Daily operations view from system events for managers
Build a daily operations view from queue age, exceptions, and ownership data so managers spot blockers early and spend less time in status meetings.

Table of Contents
Why status meetings start running the day
Status meetings take over when the system does not show the truth fast enough. People fill the gap with memory, chat messages, and quick summaries. That feels normal for a while, but daily work slowly turns into a reporting exercise.
The first problem is simple: teams wait for verbal updates instead of checking facts. One person says an item is "in progress," another says it is "almost done," and nobody can see the exact step, the last real movement, or who touched it last. By the time the meeting ends, part of the update is already stale.
Large queues make this worse. A backlog with 300 items can look busy and healthy even when 25 of those items have sat untouched for nine days. Old work disappears inside the volume. Managers hear that the queue is moving, but they cannot see which cases are turning into risk.
Exceptions usually stay invisible the longest. Normal cases move, so the team talks about output and counts. Meanwhile, payment errors, missing approvals, bad addresses, or failed handoffs pile up in a corner until customers complain. Then the team reacts under pressure instead of fixing the pattern early.
Managers start chasing owners one by one. They send messages, ask for updates, and build a manual picture of the day from scattered replies. That wastes time and creates a bad habit: work moves because someone asked about it, not because the system showed it needed attention.
At that point, the meeting becomes the control system. The loudest issue gets attention. The clearest speaker sounds most prepared. Quiet, aging work keeps sitting there.
A small order team might spend 30 minutes every morning asking the same questions: What is blocked? Who owns refunds? Why are returns taking longer? Then someone opens three tools to answer one basic question about the oldest orders. That is the real signal. The team does not need more meetings. It needs a daily operations view that shows queue age, exceptions, and ownership before anyone starts talking.
What a manager should see every morning
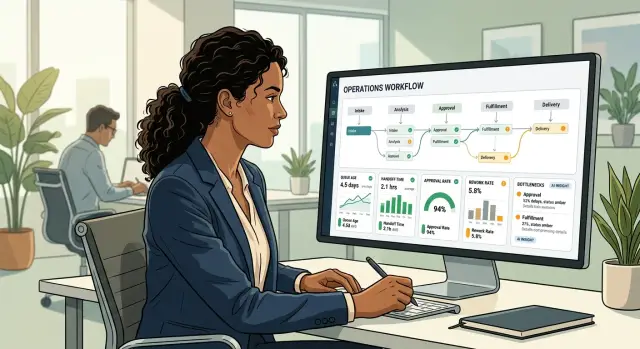
A manager does not need every event from yesterday. They need a short screen that shows where work is piling up, what broke overnight, and who needs help first. If that takes more than a few minutes to read, people go back to asking for updates in meetings.
Queue counts matter, but they are not enough. A queue with 200 items may be fine if work keeps moving. A queue with 12 items can be a problem if one case has sat there for 18 hours. That is why the age of the oldest item matters in every queue. Age shows pressure better than volume.
The same screen should separate fresh trouble from old noise. New exceptions since yesterday deserve attention because they show what changed. If the same error list appears every morning, people stop seeing it. A manager should be able to tell, at a glance, which exceptions appeared overnight and whether they block customers, finance, or internal work.
Movement matters more than activity
Most dashboards show activity because activity is easy to count. Managers need movement instead. They need to see what moved forward, what stayed still, and which items bounced around without closing. A case that changed owners three times is not progress. A case that left the queue is.
Ownership should sit next to the problem, not in a second report. When an item is stuck, the screen should show the current owner, when that owner last touched it, and whether the item is waiting on another team. That one detail removes a lot of wasted follow-up.
A useful morning view answers five questions fast:
- How many items are in each queue right now?
- Which item in each queue is oldest?
- What new exceptions showed up since the last review?
- Who owns the items that are stuck?
- What moved yesterday, and what did not move at all?
If a manager can answer those questions before the first call of the day, that call can focus on removing blockers instead of collecting status.
Choose the events that show real movement
A useful manager report starts with events that change the state of work. If nothing changed for the team, the event does not belong in the daily operations view.
Start with the moments that move an item forward or block it. In most teams, that means item creation, assignment to a person or team, status change, and closure. Those four events tell a clean story: an item entered the queue, someone took it, its state changed, and the work ended. That is enough to measure queue age, spot exceptions, and see who owns what.
