Cursor pagination in admin tools that keeps back buttons working
Cursor pagination in admin tools keeps lists stable with filters, sorting, and deep links, even when records change between requests.
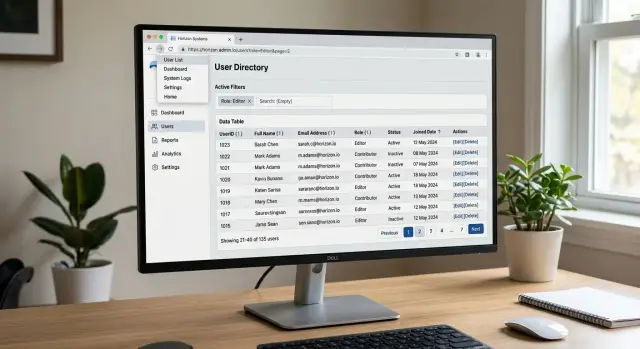
Table of Contents
Why the list jumps around
An admin list rarely stays still. New records arrive, people edit old ones, and some rows disappear. That constant change is why a simple "page 3" view often feels unreliable.
Imagine a support inbox sorted by newest first. You open page 2, review a few tickets, then open one ticket and hit the browser back button. While you were away, five new tickets came in. The records that used to sit at the top of page 2 may now be lower, and some records from page 1 may have slid onto page 2. The page number stayed the same, but the data did not.
Edits create the same problem. If the list sorts by "last updated," one changed record can jump to the top. If it sorts by priority, status, or score, a single field change can move a row to a different part of the list. You return to the list and see duplicates, missing rows, or both. Most users think the back button failed, but the list itself moved under them.
Deletes cause a quieter version of the same bug. One row disappears, everything below it shifts up, and the page now has a hole until the next request fills it with a different record. That sounds minor, but it breaks the feeling that the user is returning to the same place.
Page numbers make this worse because they point at a moving slice of a live list. They work fine for static content. They break down in busy admin screens where records change every minute. In those cases, "page 3" is not really a place. It is just whatever happened to be in that slot at that moment.
That is the problem cursor pagination in admin tools tries to fix. The goal is not only faster paging. The goal is a list view that still makes sense after inserts, edits, deletes, and a browser back button.
What a cursor should represent
A cursor should mark a spot in a sorted list. It should not mean "page 4" or "items 61 to 80". Page numbers drift as soon as someone creates, edits, or deletes a record. A boundary does not drift in the same way.
If the list sorts by "created_at" descending, the cursor needs the last visible "created_at" from the current batch. That tells the next request where to continue. On its own, though, that value is weak because many rows can share the same timestamp.
Add a unique tiebreaker, usually the record ID. Then the boundary is not "after 10:03:21" but "after 10:03:21, record 84721". That small detail prevents the classic bug where one row shows up twice and another row disappears.
One cursor, two directions
Moving forward and moving backward are different actions. Keep that explicit in your paging state. The "next" cursor should come from the last row on screen, while the "previous" cursor should come from the first row on screen.
Imagine an admin list sorted by newest first. If the screen ends with:
- created_at: 2026-04-12 10:03:21
- id: 84721
The next query should ask for rows older than that boundary, with a tie rule for equal timestamps. Going back should use the first row on the screen and reverse the comparison. Many teams fetch the previous set in reverse order, then flip it before rendering so the list still looks the same to the user.
A good cursor can be an opaque token, but it still needs clear meaning inside. It should carry the sort field value, the tiebreaker, and the direction. That is enough to resume from a stable point.
Treat the cursor as "start after this row" or "start before this row". Do not treat it as a page count, an offset, or a promise that the next screen will contain the same records forever. Records can change between requests. The cursor's job is simpler: keep the list moving through a stable order without duplicates, gaps, or broken back behavior.
Choose a stable sort order
A cursor works only when the list order stays predictable. If people can look at a table and guess why one row appears above another, they trust the list more. In many admin screens, sorting by created_at or submitted_at makes sense because users already think in that order.
Pick a sort field that matches the job people do on that screen. A support inbox often works best with newest tickets first. A review queue may work better with oldest items first, so staff can clear work in sequence.
Some sort fields look helpful but cause trouble. updated_at is a common example. A note, status change, bot action, or background sync can move a record while someone is paging through results. Then page 2 is no longer the same page 2, and the browser back button feels broken even when history itself works fine.
Use calmer fields for the default order:
created_atwhen records arrive once and then stay putsubmitted_atwhen the submit time matters more than later editspriorityonly if it changes rarely and people understand it
One more rule matters just as much: always add the record ID as the final tiebreaker. Two rows can share the same timestamp, especially after imports or bulk actions. If your query ends at ORDER BY created_at DESC, the database can return tied rows in a different order on the next request. Use ORDER BY created_at DESC, id DESC instead. That gives every record one exact position.
