Database connection limits that stall growth before CPU
Database connection limits can block traffic long before CPU rises. Learn how pools, server caps, and background jobs create hidden queues.
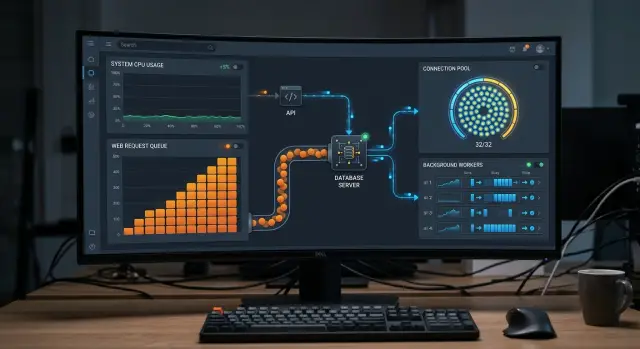
Table of Contents
Why users wait while the database looks idle
Users can hit a timeout while database CPU is low, disk is quiet, and query charts look almost empty. It feels wrong until you remember what happens before a query runs: the request has to get a database connection first.
If no connection is available, the request waits. Nothing heavy shows up on the database yet. No expensive query starts. CPU stays calm. From the user's side, though, the app is already stuck.
That is why database connection limits often hurt before the server looks busy. The bottleneck is not always query speed. Sometimes the real limit is the number of open slots between the app, its connection pool, and the database server.
A full pool can block traffic on its own. If your app allows 40 database connections and all 40 are busy, request 41 has to wait. If that wait lasts longer than the app timeout, the user gets an error even if the database spent that whole time doing almost nothing.
The quiet charts can hide a few different problems. Requests might be waiting in the app pool instead of inside the database. A small number of slow queries might hold connections longer than expected. Background workers might keep slots open and leave less room for live traffic. In systems with several app instances, each instance has its own pool, so the total connection count grows much faster than it seems.
Low CPU only tells you the database is not burning cycles. It does not tell you requests are flowing well.
This usually shows up slowly. Traffic rises, more app instances come online, and every instance opens its own pool. Small delays start to stack up. Login requests, checkout calls, or API responses slow down first. Then random timeouts appear under load and disappear when traffic drops.
The job is to find where connections run out. Check the app pool, the database cap, and any workers that share the same database. Until you find that choke point, a calm graph can be very misleading.
Where connections pile up
Connections rarely pile up in one obvious place. They spread across every process that talks to the database, which is why the total often surprises teams.
Start by listing every source of connections, not just the main app. Many teams count the web servers and stop there. The missing slots are often sitting somewhere quieter:
- web app instances behind the load balancer
- job workers and queue consumers
- cron jobs, imports, and report generators
- admin panels, support tools, and dashboards
- developer sessions, scripts, and deploy tasks
Each of these processes can keep its own pool. That detail matters more than most people expect. A pool of 10 sounds small until 10 separate processes each hold 10 connections. Now the database has 100 open sessions before a busy hour even starts.
Container setups make this worse. If you scale the app from two instances to six, you did not just add CPU. You may have tripled the number of possible database connections because every new instance started its own pool with the same defaults.
The math gets large fast. Four web instances with a pool of 20 can hold 80 connections. Six workers with a pool of 10 add 60 more. A reporting task, a migration runner, and a couple of admin sessions can push the total near 150 even if many of those processes are mostly idle.
That is why database connection limits often feel random. Traffic looks normal, queries look fine, and the database still refuses new work because too many quiet processes are sitting on slots. Count pools first. Then count queries.
How pools and server caps collide
A connection pool is the set of database connections each app process keeps ready. When a request arrives, the app grabs one of those connections instead of opening a new one from scratch.
The database server has its own hard limit. In PostgreSQL, max_connections sets how many open connections the server allows at once. When apps, workers, scripts, dashboards, and admin tools together ask for more than that number, new work waits or fails even if CPU stays low.
This is the collision that causes trouble. The app thinks, "I only need 20 or 30 connections." The database thinks, "I already handed out all my slots." Both settings can look reasonable on their own and still clash in production.
