CTO and COO automation roles that keep pilots on track
Clear CTO and COO automation roles help teams split process rules, system design, and rollout work so a pilot stays focused and easy to manage.
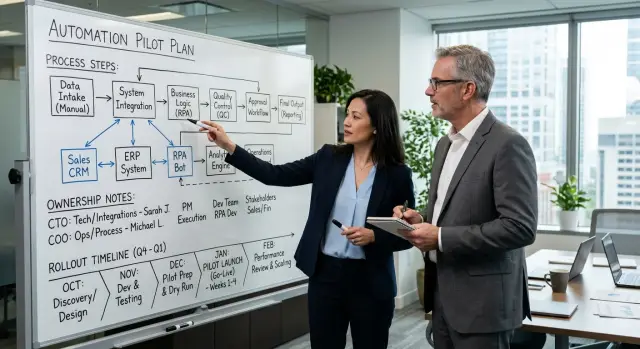
Table of Contents
What makes a pilot drift
Most automation pilots do not fail because the software is weak. They drift because the team mixes two separate jobs: deciding how the business should work and deciding how the system should support that work. Once those two blur together, every meeting changes both the process and the build.
It usually starts with a small exception. A manager says, "Can we also add one path for VIP clients?" An engineer says, "We can handle that in the workflow." A week later, nobody knows whether that rule came from operations, a one-off request, or a technical shortcut.
That is where ownership gets messy. The COO should own the process rules, the people involved, and the exceptions. The CTO should own how the system applies those rules in a stable, traceable way. If one person keeps changing both sides, the pilot stops being a test and turns into moving scope.
The early warning signs are usually obvious:
- The team argues about edge cases before it agrees on the normal process.
- Approval rules change, but nobody records who approved the change.
- New requests keep entering the pilot before the first test cycle ends.
- The rollout starts without a clear score for success.
Extra requests do more damage than most teams expect. Early pilots attract ideas because people finally see something working. That is useful later. During the first test, it ruins the baseline. If the team adds dashboards, notifications, or another approval path before one full cycle finishes, nobody can tell what caused the result.
Success measures matter just as much. Teams often say a pilot "looks promising," but that tells you nothing. Pick one or two numbers before rollout. If you automate invoice approval, success might mean cutting review time from two days to four hours or reducing manual touches from five to two. Then test that, and only that.
Ownership also needs to be written down. Who can change a business rule? Who can change the build? Who can pause the rollout? If those answers live only in conversation, the pilot will drift as soon as pressure rises.
What the COO should own
Clear ownership starts with the COO describing the work in plain language. That means writing the current process step by step, as people actually do it now, not as the policy manual says they should do it. Skip that step and the pilot turns into guesswork fast.
The process map should include the dull details people forget to mention: who starts the task, where approvals happen, what staff checks, and what happens when something looks wrong. For a first pilot, a five to ten step flow is usually enough. If the process needs three whiteboards to explain, it is too broad for round one.
The COO should also choose the first team and the first use case. That is a business decision, not a technical one. Start where the work happens often, the rules stay fairly stable, and the team lead wants to help. A finance operations team reviewing invoices is a much better pilot group than a mixed department with different habits and unclear ownership.
Business rules belong to the COO too. The COO decides what the system must do, what it must never do, and when a human has to step in. That includes exception paths such as missing information, unusual order size, a second approval requirement, or customer records that do not match.
The COO also defines what good daily use looks like before rollout. Keep it simple. Staff should use the tool every day, finish the task in six minutes instead of twelve, and send fewer cases back for rework. If people avoid the tool after week one, the pilot is not working, even if the demo looked smooth.
Training, policy updates, and feedback from staff stay on the COO side as well. A fractional CTO can help build the workflow, but operations still needs to tell people when the new process starts, what changes in their job, and where they should report friction. Staff usually tell operations the truth faster than they tell engineering.
The split is simple: the COO owns how work should happen.
What the CTO should own
On an automation project, the CTO owns the machine side of the work. The COO defines the process. The CTO turns that process into software, data flow, controls, and support that people can trust.
