C++ modules in a service stack without rewriting old code
Use C++ modules in a service stack by wrapping legacy libraries behind clear interfaces, cutting risk and keeping proven code in place.
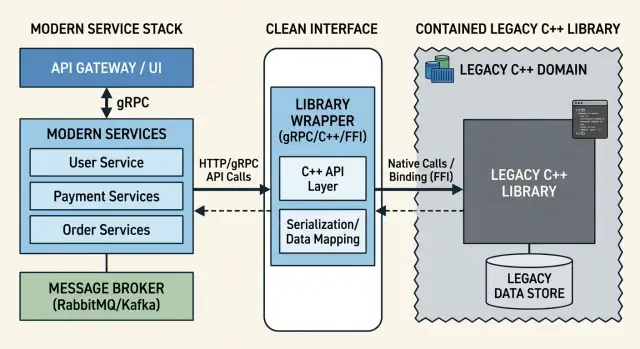
Table of Contents
What goes wrong when old C++ meets new services
Old C++ code can run for years without trouble, then start causing chaos the moment several newer services call it in different ways. The library itself may still be solid. The trouble starts at the edges.
A lot of legacy code carries assumptions that never got written down. It may expect one caller at a time. It may keep state in global objects. It may return raw pointers, use custom allocators, or depend on build flags that only one team remembers. None of that looks scary when one old application owns the code. It gets scary when five services, two languages, and a new deployment pipeline all touch it.
Memory bugs are a common first surprise. A library can look stable because the original app always freed objects in the right order. A new service may not. Then you get slow leaks, rare crashes, or corrupt data that shows up hours later. Threading issues hide the same way. Code that behaved well in a single process may fail once modern services call it in parallel.
Build and runtime quirks cause quieter damage. One team compiles with one standard library, another uses different flags, and a third packages the dependency inside a container with missing system pieces. Now the same function behaves a little differently depending on who shipped it. Those bugs waste days because they do not fail in one clear place.
The bigger problem is ownership. When many teams call old code directly, nobody owns the boundary. Each team adds its own checks, patches, and workarounds. Small changes start to feel dangerous, not because the code is always bad, but because the rules around it are scattered. One team changes an input shape, another assumes old error codes, and a third retries requests that should never be retried.
That is why C++ modules in a service stack often fail before the code itself fails. The system lacks a narrow, controlled entry point.
A wrapper fixes that in a practical way. It gives one place to validate inputs, limit concurrency, translate errors, and hide memory handling behind a simpler interface. If the old library returns ten failure modes, the wrapper can reduce them to three outcomes a service team can actually use. If only one component talks to the library, changes stop rippling across the whole stack.
Think of a document parsing library that has worked since 2014. It may still parse documents well. But if every service calls it directly, each service also inherits its sharp edges. A wrapper lets the parser stay proven code while the rest of the stack gets cleaner contracts and fewer surprises.
When wrapping beats a rewrite
A full rewrite sounds clean on paper. In real teams, it often burns time and reopens bugs that production code solved years ago. If an old C++ library already handles strange inputs, ugly edge cases, and awkward timing issues, that is hard-won behavior. Throwing it away just because the rest of the stack changed is usually a bad trade.
This is where C++ modules in a service stack make sense. The old library keeps doing the hard part, while a wrapper gives new services a small, predictable interface. That wrapper can validate input, convert odd return codes into clear errors, and hide unsafe details like raw pointers, globals, or stateful setup rules.
A rewrite also asks the team to prove parity with code they may not fully understand. That sounds manageable until someone finds a rule buried in a ten-year-old branch that only runs for one customer, one region, or one rare data shape. Then the rewrite slows down, the deadline slips, and the team still has two systems to compare.
If the business needs results this quarter, wrapping is often the honest choice. New services usually do not need the whole library. They need a narrow slice of it: maybe pricing, parsing, image processing, or device communication. A smaller surface gives you most of the safety gain without betting the schedule on a perfect reimplementation.
Wrapping wins when a few conditions are true:
- The library already works in production and fails in known ways.