Keep the default order the same across sessions unless the user picks something else. People build habits around list views. If the same screen opens with a different sort on Monday than it did on Friday, they lose their place fast.
This is where stable list views begin. If the sort is easy to explain in one sentence and the ID breaks ties, your cursor has a solid base. If the order changes every few seconds, no paging design will save it.
Keep filters and search inside the paging state
A cursor only makes sense for one exact list view. If the user changes status, date range, owner, or search text, that old cursor points into a different result set. That is where duplicates, skipped rows, and empty screens start.
Put the full list state in the URL, not only the cursor. When the browser stores that state in history, the back button can restore the same view instead of a rough guess.
Keep these values together:
- sort field
- sort direction
- active filters
- search text
- current cursor
That bundle should travel as one unit on every request. If you keep sort in one place, filters in another, and the cursor in memory only, the list becomes hard to restore and even harder to debug.
Reset the cursor every time a filter changes. Reset it again when search text changes. Search is especially easy to get wrong because even one extra character can move many records in or out of the result set. Starting from the first page is the safe move.
The server should also defend itself. A request with a cursor from a different filter set should not pass quietly. You can embed a short fingerprint of the current sort, direction, filters, and search inside the cursor, or store that data next to the cursor token. If the incoming request does not match, reject the cursor and send the first page for the new state.
This rule matters even more in cursor pagination in admin tools, where people jump between saved views all day. A finance admin might search invoices by customer name, switch to overdue only, then hit back. If each history entry contains the full paging state, the screen returns to the same filtered list instead of showing a mixed or stale result.
Support deep links and browser history
A good admin list should survive refresh, copy-paste, and the browser back button. If someone opens a saved view tomorrow, they should land on the same filters, the same sort order, and the same place in the list as closely as the data allows.
For cursor pagination in admin tools, put the current view state in the URL. That usually means the sort field and direction, active filters, search text, page size, and the current cursor token. If your cursor already packs the last row's sort value plus a tie-break ID, you do not need separate URL fields for those internals. You do need the full token that the server can read again.
A URL like this is enough in most cases:
- sort=created_at.desc
- status=open
- q=refund
- limit=50
- after=eyJjcmVhdGVkX2F0Ijoi..."
That handles deep links. Back navigation needs one more piece. When the user moves forward, save each previous cursor in browser history state, not inside the current cursor itself. Then the back button can restore the earlier request directly instead of trying to reverse a token that only knows how to move forward.
Keep row selection separate from paging state. If a user clicks row 8472, that selection should not change the cursor or the page token. Treat it as its own bit of state, such as selected=8472, or keep it in local UI state. The list position and the chosen row solve different problems.
When the exact slice changes
Records will move. New rows arrive, old rows get edited, and some disappear. When a saved URL no longer points to the exact same slice, do not pretend nothing changed. Show a short note in the UI, such as "Results changed since this view was opened. Some rows may have moved."
That small note prevents a lot of confusion. It also tells the user that filters and sorting still worked, even if the page is not a perfect snapshot.
If you build it this way, a pasted URL opens the same view, refresh keeps context, and the browser back button feels normal instead of broken.
Build the request flow step by step
Treat the URL as the record of the current view. When the page loads, read the sort order, active filters, search text, and cursor from the query string before you touch the database. That gives you deep links that reopen the same view and lets the browser back button return to a real state, not a guessed one.
A clean request flow usually looks like this:
- Parse the URL into a paging state object. Keep it small: sort field, sort direction, filter values, search term, page size, and cursor.
- Validate every part of that state. Only allow known sort fields and filter names. If a value is invalid, replace it with a safe default or remove it.
- Run the query with a stable order, then ask for one more row than you plan to show. If the page size is 50, fetch 51.
- Return the visible rows plus cursor data for the next page and, when possible, the previous page. Build those cursors from the first and last visible rows in the current result.
- Update browser history only after the visible rows change. If a user types three letters into search but the result has not updated yet, do not push three history entries.
That extra row matters more than it seems. You keep the first 50 rows for display and use row 51 only to answer one question: is there another page? This avoids a separate count query and keeps the response fast.
Previous cursors need the same care as next cursors. A common pattern is to store the boundary row values from the current page, then run the same query in reverse when the user goes back. After that, reverse the rows again before you render them.
One small detail saves a lot of confusion: normalize bad inputs before you send the response. If the URL asks for an unknown sort field, return the corrected state and let the client replace the URL. People can then copy, bookmark, and reopen a clean deep link that behaves the same way each time.