Idle connections make it worse. Even when a connection is doing nothing, it still holds a slot on the database server until the app closes it or the pool drops it.
A small scale-up often triggers the problem. One app instance with a pool of 20 might work fine against a database cap of 100. Then traffic grows, so you run four app instances, two worker processes, and a reporting job. Now the rough total looks like this:
- 4 web instances x 20 pool slots = 80
- 2 worker processes x 15 pool slots = 30
- reporting and admin work = a few more
Now the system can ask for 110 or 115 connections before the database has any breathing room. If Postgres still allows 100, some requests queue even though the queries themselves are fast.
Default settings cause a lot of this. Frameworks often ship with pool sizes that feel safe on one machine. Managed databases may reserve part of the total for internal work, monitoring, or admin access. Teams then add autoscaling, workers, and preview environments, but nobody recalculates the full connection count.
The result looks strange at first. CPU is calm. Memory looks fine. Query time may even look normal. Users still wait because the app spends time asking for a free connection, not running SQL.
This is why connection pool sizing deserves the same attention as server sizing. Pool settings are not local details. They multiply across every process you launch.
A simple example from a growing product
Picture a small SaaS app with three web servers and two background workers. Nothing about it seems large. The team still assumes the database has room because CPU stays under 25 percent most of the day.
Each web server has a pool set to 20. That gives the app 60 possible web connections.
Each worker has a pool of 15. That adds 30 more.
Now the total is 90. The database, though, has max_connections set to 80, and a few of those slots are best left for admin access and internal needs. In practice, the app may only have about 75 usable slots.
At first, traffic is light. Maybe only 20 or 25 connections stay active at once, so everything feels fine. Pages load quickly, jobs finish in the background, and the database dashboard looks calm.
Then the product grows. Morning traffic rises from 150 active users to 400. At the same time, background jobs start invoice exports, email batches, and sync tasks. Those jobs are not heavy on CPU, but they hold connections for 30 or 40 seconds at a time.
Now the balance changes. Web traffic wants 45 to 50 connections. Jobs grab another 25. A few slow queries linger. Suddenly the app is close to the real limit of 75 even though the database server still looks relaxed.
Users feel this first. A request arrives, but the web app cannot get a free connection from its pool. That request waits in line. After enough waiting, pages slow down or time out.
From the outside, it looks odd. CPU is fine. Memory is fine. Disk is quiet. Live traffic still stalls because the queue sits in front of the database, not inside the database engine.
That is why background jobs database load matters so much in a growing product. You can hit the wall long before the server looks busy.
How to find the bottleneck step by step
Users can hit a wall long before PostgreSQL runs hot. If the app waits for a free connection, CPU stays low and query charts look normal. To diagnose that, start with the limits and work outward.
- Write down the real connection budget. Start with
max_connections, then subtract room for admin access, monitoring, migrations, and anything else that should still work when the app is under pressure. - Count every process that can open connections. Include web instances, workers, schedulers, cron jobs, dashboards, scripts, deploy tasks, and temporary overlap during deploys.
- Compare the possible total against the safe database budget. Do not use average traffic. Use the highest replica count and the busiest hour you expect.
- Measure wait time before queries start. If requests spend 200 milliseconds or 2 seconds waiting before SQL runs, the problem is not the query yet. The app is queued for a connection.
- Check timing patterns. If connection spikes line up with deploys, retries, or batch jobs, you found the pressure point.
A small example makes this easier to see. Say the database allows 100 total connections, but only 80 are safe for the app. Four app instances each allow 12 connections, so that is 48. Three workers allow 10 each, so that is 30. You are already at 78. During a deploy, the old app instances may stay alive for a minute or two while the new ones start up. Even if traffic barely changes, the total can jump past the cap.
This is where database bottleneck diagnosis often goes wrong. Teams look only at query duration and CPU, then blame the database engine. The real issue sits one step earlier.
Keep notes by time, not just by service. A graph that shows connection count next to deploy windows, retry spikes, and scheduled jobs is often more useful than another CPU chart.
When background jobs steal slots from live traffic
A database can look calm on CPU and still reject user traffic if workers take too many connections. This is common in growing products because workers are easy to add and easy to forget.