Event names need discipline. One business action should have one event name every time. If one team sends "ticket_assigned," another sends "owner_set," and a third sends "picked_up," the report turns into cleanup work. Pick one name and stick with it. Boring names are fine. Clear names are better than clever ones.
Each event should carry the same basic fields: event time, item ID, current owner, and current status. Without time, you cannot measure age. Without item ID, you cannot join events into one timeline. Without owner and status, the manager sees motion but not responsibility.
Noise ruins trust fast. Skip events that do not change work, such as page views, record opens, refreshes, comments like "looking into this," or every minor field edit. Those events create volume, not signal. A manager does not need to know that five people opened the same order. A manager needs to know that the order sat unassigned for six hours.
A small order team shows the difference. "Order created" matters. "Assigned to Mia" matters. "Waiting for customer reply" matters. "Order page opened" does not. If the team keeps only the first three, yesterday's delays are obvious by 9 a.m.
Consistency across queues matters just as much as event choice. Orders, support cases, and approvals can follow different business rules, but they should still send the same base fields in the same format. If one queue sends owner names, another sends employee IDs, and a third skips status, the report breaks the moment you try to compare teams.
Pick fewer events than you think you need. If an event does not help answer "What changed, who owns it, and how long has it been there?" leave it out.
Turn raw events into queue age and ownership
Queue age only helps when the clock starts at one clear moment. Pick the event that means the item entered a working queue, not the first hint that it might exist. For an order, that could be "order submitted." For a support case, it might be "triage complete." If people argue about where age starts, the rule is still too vague.
The reset point matters just as much. Reset the clock only when the work enters a new queue with a new promise, not every time someone opens the record or leaves a comment. If an item moves from intake to finance review, a new queue age can start there. If a reviewer adds a note and keeps the item, the same clock should keep running.
Ownership needs the same discipline. Every handoff should create one event that says who owns the item now. That owner can be a person, a team, or a named inbox, but only one should count as current owner at any time. Without that rule, a daily operations view becomes a list of guesses.
In practice, the model is pretty small. You need to know when the item entered the queue, which event reset the queue clock, who owns it after the latest handoff, and whether it sits in normal flow or exception flow.
That last field matters more than many teams expect. Normal waiting and exception waiting should not mix. An item waiting for a customer reply, a missing document, or a fraud check may be late, but it is late for a different reason than an item sitting untouched in a team queue. Keep those states separate or managers will chase the wrong problem.
Owner names also need one source of truth. Pull them from a single roster, not from free text typed into tickets, spreadsheets, or chat. "Sam Lee," "S. Lee," and "sam.lee" should map to one owner record. The same goes for team names. Clean names sound boring, but they save hours of cleanup later.
Set these rules early and the numbers stay stable. Managers can see age, exceptions, and ownership without asking the team to explain every row by hand.
Build the daily view step by step
Start with the decisions a manager makes before lunch. If the screen does not help with those decisions, it is decoration. A good daily operations view answers a few repeated questions fast and uses the same layout every day.
Write down four or five questions managers actually ask in the morning. Keep them direct: what is waiting, what is getting old, who owns it, what broke, and what needs help now. That list should shape the whole view.
Then give each question one clear answer. Do not stack three charts around one issue. If the question is "What is stuck?" use one table with queue age by age band. If the question is "Who needs help?" use one ownership table with counts per person or team. If the question is "What failed overnight?" use a small exception panel with the total count and the newest cases.
A simple build order works well. Pick the few morning questions that lead to action. Match each one to a single metric, table, or count. Group work items by queue first, then by age band, then by owner. Add a small exceptions panel with count, newest item, and time opened. After a week, delete anything nobody uses.
The grouping matters. Queue first shows where work is piling up. Age bands show whether the pile is fresh or stale. Owner shows whether the issue is staffing, handoff, or follow-up. With those three cuts, a manager can spot a problem in seconds instead of asking for updates one person at a time.
Keep the exceptions area small on purpose. It should pull attention to unusual cases, not turn into a second dashboard. A short panel with counts by type and the newest few records is usually enough.
Review the screen after a week of real use. Ask one manager what they looked at first, what they ignored, and what sent them to Slack or email anyway. If a number never changes a decision, remove it. A daily operations view gets better when it gets smaller.