- The tricky logic lives inside code that nobody wants to re-learn under pressure.
- New services need only a few operations, not the whole API.
- The team can test a wrapper faster than it can prove a rewrite is correct.
This comes up a lot in small teams. A fractional CTO or staff engineer may inherit a proven C++ engine while the rest of the company moves to Go, Python, or Node.js services. Rewriting the engine might take months. Wrapping it behind a strict interface can take days or weeks, and the rollback plan is much simpler.
A good wrapper changes the conversation. The team stops asking, "How do we replace everything?" and starts asking, "What is the smallest contract new services need?" That shift matters. It keeps proven code where it belongs and puts the safety work at the boundary, where new bugs are easier to see, test, and fix.
Choose the boundary first
Start with one business task, not a pile of classes. If an old library calculates prices, converts files, or checks permissions, make the wrapper own that one job and nothing wider.
This matters because teams often draw the boundary around the code they already have. That usually creates a thin shell that leaks old design problems into new services. A better boundary follows the outcome the business cares about.
For C++ modules in a service stack, a good first boundary sounds plain: "create a quote," "validate a document," or "generate a report." If the sentence sounds like something a product manager would understand, you are close.
Write the contract before you write the wrapper. Keep it short, but make it precise.
- What input does the caller send?
- What result should the caller get back?
- Which failures can happen every day?
- Which failures mean the old library is in a bad state?
- How should timeouts or retries work?
This step saves time later. When the request and response are clear, the wrapper stops being a mystery box and starts acting like a normal service.
Failure cases need the same care as happy-path results. Do not return vague errors like "failed" or pass through obscure internal codes that only the old team understands. Map them to a small set of named outcomes such as invalid input, not found, busy, timeout, or internal error.
Keep the hard C++ parts inside the wrapper. Other services should not care about raw pointers, custom allocators, templates, thread affinity, or which thread must call cleanup. Those rules belong to the adapter layer, where one team can control them.
That also means the wrapper should own memory and lifetime rules. Callers ask for work and get a result. They should not guess who frees a buffer, how long an object stays alive, or whether two calls can run at the same time.
Expose plain data types at the boundary. Use simple fields with clear names: strings, numbers, booleans, lists, and small enums. If another service reads the contract and needs a C++ expert to understand it, the boundary is still too close to the old code.
A quick test helps. Give the interface to a teammate who has never touched the legacy library. If they can explain the request, the response, and the error cases in a minute, the boundary is probably in the right place. If they start asking about pointers or template types, pull the line back inside the wrapper.
Build the wrapper step by step
Start with a narrow promise. New services usually need far less from an old library than the original codebase does. If the library has 40 public functions, your service may only need three of them. Write those down first, in plain language, before you write any code.
That small list becomes the contract for your adapter. It also stops a common mistake: exposing the whole legacy API again under a new name. If you do that, you keep all the old confusion and add new code on top of it.
A practical sequence looks like this:
- Pick the few actions the service actually needs, such as "price an order" or "validate a file".
- Define simple request and response types that match service data, not internal library structs.
- Write an adapter that translates those types into the old library calls.
- Map every failure to a short, consistent error code and message.
- Put tests around the adapter before any production route starts using it.
The adapter should do boring work well. It converts JSON fields, enums, timestamps, and IDs into the shapes the library expects. Then it converts the result back into a service response. Keep business decisions out of this layer when you can. If the wrapper starts copying half the old rules, you are building a second system by accident.
Error handling needs extra care. Legacy libraries often return a mix of nulls, integers, exception types, log lines, and special strings. A service cannot work with that mess for long. Pick one error format and stick to it. For example, return codes like invalid_input, timeout, not_found, and internal_error, with a short message that helps support teams and logs.
Tests should focus on the boundary, not on every detail inside the old library. Write cases for valid inputs, bad inputs, edge values, and ugly failures. If the library crashes on malformed data, the adapter test should prove that the service still returns a controlled error. That is where teams gain safety.
