C++ vs managed runtime memory: when control cuts cost
C++ vs managed runtime memory matters when allocation churn, heap growth, and pause time raise unit costs. See which workloads justify lower-level control.
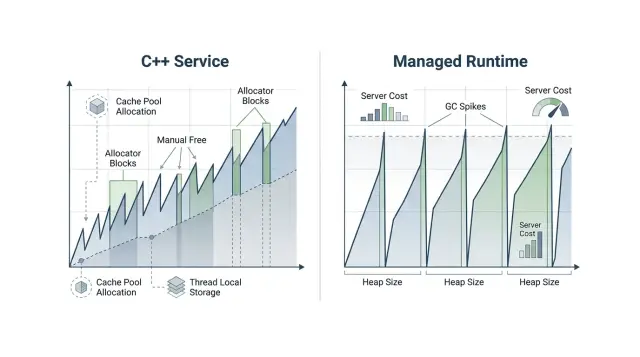
Table of Contents
Why this choice changes real costs
The difference in C++ vs managed runtime memory shows up fast when a service handles a lot of small, repeated work. If each request creates extra temporary objects, the runtime needs more heap space to keep up. That pushes memory use higher than the business logic alone would suggest.
Higher memory use is not just a technical detail. In the cloud, RAM costs money every hour, and memory spikes often force a larger instance size. A service that sits comfortably in 2 GB in C++ might need 4 GB or 8 GB in a managed runtime once allocation churn, heap growth, and safety margins enter the picture.
The bill rises again under load. When traffic jumps, a managed runtime may expand the heap to avoid constant cleanup. That can protect throughput for a while, but it also raises cost per request because you pay for memory that exists to absorb churn, not to do useful work.
Pauses make the problem worse for busy services. Garbage collection pauses may last only a few milliseconds, but on a high-traffic API that can be enough to build a queue, raise tail latency, and trigger retries. Retries create more work, more allocations, and more pressure on the same system. The effect can look small in a benchmark and painful in production.
C++ changes the tradeoff because developers can control when and how memory gets allocated. They can reuse buffers, keep objects on the stack, use pools for hot paths, and cut down on heap traffic. That control takes more care, but in low latency systems it often lowers both RAM use and jitter.
A simple example makes it clear. Imagine an API that parses JSON, adds a few checks, and returns a compact response 20,000 times per second. If the runtime allocates many short-lived objects per request, memory climbs and cleanup starts to interfere with response times. If the same path reuses memory and avoids heap churn, the service can fit on fewer machines and hold steadier latency. That is where the choice stops being academic and starts changing the monthly bill.
What a memory profile actually shows
A memory profile is a timeline, not a single RAM number. If you only look at average memory use, you miss the pattern that drives cost. The pattern tells you whether the process settles into a stable range or keeps creating pressure as traffic climbs.
Heap size over time is the first thing to check. In a healthy service, memory rises, levels off, and stays in a narrow band. If the line keeps creeping up, you may have a leak, an oversized cache, or request objects that live longer than you think.
Allocation rate often matters more than total RAM. Two services can sit at 1.5 GB and still behave very differently. One may allocate a small set of objects and reuse them. The other may create and discard millions of short lived objects every minute. That churn increases CPU work, puts more stress on the allocator or garbage collector, and raises cost per request.
Peak memory and steady memory also tell different stories. Steady memory affects your usual operating cost. Peak memory decides what machine size you must pay for. A service that idles at 2 GB but spikes to 8 GB during traffic bursts can force a much larger instance, even if the spike lasts only a few seconds.
Pause time changes the user experience before average latency shows any problem. In a managed runtime, garbage collection pauses often appear first in the tail, not in the mean. Your dashboard may say average response time is fine, while the 99th percentile jumps from 40 ms to 300 ms during collection cycles. In low latency systems, that gap matters more than the average.
C++ does not get a free pass here. It avoids garbage collection pauses, but poor allocation patterns still hurt. Frequent small allocations can increase lock contention in the allocator, fragment memory, and trigger more page faults. A profile helps you see whether C++ still wins because it reuses memory well, not just because it skips GC.
You also need to split startup behavior from long runs. Managed runtimes often spend the first minutes warming caches, compiling hot paths, and expanding the heap. Long running services may look fine after that. Short lived workers may never reach that stable state. A fair C++ vs managed runtime memory comparison looks at minute one and hour six as separate cases.
When you read a profile this way, you stop asking "How much RAM does it use?" and start asking better questions. How fast does it allocate, when does it spike, and what happens to latency when memory gets busy?