It starts with system design. The CTO decides where inputs enter, where outputs land, which system holds the source of truth, and where a human needs to approve a step. If two tools can edit the same record, the CTO should fix that before the pilot starts.
The CTO should also map integrations up front. That includes which systems connect directly, which ones need a buffer, and what access each tool or bot gets. Permissions matter more than teams think. A pilot can fail because a bot can see too much, or because nobody has the access needed to fix a stuck job.
Failure paths belong here too. If an API times out, a model returns the wrong format, or one system updates while the next one does not, the team needs a planned response before launch. Waiting for the first incident is how a pilot turns into fire drills.
Logging, alerts, and rollback steps are part of the same job. A demo can survive without them. A real pilot cannot. The team needs logs that show what happened, alerts that fire when jobs stall or error rates jump, and a quick way to pause or undo a change.
Lean teams are usually strict about this for a reason. Small teams do not have time to babysit fragile automations all day. That is also why advisors like Oleg Sotnikov at oleg.is put so much focus on observability and failure handling when they help companies move processes into AI-assisted workflows.
The CTO also has to estimate effort honestly. A workflow might take three days to build and five hours a week to support. That support load matters just as much as build time. It affects cost, staffing, and how much change the team can absorb.
Scope control often lands with the CTO as well. Once people see a pilot working, requests pile up fast. Someone has to say no. If the pilot handles invoice intake, it should not grow into vendor onboarding and reporting in the same sprint.
A good CTO does more than make the automation run. The CTO makes sure it fails safely, stays readable, and gives the business a clear answer about whether to expand.
Where both leaders decide together
Some decisions need both sides in the room. The COO knows how the work should run day to day. The CTO knows what the system can handle without creating new points of failure. A pilot stays on track when both leaders agree on a few shared decisions before real users touch it.
Start with one sentence that defines the goal. Make it specific enough that a manager, analyst, and engineer would all repeat it the same way. "Cut invoice approval time from two days to four hours for one finance team" works. "Improve operations with automation" does not. Vague goals invite extra requests and endless debates.
Rule changes also need a clear approval path. Many pilots drift because people keep adding exceptions after launch. Sales wants one path, finance wants another, and support adds a special case for one customer. Write down who can approve changes during the pilot. In many teams, the COO requests the rule change and the CTO decides whether the system can handle it safely before anyone switches it on.
Use one weekly scorecard. If operations tracks speed in one place and engineering tracks errors somewhere else, the pilot gets messy fast. Put the numbers together: cycle time, error rate, manual handoffs, user complaints, and downtime. When both leaders review the same page, the real problem is usually easier to spot.
The team should also agree on three decision points before launch:
- Stop if the new process creates more manual work than it removes.
- Fix if the goal still looks reachable but one rule, handoff, or integration keeps failing.
- Expand if the team hits the target for a set period and users can follow the flow without daily help.
That is where the overlap works best. The COO protects the business rule. The CTO protects the system design and rollout pace. Every weekly review should end with one plain answer: stop, fix, or expand.
How to run the pilot
Start with one process that happens often, hurts enough to fix, and involves a small group of people. Try to automate three workflows at once and people will mix problems together until nobody knows what failed. A pilot works better when one team can use it every day and give direct feedback.
Before anyone designs screens, bots, or approval flows, write the rules in plain language. Who starts the process? What data has to be present? When does work stop? Who can override the result? Keep the document short, but make it clear enough that two people would make the same decision from it.
A simple order works well:
- Pick one process and one team.
- Write the business rules and exceptions.
- Build the smallest version that can do the job.
- Launch it to a limited group.
- Review results every week and cut the extras.
This is where many pilots stay clean or start to drift. Teams often rush into a polished interface because it feels like progress. Usually it creates rework. If the rules are weak, the tool will only make bad decisions faster.
Once testing starts, do not spend all your time on the easy path. Use messy cases: missing fields, duplicate requests, late approvals, wrong inputs, and people who skip steps. Real work is full of that stuff. If the pilot only passes clean test data, it is not ready.
Launch to a small group first, even if the build looks stable. Ten real users teach you more than a room full of opinions. They also show where people ignore the tool, work around it, or keep asking for one more rule.