Example: reviewing new support tickets
A support agent opens the ticket list with "billing" and "open" filters on, sorted by newest first. The first page shows the latest tickets, and the second page starts after a specific ticket cursor, not after "page 1" as a fixed bucket. That small choice is what keeps the view steady.
Now the agent moves to page two and starts reading a refund issue. While they work, a new billing ticket arrives. If the admin tool uses offset pagination, that new row pushes everything down by one. When the agent clicks the browser back button later, page two may contain a different set of tickets. One ticket disappears, another shows up twice, and the agent loses their place.
With cursor pagination in admin tools, page two still means "items after this last seen ticket in this sort order." The request keeps the full state together: the sort rule, the filters, and the cursor from page one. Because the sort stays stable, the second page still opens to the same ticket window even though newer tickets appeared above it.
The URL matters just as much. If the address bar keeps the current filters and paging state, the back button works like people expect. The agent can open a ticket, read it, then go back and return to the same list slice with "billing" and "open" still applied. A teammate can also paste that deep link into another tab and land on the same filtered window.
The UI should not silently reshuffle the list. A simple note works better: "3 newer tickets arrived." If the agent clicks it, the tool reloads from the top and shows the fresh items. If they ignore it, the current page stays unchanged.
That balance matters more than it sounds. Agents care less about seeing the absolute latest row every second and more about not losing context halfway through a review session.
Mistakes that cause duplicates and missing rows
Duplicates and gaps usually come from one bad assumption: that the list stays still between requests. In admin screens, it rarely does. New rows arrive, old rows change, and someone edits a status while another person is paging through results.
A common mistake is sorting only by created_at. That field often has ties. If ten records share the same second, the database can return them in a different order on the next request. One user clicks "next" and sees a row again. Another never sees one at all. Add a second stable field such as the record ID, and keep that full sort order inside the cursor.
Another easy way to break the list is reusing a cursor after the user changes filters or search. A cursor only makes sense for the exact result set it came from. If the user switches from "open" tickets to "closed" tickets, the old cursor points into the wrong slice of data. You should treat filter, search, and sort changes as a fresh list and issue a new first-page request.
Mixing offset pages with cursor pages causes quiet bugs. Teams sometimes keep offset for page 1 to support deep links, then switch to cursor for later pages. That sounds harmless, but the boundary between the two systems shifts when rows are inserted or removed. The user jumps from one paging model to another and the list no longer lines up.
Previous-page logic also goes wrong when people try to "reverse the query" without using the same ordering rules. If the forward query sorts by created_at desc, id desc, the previous query must use the same pair carefully, then reverse the returned rows before display. A random reverse query is how duplicates sneak in.
One more mistake is hiding updates with no notice. If records changed enough that the current window is no longer trustworthy, say so. A small note like "5 new records match this filter" is better than silently reshuffling the page. In cursor pagination in admin tools, honesty beats fake stability every time.
A short checklist helps:
- Use a stable tie-breaker in every sort.
- Invalidate cursors when filters, search, or sort change.
- Pick one paging model and stick to it.
- Build previous-page queries from the same ordered cursor data.
- Show users when fresh data may change what they see.
Quick checks and next steps
A paging system looks fine until the data moves under it. The last step is to test it like a real admin would, with new rows arriving, old rows changing, and a browser history stack full of list states.
Run one short session with network logs open. Keep the same filtering and sorting rules for a few clicks, then change the records between requests. Add one row that should land before the current page, edit one row so it no longer matches the filter, and delete one row from the middle. If the next page shows duplicates, skips a row, or breaks the browser back button, the paging state still leaks.
A short checklist catches most bugs:
- Insert, edit, and delete records between two clicks on the same list.
- Open a deep link in a new tab and compare the result with the original tab.
- Press back and forward several times in one session, including after a filter change.
- Log every rejected stale cursor with the sort, filter, and time that produced it.
- Decide what the UI says when a cursor expires. A plain message like "list changed, reload results" beats silent drift.
Manual testing finds the obvious failures. A few automated browser tests catch the annoying ones that return later. Recreate the same path every admin takes: open a list, apply filters, sort it, move forward, open a record, go back, then change the data under the list and repeat. Stable list views should survive that routine without surprises.
One more check helps: save a deep link, wait a bit, then open it in a fresh session. If the page loads a different slice of records, your cursor depends on hidden state that the URL does not carry.
If this logic keeps breaking, an outside review can save days of chasing edge cases. Oleg Sotnikov can review the paging model, request flow, and history handling as a Fractional CTO or advisor. When these checks pass, the list stops feeling fragile. Admins click less carefully, and that is usually the best sign you fixed it.