Workloads where C++ pulls ahead
C++ pulls ahead when a service creates huge numbers of short lived objects and drops them almost at once. Request parsing, message routing, telemetry ingestion, and real time scoring often work like that. In those cases, allocation churn is not a small detail. It changes cost per request.
A managed runtime can handle the same work, but it keeps paying for extra object metadata, pointer heavy layouts, and garbage collection pauses. C++ gives teams tighter control. They can use pools or arenas for temporary data, clear them in one step, and avoid a lot of allocator traffic.
Fixed data layouts matter just as much. A packed struct or flat array keeps memory use low and access patterns simple. A graph of separate heap objects usually takes more space and touches more cache lines. Add 50 extra bytes to each live item, then scale that across 4 million items, and you have roughly 200 MB of extra memory before you count fragmentation.
Hard latency targets make this gap easier to see. If a service must keep p99 latency under 5 ms, a rare pause still hurts. Average latency can look fine while users still feel random slow requests. Low latency systems usually care more about the tail than the average, and C++ gives more control over that tail.
The savings grow when many workers share one host. If each worker wastes 150 MB, then 24 workers burn 3.6 GB on memory overhead alone. That can force a larger instance size or reduce worker density. In C++ vs managed runtime memory comparisons, this is often where the bill starts to move in a measurable way.
Long running services also favor C++ when the memory footprint needs to stay flat for days or weeks. A well planned pool can reach a steady state and stay there. Teams that run lean infrastructure, like the kind Oleg Sotnikov often advocates, care about this because a flatter footprint means fewer surprises, lower cloud spend, and more room on the same hardware.
When a managed runtime still wins
C++ earns its place when allocation control changes the bill or the latency in a clear way. But many teams do not live in that world every day. If the app mostly runs business rules, talks to a database, and keeps memory use predictable, a managed runtime often gives a better return.
That is common in products where the rules change every week. A pricing engine, admin portal, or partner API may spend more time parsing requests, checking permissions, and calling other services than pushing the allocator hard. In that setup, a short garbage collection pause might not matter. If a request takes 120 ms because of network and database time, an occasional 15 ms pause is rarely the thing users notice.
A managed runtime often makes more sense when:
- the working set stays small even at peak load
- latency targets sit in the tens or hundreds of milliseconds
- the team ships new logic every few days
- memory safety bugs would cost more than a few extra servers
Developer speed matters more than many memory charts suggest. Good profiling tools, safer defaults, and easier debugging can save days of work. That matters even more for small teams. One hard-to-find memory bug in C++ can wipe out months of savings from tighter allocation control.
There is also a cost angle that people miss. If engineers can change a service in half the time, fix bugs faster, and onboard new hires without a steep ramp, the total cost per request may still favor a managed runtime. Raw memory efficiency is only one line on the bill.
Oleg Sotnikov often works with smaller companies that need faster delivery before they need absolute memory control. In that stage, the C++ vs managed runtime memory debate usually has a simple answer: keep memory use modest, measure garbage collection pauses under real load, and move to C++ only when the profile shows a real penalty.
How to run a fair test
A fair comparison starts with identical work. Feed both versions the same dataset, the same request mix, and the same burst pattern. If one service gets small payloads and the other gets heavier requests, the result tells you nothing about C++ vs managed runtime memory.
Check correctness before you measure speed. Both versions should return the same fields, the same status codes, and the same error behavior. Teams often compare a C++ service with less validation against a managed version that still does full parsing, logging, and retries. That compares two different products, not two memory models.
Keep the setup strict and boring:
- Run both on the same host type with the same CPU and memory limits.
- Warm each service first so startup work does not distort the run.
- Record allocation count, total bytes allocated, and peak RSS.
- Track p50, p95, and p99 latency under normal load and short traffic spikes.
- Turn the results into cost per host and cost per request.
Those memory numbers matter more than many teams expect. A managed runtime can post good average latency while still allocating far more memory per request, which pushes up garbage collection work and host size. C++ may look only a little faster on p50, yet save enough memory to fit more traffic on the same machine.
Use a simple cost view. If service A handles 8,000 requests per second on a host and service B handles 6,000, divide the host cost by delivered requests, not just by raw benchmark time. Then add memory headroom. If one version needs a larger instance to avoid pauses or swapping, that changes the bill even when median latency looks close.
If the runtime has garbage collection, record pause time next to latency percentiles. A short pause may not hurt p50, but it can hurt p99 enough to force more replicas. That is where allocation churn turns into real money.
A simple example from a busy API
Picture an order API that accepts JSON payloads all day. Each request parses line items, checks prices, builds a few internal objects, and writes the result to a queue or database. None of that data needs to live long. Most of it exists for a few milliseconds and then disappears.