Set a fixed weekly review with the COO and CTO. Keep it short and blunt. Ask where people got stuck, which rule caused confusion, what manual workaround appeared, what nobody used, and what you can cut this week.
Cut extras fast. A pilot is not the place for nice-to-have ideas, custom views for every manager, or reports nobody checks. Tight scope keeps the rollout honest and makes the next decision much easier.
A simple example: invoice approval
Invoice approval is a good first pilot. It happens often, people already know the steps, and errors cost real money. That makes ownership easier to see.
The COO owns the process rules. That includes deciding which invoices move quickly, which ones need a second review, and how long each step can wait. A routine invoice under a set amount might go to one manager. An invoice from a new vendor or one with a price mismatch might go to finance for review within four hours.
The CTO owns the system around those rules. That means making sure invoices enter the process in a clean format, route to the right person, and leave a traceable record behind. It also means adding alerts so the team knows when an approval sits too long or when someone handles the task by email or chat instead of using the workflow.
After a week or two, both leaders should look at the same small set of facts: which invoices missed the response target, which ones people moved by hand, where routing picked the wrong approver, and which exceptions kept showing up.
That review matters because the same symptom can point to two different problems. Maybe the rule is wrong and the COO needs to change it. Or maybe the rule is fine, but the form is confusing, the alert arrives too late, or the log is too thin for the CTO to trace the issue quickly.
That is one reason outside technical advisors often start with a workflow this plain. Boring work makes drift easy to spot. If managers keep approving the same vendor outside the system, or finance keeps editing the same fields by hand, fix that first. Do not expand into purchase orders, expenses, and refunds just because the dashboard looks busy.
Mistakes that blur ownership
A pilot goes off track when people cross lines without saying so. The COO owns the process rules. The CTO owns the system design. When either side starts changing the other side's part during a busy week, the team loses its baseline.
One common mistake is engineers rewriting business rules on the fly. They see an odd case, patch it quickly, and move on. It feels helpful in the moment, but it changes the operating policy without approval. Before long, the software reflects developer judgment instead of the way the business wants to work.
The same thing happens from the other direction. Operations teams often add new cases during rollout week because real work is messy and everyone wants the tool to cover everything at once. That turns a small pilot into a moving target. The COO should decide which exceptions matter now. The CTO should say what the current design can handle without turning the pilot into a rebuild.
Another mistake is measuring output while ignoring adoption. A dashboard may show faster processing or fewer manual steps, yet staff still avoid the tool, keep side spreadsheets, or ask managers to do work for them. If people do not trust the workflow, the numbers can look good for a week or two and then fall apart.
Training gets skipped more often than teams admit. Leaders roll out the tool, assume people will figure it out, and then blame the product when errors rise. Most of the time, staff are not resisting automation. They just do not know what changed, when to use it, or what to do when it fails.
Support gets ignored too. Teams often call the pilot done as soon as the first workflow runs. That is too early. Keep the pilot open until the team can handle routine issues without panic, support questions start to drop, and the exception paths are clear.
If rule changes show up in chat instead of a decision log, rollout week adds more scope than planned, usage stays low while dashboards look fine, or support tickets pile up right after leaders announce success, the pilot is not stable yet.
Checks before you expand
Do not expand a pilot because one demo went well or one quiet week looked good. Expand when the work around the automation feels clear, repeatable, and a little boring. That is usually the best sign that the team has real control.
Start with rule ownership. Every rule question needs one person who can answer it right away. If an order comes in with missing data or a request breaks the normal approval limit, the team should know exactly who decides. Often that is the COO, but the main point is speed and clarity.
Staff also need a simple line for when to use the new flow. People should not guess. A short rule such as "use the automated path for standard renewals, send unusual cases to manual review" is enough if everyone understands it and follows it the same way.
The technical side needs the same clarity. The team must spot failed runs quickly, not during the weekly review. If a sync breaks, a task stalls, or a handoff drops data, someone should see it fast and know what to do next. The CTO usually owns that setup, even when an outside fractional CTO helps design it.