In C++ modules in a service stack, this boundary matters more than the module syntax itself. A neat module layout helps, but the real win comes from one stable interface that the rest of the system can trust.
Rollout should stay small. Move one route, one worker, or one scheduled job to the wrapper. Watch logs, latency, and failure counts. Fix rough edges, then move the next piece. Oleg Sotnikov often pushes this kind of stepwise change in startup systems because it cuts risk and still moves fast. You keep proven code where it still works, and you put a safer door in front of it.
A simple example
A company has a pricing engine written in C++. It came from an older product, and the team leaves the pricing rules alone because they still produce the right quotes. The problem is not the math. The problem is access. A new web app and a mobile app both need pricing, and direct library calls would spread C++ build issues, memory risks, and platform quirks into more parts of the product.
So the team puts a small quote service in front of the engine. The service does one job. It accepts a few plain inputs, calls the old library, and returns a clean result. Other teams talk to the service, not to the library.
What the contract looks like
The request can stay simple:
{
"sku": "PRO-12",
"region": "EU",
"customerType": "business",
"quantity": 25
}
And the response can stay just as clear:
{
"currency": "EUR",
"unitPrice": 19.80,
"totalPrice": 495.00,
"ruleVersion": "2024-10"
}
That contract hides the old internals. The web app does not care which compiler built the engine. The mobile app does not need C++ headers or special runtime handling. They send a request, get a quote, and move on.
Inside the service, the wrapper stays thin. It converts the incoming request into the format the pricing engine expects, calls the old code, checks for errors, and turns the result into a response the rest of the stack can trust. The rules stay in one place. The risky parts stay contained.
A setup like this lets the team change the outer stack without touching the pricing logic. They can move the frontend to a new framework, add mobile support, put the service in containers, or add logging and rate limits. None of that forces a rewrite of the engine.
This is the practical side of C++ modules in a service stack. The team keeps proven code where it belongs and draws a firm boundary around it. That boundary is often more useful than a full rewrite, especially when the old library has years of pricing fixes baked into it.
One detail matters a lot: the service contract should use business names, not C++ names. "quantity" and "region" are clear. Internal structs, pointers, and template types should never leak out. If they do, the wrapper stops being a wrapper and starts dragging old problems into new code.
That is why teams often choose to wrap legacy C++ libraries instead of replacing them right away. The pricing engine keeps doing its job. The service gives the rest of the product a safer, simpler way to use it.
Mistakes that create new risk
Most teams do not get hurt by the old library itself. They get hurt by a messy boundary around it.
That usually starts when developers export legacy headers, macros, and types into every new service. At that point, the wrapper is only a thin costume. The old code still controls memory rules, error handling, and build quirks across the stack.
If you want safer C++ modules in a service stack, keep the interface small and boring. New services should see plain request and response types, not twenty years of internal headers.
A second mistake is easier to miss. The wrapper keeps growing until it becomes a second copy of the old system.
That happens when the adapter starts owning config parsing, caching, logging rules, state management, and half the business logic. Now nobody knows where a bug lives. One team debugs the library, another debugs the wrapper, and both are partly right.
Keep the wrapper narrow. It should translate types, manage calls, handle errors, and expose a stable interface. If it starts acting like a product on its own, cut it back.
Splitting business rules across both sides creates even more trouble. A pricing rule, eligibility check, or rounding rule should live in one place at a time. If the legacy library applies one version and the wrapper adds a "temporary" fix, outputs drift quietly.
That kind of drift is nasty because tests may still pass in small cases. Customers find it first.
Operational mistakes show up fast
Teams often treat wrapping as a code problem and skip service behavior. A library call inside one process feels fast and predictable. A service call is different.
You need clear choices for:
- timeout limits
- retry rules
- fallback behavior
- error codes clients can act on
If you skip those choices, a slow legacy call can tie up worker threads, trigger duplicate requests, or return partial data that looks valid.
One more mistake causes chaos during release: changing build tools, public APIs, and business logic in the same deployment. When that goes badly, nobody can tell whether the fault came from the compiler, the transport layer, or the new rule change.
