finish.
Repository methods should not start and commit their own transactions behind your back. That feels convenient at first, but it breaks as soon as one use case needs several writes to succeed together. Then you get half-finished data and awkward repair code.
In practice, the flow is short: begin a transaction, create repositories bound to it, run the checks and writes for the use case, then commit only when every step succeeds. If something fails, roll back right away.
Keep sql.Tx out of the domain. Your Order, Invoice, or policy code should not know anything about database handles. Domain objects should hold business rules, not storage details. Once sql.Tx leaks into that layer, tests get noisy and package borders blur.
A cleaner shape is to let the application layer assemble transaction-backed repositories from the infrastructure layer. The application service already coordinates the work, so it can create orders, inventory, and payments repositories that all use the same transaction. The domain still sees plain methods like Save, Reserve, or MarkPaid.
A small example
Say a customer buys the last item in stock. The app layer starts a transaction, checks stock, stores the payment status, decreases inventory, and saves the final order state. If the stock check fails or the payment write returns an error, the service rolls back. Nothing stays half-written.
This style makes failures easier to reason about. You know where the transaction starts, where it ends, and who owns it. That plain clarity is usually the better choice.
A simple example: order checkout
Checkout code gets messy fast because it touches stock, orders, payments, and email in one user action. If one handler mixes SQL calls, a payment API call, and a mail send in random order, small failures turn into expensive support work.
A cleaner flow uses one application service to coordinate the steps. Repositories handle database work. The payment client and mailer stay outside the database layer.
A good checkout flow looks like this:
- Open one database transaction.
- Reserve the stock, create the order, and insert a payment record with a status like "pending".
- Commit that transaction.
- Call the payment provider after the commit.
That order matters. You reserve stock before charging the customer, so you do not take money for items you cannot ship. You also write the order and payment record together, so the database never ends up with one but not the other.
Keep the external API call outside the transaction. Payment providers can take a second, retry, or time out. If you hold the transaction open during that call, you keep locks longer than needed and raise the chance of conflicts.
After the payment call returns, the app opens a second short transaction. If the charge succeeds, it marks the payment as paid and the order as confirmed. If the charge fails, it marks the payment as failed and releases the stock.
Send the email only after that second commit succeeds. If you send "your order is confirmed" first and the commit fails, the customer gets a message about an order that does not exist. People remember bugs like that.
If you want this flow to stay readable, keep it in one checkout use case with small helpers. The transaction boundaries should be obvious when you scan the code. In plain Go, that usually beats hiding the whole process behind clever abstractions.
Build it step by step
Start with the work, not the folder tree. The cleanest package structure usually appears after you list the actual use cases you need to support. Write them down as actions: create invoice, cancel subscription, send reminder, sync stock.
That list gives you real borders. A package with no use case behind it often turns into a junk drawer later.
A good next move is to build one application service method for one flow. Keep the method narrow. If a user action has three outcomes and two side effects, put that logic in one place first, then see what dependencies it really needs.
For example, a CreateInvoice method may need to load a customer, save an invoice, and publish an event. That does not mean you need a big shared repository layer. It means this one method needs three small collaborators.
A simple order works well here:
- Write the use case method in the application layer.
- Define only the interfaces that method calls.
- Keep those interfaces close to the method that uses them.
- Put database code in a separate adapter package.
- Add a transaction only if multiple writes must succeed or fail together.
This order keeps the code honest. You do not guess abstractions up front. The use case pulls them into shape.
Small interfaces help more than broad ones. If CreateInvoice only needs FindCustomerByID and SaveInvoice, define exactly that. Do not add delete, list, update, or batch methods just because a repository might need them later.
Storage code belongs on the outside. Your Postgres or MySQL package can implement those interfaces without pushing SQL details into the application layer. That makes testing easier, and it keeps the architecture plain.
Use transactions with care. If the flow writes an invoice and an audit record that must stay in sync, open the transaction around the whole use case. If the method only reads data, or if two writes can safely happen apart, skip it. Too many transactions make code harder to follow and harder to change.
If you build in this order, your packages grow around real behavior. That usually gives you less code, smaller interfaces, and fewer rewrites later.
Mistakes that make the code harder to change
Most pain in Go code starts with a few habits that look clean at first. Later, they tie business logic to the database, the HTTP layer, or guesses about future needs.
One common mistake is creating one repository per table. That looks organized until one use case needs orders, payments, stock, and discounts in one flow. Then the application layer has to coordinate table-level pieces instead of asking for one business operation. If checkout needs to reserve stock and create an order, the code should reflect that work, not the schema.
A shared models package causes a different kind of mess. It saves time early on, but soon handlers, repositories, and business logic all depend on the same structs. Then one storage change leaks into API code, or an HTTP field sneaks into domain rules. Keep types close to the package that owns the behavior.
Opening transactions in HTTP handlers is another bad trade. A handler should decode input, call an application service, and write a response. If the handler starts a transaction, transaction rules spread into transport code. The same flow then gets copied into another endpoint, with slightly different error handling each time.
Letting domain code import database packages creates even more friction. Once domain code knows about SQL errors, query builders, or driver types, it is no longer plain business code. Tests get heavier, and simple rules start depending on infrastructure details.