Keep the manual fallback alive and easy. This is where many pilots look stronger than they really are. When the automation fails, staff should still be able to finish the task by hand without panic, customer confusion, or long delays. If the fallback lives only in one person's head, you are not ready to expand.
Then look at the results over several weeks. One good afternoon proves almost nothing. Compare the new flow with the old one using plain measures: time to finish the work, number of errors, amount of rework, and how much attention the process needs from staff.
If the new flow wins week after week, expansion makes sense. If ownership is fuzzy, failures stay hidden too long, or the manual path already feels chaotic, stop and fix that first. More volume will not solve those problems.
What to do after the pilot
After a pilot, teams often jump straight to the next idea. That is when the same confusion starts again. If you want the next rollout to move faster, keep the decisions you just made in writing and keep them current.
Update two things first: the rule document and the system map. The rule document should show how the process works, who can make exceptions, and what counts as a correct result. The system map should show which tools touch the process, where data comes from, and where people still step in by hand.
Do not treat those documents as cleanup work. If the COO changes an approval rule or the CTO changes an integration, write it down that week. Small edits save the next project from starting with old assumptions.
Before you automate another process, score it with a few basic questions:
- How often does the task happen each week?
- How clear are the business rules?
- How messy is the data or handoff between tools?
- How much time or error does the current process create?
- How risky is a mistake if the automation fails?
A process that happens every day, follows clear rules, and wastes staff time is usually a better next step than a rare edge case. That keeps automation tied to business value instead of whoever talks first in the meeting.
Keep the same split on the next rollout unless you have a strong reason to change it. The COO owns the rules, exceptions, and adoption. The CTO owns the design, integrations, reliability, and support plan. Shared decisions stay shared, but day-to-day ownership should stay clear.
If ownership still feels fuzzy after the pilot, get a short outside review. A fresh pair of eyes can usually spot where process rules are bleeding into technical choices, or where the system design is quietly forcing a business rule nobody approved.
For a small team, that review does not need to be heavy. Oleg Sotnikov does this kind of work through oleg.is, helping companies line up process rules, system design, and rollout before they scale the next phase. A short review now is usually cheaper than cleaning up a larger mess a few months later.
Frequently Asked Questions
Who should own the process rules in an automation pilot?
The COO should own the process rules. That includes the normal steps, the exceptions, who can approve changes, and when a person must step in. If engineers start changing rules on the fly, the pilot loses its baseline fast.
What should the CTO own during the pilot?
The CTO owns system design, integrations, permissions, logging, alerts, and rollback. The job is not only to make the workflow run, but to make failures easy to spot and safe to handle.
How do we stop a pilot from drifting?
Start with one process, one team, and one clear goal. Freeze extra requests until the first test cycle ends, and log every rule change with the person who approved it. That keeps cause and effect visible.
What should we measure first?
Pick one or two numbers before launch. Good first measures include cycle time, manual touches, error rate, or rework. If you track too much in round one, people argue about reports instead of results.
When should we add exceptions or extra features?
Wait until the pilot completes a full cycle and you understand the baseline. Early extras such as new dashboards, another approval path, or custom views make it hard to tell what changed the outcome.
How small should the first pilot be?
Keep it narrow enough that one team can use it every day and give direct feedback. A five to ten step process with stable rules usually works better than a broad workflow that needs several departments to agree at once.
What if staff keep working outside the tool?
Treat that as a real signal, not a training problem by default. Check whether the rule is confusing, the form is awkward, the alerts arrive too late, or the manual path feels easier. Fix the reason people avoid the flow, then measure usage again.
Do we need a manual fallback?
Yes. When the automation stalls, staff still need a simple way to finish the work without panic or long delays. Write that fallback down and make sure the team knows when to use it.
How do we know whether to stop, fix, or expand?
Review the same scorecard every week. Stop if the pilot adds more manual work than it removes, fix if one rule or integration keeps failing but the goal still looks reachable, and expand only after the team hits the target for several weeks.
When does it make sense to bring in an outside advisor?
Bring one in when ownership feels fuzzy, rule changes pile up, or the team cannot tell whether the problem sits in operations or in the build. A short review can separate business decisions from technical ones before a small mess grows.