The usual offenders are not page views. They are background tasks that wake up in batches and all ask for a connection at once. Imports, third party syncs, webhook retries, report generation, reindexing, invoice runs, and email campaign prep can all do it.
A single import job may look harmless. Ten workers running that import in parallel can fill the pool before real users even click anything. Retry storms are similar. If an external API fails for 15 minutes, workers may keep retrying old jobs while fresh user requests wait in line.
Sync jobs create another quiet drain. A product that pulls updates from a CRM, billing system, and warehouse every few minutes can keep steady pressure on connections all day. Each worker may hold a connection longer than a normal page load, especially if it reads a batch, writes rows, and then waits on network calls.
A few rules help a lot. Keep worker concurrency lower than web concurrency. Give heavy queues their own smaller pool. Process jobs in modest batches instead of giant chunks. Slow or pause retries when failure rates spike. Leave part of the connection budget unused on purpose so live traffic has room.
A good starting rule is simple: reserve about 20 to 30 percent of available connections for user requests during busy hours, and do not let workers compete for all of them. The exact number depends on the product, but the habit matters more than the percentage.
Batch size matters too. A batch of 100 rows often behaves better than 10,000 rows if each batch opens a transaction, writes, commits, and releases the connection quickly. Smaller batches usually make queues easier to predict.
If you run several worker types, treat them differently. Imports can wait. Checkout, login, and API reads usually cannot. The database does not know that on its own. You have to enforce that priority with separate pools, queue limits, and schedules.
Mistakes that make the queue worse
The most common bad fix is treating every timeout as a sign that the database needs more slots.
Raising max_connections in Postgres can help, but only when the server has enough memory and the workload is already under control. Every extra connection costs RAM. More active queries can also increase reads, locks, and cache misses. CPU may still look fine while response times get worse.
Another mistake is scaling app instances while leaving pool defaults untouched. One app server with a pool of 20 might be fine. Ten app servers with the same setting can ask for 200 connections before workers, admin tools, and migrations show up.
Long transactions cause a different kind of damage. If a request opens a transaction and then waits on a slow API call, a file upload, or report generation, that connection stays busy the whole time. Sometimes it also keeps locks open, so other queries wait behind work that is not even using the database.
Retry storms are worse. One timeout triggers a retry from the app, another from the job runner, and sometimes another from the client. The database gets hit by the same failing work again and again, so a short slowdown turns into a pileup.
A safer response is less dramatic and more effective. Count the total possible connections across web, workers, cron jobs, and admin tools. Check how many sessions sit idle in transactions or wait on locks. Lower pool sizes before adding more app instances. Add backoff and hard limits to retries so failures do not multiply.
If you fix one thing first, fix the part that holds a connection longer than needed. That is usually where the queue begins.
Quick checks before you change anything
Start with the math, not the graphs. A database can look calm on CPU and still refuse new work because every connection slot is already spoken for.
Write down the maximum each process can open at the same time. For example, five app instances with a pool of 20 can ask for 100 connections. Three workers with a pool of 10 add 30 more. A reporting tool might add another 10. If the database cap is 120, the system can ask for 140 connections before a single surprise query appears.
Then watch what happens after traffic drops. If idle connections stay high for minutes or hours, the app may be holding slots longer than it should. That usually points to pools that are too large, connections that do not return cleanly, or worker processes that stay warm all day and keep their slot just in case.
Long queries need their own review. One slow query does more damage than people expect because it keeps a slot busy the whole time. Ten queries that each run for eight seconds can block traffic more than a hundred fast queries that finish in 50 milliseconds.
Check the quiet tools too. Migrations, one off scripts, support dashboards, and internal reports often run outside the main app, so teams forget to count them. They still use the same server cap.
Finally, look at scheduling. If workers wake up at the top of the hour and grab most of the pool, live requests will wait even though nothing looks obviously broken. Leave space for the front door.
What to do next
Most database connection limits problems come down to simple math, not slow hardware. A pool of 20 looks harmless until you run six app instances, four workers, and a few scheduled jobs. Then a calm database can still refuse traffic because every slot is already taken.