A simple example from an order team
An order team often starts with one intake queue. New orders land there, and most move forward without anyone talking about them. Trouble starts when payment fails, a billing address does not match, or a fraud check needs a second look. Those orders leave the normal flow and enter an exception queue.
A manager does not need a long status update to spot the problem. The morning view should show how many new orders entered intake today, how many orders sit in the exception queue, which items are older than 24 hours, and who owns each stuck case.
Picture a team that opens the dashboard at 8:30 each morning. The intake queue has 146 new orders. The exception queue has 11. Four of those 11 have been sitting for more than 24 hours, so they need attention before the day gets busy.
The manager clicks the old items and sees ownership right away. Two belong to Maya, one belongs to Jordan, and one has no owner at all. That last case is the one that would usually disappear until someone brings it up in the meeting.
Because the team can see age and ownership early, they act before the standup. Maya clears one order after a customer updates tax details. Jordan retries a payment after a bank delay ends. The unassigned case goes to Alex, who finds a broken rule in the payment check.
By the time the team meets, only one old item remains. The conversation changes. Nobody goes around the room saying, "I am working on this" and "I am waiting on that." The manager asks a smaller question: do we need to fix the payment rules, or do we just need to watch one customer case?
That shift matters. The work already moved before the meeting started. The meeting becomes a place for decisions, not a place where people discover the real status.
Mistakes that make the view hard to trust
Managers stop using a report the moment it feels unfair or confusing. One bad number can send people back to status meetings, spreadsheets, and side messages.
A common problem is mixing system errors with business exceptions. Those are different things. A failed API call needs a technical fix. An order waiting for customer approval needs a business action. If both show up as one red count, nobody can tell who should act first.
Ownership breaks trust just as fast. After a handoff, many teams leave the owner field blank or keep the old owner in place. Then a manager sees ten stuck items but cannot tell whether sales, operations, or support owns them. Blank ownership usually means the process design is incomplete, not that nobody is responsible.
Totals also hide the real problem. A queue with 120 items may be fine if 110 arrived this morning. The same total is a problem if 25 have been sitting for three days. Age bands make the view useful because they show pressure, not just volume. Even simple buckets like 0-4 hours, same day, 1-2 days, and 3+ days can change the conversation.
Reopened work often distorts the numbers. If the report counts the original item and the reopened item as separate cases, managers think the backlog grew when the same work simply came back for another pass. Count the current live item once, then track reopens as a separate measure. That keeps the view honest.
Old queues create another quiet failure. Teams change steps, rename statuses, or remove a review stage, but the report still shows the retired queue. After a month or two, nobody remembers what that number means. People either ignore it or argue about it.
A simple order-team example shows how this happens. Finance used to review every refund over $100. Later, the rule changed to $250, but the old finance queue stayed in the report. Managers kept asking why items sat there even though the process no longer used that path.
Good reporting needs regular cleanup. Separate technical failures from business holds. Require ownership after every handoff. Show age bands. Count reopened items once. Remove queues that no longer exist. If a manager can explain every number in one sentence, the report is ready for daily use.
Quick checks before you rely on it
A report can look polished and still send managers in the wrong direction. Before your team starts using a daily operations view to run the day, test whether it matches what is actually happening.
Pick five real items and trace them by hand from start to current state. Use recent work, not perfect examples. Check who owned each item, when it moved, when it stalled, and whether the timestamps in the view match the event trail.
That manual trace does two things fast. It catches broken logic, and it shows whether your event data tells a full story or only part of one.
Owner names need a separate check. Compare the names in the report with the live system your team uses today. Reassignments, team changes, and shared queues often expose bad joins. One wrong owner is enough to make a manager stop trusting the whole screen.
Then look at the oldest item in every queue. Old work is where reporting mistakes show up first. A ticket might look fresh because the last comment updated the timestamp, while the actual work has sat untouched for nine days.
Exceptions need even closer attention. Resolve one real exception, wait for the next refresh, and see what the view does. The item should leave the exception list or move clearly into a resolved state. If it stays stuck, your team will keep chasing ghosts.
A small test with a new manager is worth the time. Ask someone who did not help build the report to read it without help for five minutes. Then ask two direct questions: what needs attention today, and who owns it?