The last trap is adding abstractions before they solve a real problem. You do not need a base repository, five interfaces, and a unit of work package on day one. Start with direct code. Add an interface when a package truly needs a seam. Add transaction helpers when more than one repository must succeed or fail together.
Go projects usually get messy one small decision at a time. That is why boring structure is a good sign. If a package is easy to explain, it is usually easier to change too.
Quick checks before you add a new package
Most Go projects do not fail because they have too few packages. They get messy because every new idea becomes a package before the code proves it needs one. A package should earn its place.
A new package makes sense when you can name its job in one short sentence. If you need a paragraph to explain it, the border is still fuzzy. "Handles order checkout" is clear. "Contains shared business helpers for checkout, pricing, and payment stuff" is not.
A package should also own one part of the work. If it pulls logic from several sibling packages just to finish a single use case, it probably cuts across the code in the wrong place. In a clean package structure, imports should mostly point inward to lower-level details, not sideways into a web of peer packages.
Before you create the folder, ask:
- Can I describe this package's job in one plain sentence?
- Does it own one slice of the flow instead of bits from everywhere?
- Can I test its rules with a tiny fake or stub?
- Do its imports avoid reaching across sibling packages?
- Can callers use it without knowing SQL tables, joins, or query strings?
That last check saves a lot of pain. If your application code has to pass raw SQL, table names, or scan rows, the package border is wrong. Callers should talk in business terms like FindOrder, SaveInvoice, or ReserveStock.
A small test helps too. If you can swap in a fake repository and test the rules in a few minutes, the package likely has a clear job. If the test needs a database, a transaction, and half the app booted up, the package is probably too tangled.
A simple example: do not make a discounts package just because two handlers call the same math. Make it a package only if it owns discount rules. Otherwise, keep the code near checkout and wait. Waiting a little usually leads to better package boundaries than guessing early.
What to do next
Start with one flow that already hurts a little. Pick something small but real, like creating an order, sending an invoice, or approving a refund. Move only that flow first. You will learn more from one careful refactor than from renaming half the repo in a weekend.
Keep the scope tight. Give the flow a clear application service, move data access behind interfaces where the code uses them, and make one place responsible for the transaction. If the change feels boring, that is usually a good sign. Plain Go code should stay plain.
A short checklist helps:
- refactor one use case from start to finish
- add a short package note for every new package
- check who owns the transaction before you merge
- rename vague packages early, before they spread
Those package notes matter more than people expect. Two or three lines at the top of a package can stop weeks of drift later. Write what belongs there, what does not, and which layer can call it. When names stay clear, new files usually land in the right place.
After each new feature, look at transaction boundaries again. Teams often start clean, then slip into passing transaction objects through three layers because it feels faster. That shortcut gets expensive. If one feature needs a wider transaction, make that choice on purpose and keep it in the application layer.
If your codebase is already large, do not wait for a full rewrite plan. Fix one path, copy the pattern, and let the old parts catch up when you touch them.
If you want an outside review, Oleg Sotnikov at oleg.is works with startups and smaller teams on Go architecture, package boundaries, infrastructure, and practical AI-assisted development setups. A short consultation can catch unclear structure before it spreads through the codebase.
Frequently Asked Questions
What does DDD-lite mean in plain Go?
It means you shape code around real actions like CreateOrder or Checkout, not around folders such as models and services. Keep rules, types, and workflow close together, and let HTTP, SQL, and queues stay on the edge.
Do I need aggregates, factories, and a full domain layer?
No. Start with plain structs, methods, functions, and small interfaces. Add a pattern only when a real problem shows up, because extra wrappers often hide the flow instead of making it clearer.
How should I split packages in a Go app like this?
Group code by feature or use case. An order package can own checkout, cancel, types, and contracts, while http handles requests and postgres stores data. If someone asks where order creation lives, you should point to one package.
Where should interfaces live?
Put them in the package that needs them. If checkout needs LoadCustomer and SaveOrder, define that small contract in checkout and let storage code implement it. That keeps dependencies narrow and tests simple.
What should repository methods return?
Return business values such as Order or Customer, not OrderRow or ORM models. When storage details stay inside the adapter, schema changes touch fewer files and your use case code stays easier to read.
Who should open and close database transactions?
Let the application service own the transaction for one use case. It can begin, call transaction-backed repositories, and commit or roll back. Handlers and domain types should not manage sql.Tx.
Should I call payment or email APIs inside a transaction?
Usually no. Write the local database changes in a short transaction, commit, then call the external service. Long network calls keep locks open and make failures harder to untangle. If the API result changes order state, open a second short transaction.
How do I know a new package is worth creating?
Create one when you can describe its job in one plain sentence and test its rules with small fakes. If the package pulls bits from everywhere or exposes SQL details to callers, wait and keep the code closer to the feature.
Can I test most rules without a real database?
Yes. Move decisions like discounts, permissions, and checkout rules into plain Go code, then fake the small interfaces around storage. You should need a real database only for adapter tests, not for every rule.
Do I need to rewrite the whole codebase to adopt this?
No. Pick one painful flow, refactor it end to end, and repeat that pattern as you touch nearby code. Small moves stick better than a repo-wide rename, and they show the team what good package borders look like.