Start with a hard count of who can open connections at the same time. Include web servers, background workers, cron jobs, migration tools, admin access, and anything else that talks to the database. If one service can scale out, count the highest replica count you expect during a busy hour, not the number you have today.
Then reset the limits on purpose. Set pool sizes from expected concurrent queries per process, not framework defaults. Reserve connection room for user requests first. Cap workers and batch jobs around that. Keep a small buffer for deploys, admin sessions, and emergencies. Write the numbers down so the app team and infra team use the same budget.
After that, test the settings under a realistic spike. Run the same mix you see in production: normal page loads, a burst of sign-ins, and the jobs that usually run at the same time. Watch connection wait time, queue growth, and refused sessions. CPU alone will miss the problem.
If the numbers still do not line up, get a second set of eyes before spending more on infrastructure. Oleg Sotnikov at oleg.is helps startups and small teams review pool sizing, worker limits, and database caps together as part of Fractional CTO and technical advisory work. A short review can uncover the real choke point much faster than adding more servers and hoping the problem goes away.
Frequently Asked Questions
Why do users time out when database CPU looks low?
Because the request may be waiting for a free database connection, not for the database to run SQL. Until the app gets a slot from its pool, the database has almost nothing to do, so CPU and disk can stay low while users still wait.
That is why calm charts can fool you. The queue often sits in the app or connection pool before the query even starts.
How can I tell if the app is waiting for a connection or running a slow query?
Measure the time before SQL starts. If a request spends a lot of time waiting and the query itself runs fast once it begins, you likely have a connection bottleneck.
Check app logs, tracing, or request timing around connection checkout. Slow query logs alone will miss this because they only show work after the app gets a connection.
What should I count when I estimate total database connections?
Count every process that can talk to the database at the same time. That includes web app instances, workers, cron jobs, report jobs, admin tools, deploy tasks, scripts, and developer sessions.
Then use the highest replica count you expect under load, not the average. Small pools add up fast when several processes each keep their own connections open.
Why do connection problems get worse after I scale the app?
Every new app or worker instance usually starts its own pool. When you scale from two instances to six, you do not just add compute. You also multiply the number of possible database connections.
That can push you past the server cap even when traffic looks normal. The app grows quietly, but the database runs out of slots much sooner than expected.
Are idle database connections actually a problem?
Yes, they can be. An idle connection still holds a slot on the database server until the app closes it or the pool drops it.
Too many idle sessions waste room that live traffic could use. If idle counts stay high long after traffic falls, your pools may be too large or some processes may hold connections longer than they should.
How should I split connections between web traffic and background jobs?
Reserve room for user traffic first, then fit workers around that budget. A simple starting point is to keep some headroom for logins, checkout, and API calls during busy hours and give heavy worker queues smaller pools.
Separate pools help a lot. Imports and reports can wait; live requests usually cannot. The database will not make that choice for you, so set limits on purpose.
Should I just raise max_connections in PostgreSQL?
Not first. Raising max_connections can help, but it also uses more RAM and can make response times worse if too many queries run at once.
Start with the math. Lower oversized pools, cap workers, shorten long transactions, and stop retry storms before you add more slots. Raise the server cap only when the machine has room and the workload is under control.
Which background jobs usually steal connection slots from live traffic?
Batch jobs, imports, retries, sync tasks, and reports often cause it. They may not burn much CPU, but they hold connections for a long time, especially when they wait on another API or process large chunks in one go.
Retry storms hurt even more. One failure can trigger the same work again from several places, and those repeated attempts fill the pool while fresh user requests sit in line.
What are the fastest checks to run before I change any settings?
Write down your real budget from max_connections after you leave room for admin access, monitoring, and deploys. Then compare that budget with the total possible connections from all app and worker processes.
After that, look for high idle counts, long transactions, and spikes during deploys or scheduled jobs. Those checks usually show the pressure point faster than another CPU graph.
What should I do next if connection limits keep causing random timeouts?
Start by setting pool sizes from real concurrency instead of framework defaults. Then test with a realistic spike that includes normal requests and the jobs that run at the same time.
If the numbers still do not make sense, bring in someone who can review the app pools, worker limits, and database cap together. That usually saves more time than adding servers and hoping the issue disappears.