If that manager hesitates, the cause is usually simple. Labels are vague, queues are grouped in a strange way, or the view mixes status with action. Clean reports do not need a tour guide.
When these checks pass, status meetings get shorter for a good reason. Managers can start with real bottlenecks, not guesses, and the team can spend its time fixing work instead of explaining it.
What to do next
Start with one process that creates daily friction. Pick something people already talk about every morning, like orders waiting for approval or customer issues that bounce between teams. If you start with five processes at once, the daily operations view turns into another messy dashboard.
Run the view beside your current meetings for two weeks. Do not cancel the meetings on day one. Use that short trial to compare what the view says against what people report out loud. The gaps will show up fast, and that is useful. If queue age looks wrong or ownership keeps changing by hand, you will find the data problems before you trust the numbers.
A simple rollout usually works better than a big launch. Choose one process and one manager who will use the view every day. Set one clear manager action, such as stepping in when work sits unowned for more than 24 hours. Decide who fixes missing events when a handoff is not captured and who corrects bad ownership data when work lands with the wrong team. Then review mismatches every few days during the two-week trial.
Keep the manager rule plain. If an item sits in the queue for a full day without an owner, the manager assigns it or removes the block. That is enough to start. You do not need ten rules. One clear trigger is easier to follow, and people will actually use it.
Be strict about data ownership. Missing events and bad owner fields do not fix themselves. Name the person or team that maintains each one. If nobody owns data quality, people will drift back to asking for updates in meetings because the screen will feel unreliable.
If you want a second opinion, Oleg Sotnikov at oleg.is can review your event model and point out where queue age, exceptions, and ownership break down. That kind of outside review is useful when a team already has plenty of systems but still runs the day through status calls.
When the view matches reality for two weeks, cut meeting time in small steps and keep the rule simple.
Frequently Asked Questions
What is a daily operations view?
It is a short screen a manager can read in a few minutes each morning. It should show where work is piling up, what broke overnight, who owns stuck items, and what moved yesterday.
If people still need a meeting just to find the facts, the view is too noisy or too thin.
Why are queue counts not enough?
Counts show volume, not pressure. A queue with 200 items can be healthy if work keeps moving, while a queue with 12 items can hurt you if one case has sat there all day.
Show the age of the oldest item and age bands next to the total count. That tells managers where to act first.
What should a manager see first thing in the morning?
Most teams only need five answers in the morning: how many items sit in each queue, which item is oldest, what new exceptions appeared, who owns stuck work, and what moved or stayed still yesterday.
Put those answers on one screen. If a manager has to open three tools, people will go back to status calls.
Which system events should I track?
Track events that change the state of work. A simple starting set is item creation, assignment, status change, and closure.
Skip noise like page opens, refreshes, small edits, or comments that do not move the work. Those events make reports bigger, not better.
When should queue age start and reset?
Start the clock when the item enters a real working queue. For an order, that might be when someone submits it. For a support case, that might be after triage.
Reset the clock only when the item moves into a new queue with a new promise. Do not reset it for comments, page views, or tiny edits.
How should I handle ownership in the report?
Give every item one current owner at a time. That owner can be a person, a team, or a named inbox, but the rule needs to stay the same across the whole process.
Record every handoff as an event and pull owner names from one clean roster. If teams type names by hand, your report will drift fast.
Should I mix exceptions with normal queue work?
Keep normal flow and exception flow apart. An item waiting for a customer reply or a fraud check is not the same as an item sitting untouched in a team queue.
When you mix those states, managers chase the wrong problem. Show business holds, technical failures, and normal waiting as separate states.
What is the simplest way to build the view?
Start small. Pick one process that creates daily friction, write down the morning questions managers ask, and match each question to one clear table or metric.
A simple layout works well: group by queue first, then age band, then owner, and add a small exception panel. After a week, remove anything nobody uses.
What makes managers stop trusting the dashboard?
Trust drops when numbers feel unfair or confusing. Common problems include blank owners after handoffs, totals with no age bands, reopened items counted twice, and old queues that no longer exist.
Clean those up early. A manager should be able to explain every number in one sentence.
How do I test the view before I rely on it?
Trace a few real items by hand from start to current state. Check the timestamps, owners, queue changes, and exception handling against the event trail.
Then run the view beside your current meetings for two weeks. If the screen matches real work and helps managers act faster, shorten the meetings step by step.