A safer pattern is dull on purpose. First wrap legacy C++ libraries without changing behavior. Then lock down tests around current outputs. After that, update build settings or module boundaries. Move product logic later, in a separate release.
A small example makes this obvious. If a checkout service starts using an old shipping calculator, do not switch the build system, replace the API shape, and adjust surcharge rules on the same day. Keep the first release boring. Boring releases are easier to trust.
Quick checks before release
A wrapper is ready for production when the team can explain it plainly, test it under stress, and back out safely if it misbehaves. If any of those parts feel fuzzy, the release is early.
Start with the shortest test of all. Ask one engineer to explain the interface in under a minute. They should be able to say what goes in, what comes out, what errors mean, and what the caller must never do. If that takes a whiteboard and ten caveats, the boundary is still too messy.
Logs matter just as much as code. When a request fails at 2 a.m., nobody wants to read raw C++ traces for half an hour. The service log should show a request ID, the operation name, the result, the time spent, and a clear failure reason. Keep private data out of logs, but leave enough detail so the team can tell the difference between bad input, a timeout, and a library bug.
Load tests should try the annoying cases, not only the happy path. Run normal traffic, then slow the library down on purpose. Add short spikes. Hold some calls open longer than usual. Old code often works fine at average load and then falls apart when one slow call blocks a pool, fills a queue, or pushes retries into a loop.
Rollback needs the same level of care. If the new wrapper writes data in a new format, make sure the old path can still read it, or keep the old format until the release settles. If the wrapper changes side effects, such as billing, message sending, or state transitions, prove that the team can turn it off without duplicate actions or lost records.
A small release checklist helps:
- One person can explain the interface, inputs, outputs, and failure rules in plain language.
- Logs show request, result, timing, and failure reason with stable IDs.
- Load tests include slow calls, retries, queue pressure, and traffic spikes.
- Rollback works without losing data or repeating side effects.
- One team owns bug fixes, version bumps, and library changes after launch.
That last point saves a lot of pain. Shared ownership sounds polite, but it usually means nobody fixes the wrapper fast. Pick one team. Give them the pager, the version plan, and the final say on interface changes.
This is the sort of release discipline Oleg Sotnikov pushes in AI-first and mixed-stack systems: keep the interface small, make failures obvious, and keep recovery boring. Boring releases are the goal.
What to do next
Start small. In most teams, the fastest win with C++ modules in a service stack comes from one painful library, not a broad cleanup plan. Pick the library that slows releases, breaks builds, or makes every new service harder to ship.
Do not add features yet. First, draw a narrow interface around that library and freeze it for the first release. If the team changes the wrapper every week, nobody learns where the real boundary should be.
A short checklist keeps this practical:
- Choose one library with clear business value and frequent friction.
- Define the smallest interface that the service actually needs.
- Keep the old code inside the wrapper, even if it feels awkward at first.
- Write down what the wrapper owns, and what stays in the legacy side.
- Ship one real use case before you wrap anything else.
That written boundary matters more than teams expect. A simple note in the repo can save hours of argument later. Keep it plain: which data types may cross the boundary, which errors the wrapper returns, which memory rules stay hidden, and which parts of the old library nobody should call directly anymore.
If the boundary feels messy, that is a signal, not a failure. Sometimes the library exposes too much state. Sometimes the service asks for too many special cases. When that happens, resist the urge to redesign everything. Cut the first version down until one team can support it without guessing.
A small example helps. If a legacy pricing library touches files, global config, and custom string types, do not expose all of that to a new service. Wrap it in a small request and response shape, keep file handling inside, and return plain errors the service can log and retry. That is often enough to make the code safer without touching the pricing logic itself.
If your team keeps circling around the boundary, an outside review can save time. Oleg Sotnikov works as a Fractional CTO and helps companies modernize software without wasting months on rewrites. He can review the interface, call out rollout risks, and help your team decide what should stay inside the wrapper and what should move out later.
After the first wrapper proves itself in production, repeat the pattern. Not everywhere. Just where the pain is real.