A memory profile of this service often shows the same pattern: lots of tiny allocations, a high request rate, and very little long-term state. The app is busy, not memory hungry in the usual sense. It keeps creating short-lived objects and asking the allocator to clean them up.
In a managed runtime, that can work well until traffic stays high for hours. The runtime often grows the heap so it does not need to stop and clean as often. That tradeoff makes sense, but it changes cost. RSS climbs, garbage collection runs on a larger heap, and each worker needs more headroom. Latency usually stays fine at low load, then p95 and p99 start to wobble when cleanup kicks in at the wrong moment.
The C++ version of the same API can take a different path. Instead of allocating fresh memory for every parsed field, it can reuse read buffers, keep a request-local arena, and reset that arena at the end of the request. The code does more work up front, but the allocator does far less during the hot path.
That difference shows up fast on a real machine. Say the managed service settles around 1.5 to 2 GB for a few busy workers because it keeps extra heap space ready. The C++ service handling the same traffic might stay under 800 MB because it reuses memory instead of growing around the churn. On a 16 GB server, that can mean six workers instead of three, or room for another service without buying a larger box.
This is where C++ vs managed runtime memory stops being a style debate. If the profile says "short-lived objects all day," control over allocations can cut cost per request in a way finance can actually see.
Numbers that prove the gap is real
C++ vs managed runtime memory stops being theory when you measure the same request path under the same load and then price the result. Memory profiling usually shows the gap in five places: allocation churn, bytes copied, resident memory, cache behavior, and cost per request.
A fair run on a busy API can look like this. The endpoint does simple work: parse JSON, validate fields, hit a cache, build a response, and write logs. Business logic stays the same. Only the implementation language and runtime change.
- The C++ version may finish a request with 20 to 40 allocations. A managed version of the same flow can land at 300 to 600 because temporary strings, collections, wrappers, and serializer objects pile up.
- Buffer copies often tell the same story. If C++ reuses buffers and writes in place, it might copy 80 KB per request. A managed path that rebuilds strings and arrays can move 700 KB or more.
- Steady RSS matters more than a single peak, but peaks still cost money. One service might sit at 600 MB in C++ and 1.2 GB in a managed runtime, then jump past 2 GB during garbage collection pauses or traffic spikes.
- Cache misses under load turn memory waste into latency. If the C++ service stays around 6 percent last-level cache misses and the managed one reaches 15 percent, p99 latency usually follows.
- The bill is the part nobody argues with. If the heavier runtime needs two more 8 GB instances to keep headroom, that can add roughly $800 to $1,500 per month. At 100 million requests, that is $8 to $15 more per million requests.
Those numbers matter most in low latency systems, high-volume APIs, and jobs that run all day. A small app with light traffic may never earn back the extra engineering time.
Oleg often frames this the practical way: if memory behavior forces you to buy more machines, tolerate longer tails, or cap traffic earlier, the runtime choice changed unit economics. That is the point where the gap is real, not academic.
Mistakes that distort the comparison
Bad comparisons usually come from the test setup, not the language. People run a quick benchmark, see one chart, and decide that C++ is cheaper or that the managed runtime is "fast enough." Both claims can be wrong.
The first trap is simple: one side runs a debug build and the other runs a release build. That makes the result useless. A debug C++ build can look far worse than it should, while a warmed-up managed runtime with full optimization can look better than the code you actually ship. Test the production build of both.
Another common mistake is changing the data model while pretending you only changed the language. If the C++ version uses flat arrays and tight structs, but the managed version uses boxed objects, extra wrappers, and a different cache strategy, you are measuring two designs. That may still be a fair product test, but it is not a clean language test.
Latency numbers get abused all the time. Average latency hides the part users notice. If garbage collection pauses hit only 1% of requests, the average may still look fine while p99 looks awful. In low latency systems, the spike matters more than the mean.
Tests also end too early. Managed runtimes need time for warm-up, heap growth, and garbage collection cycles. C++ services often need time for allocator caches, connection pools, and request patterns to settle too. If you stop after a few minutes, you may capture startup behavior instead of steady cost per request.
A fair C++ vs managed runtime memory comparison keeps these fixed:
- same workload and request mix
- same data structures where possible
- same optimization level for shipped builds
- enough runtime to reach steady memory behavior
- p95 and p99 latency, not just the mean
One more mistake is pretending engineering cost does not exist. C++ can cut memory use and remove garbage collection pauses, but it also asks your team to own lifetime bugs, allocator choices, and harder failure modes. If a rewrite saves 30% on RAM but adds weeks of tuning and rougher on-call work, the cheaper runtime on paper may cost more in practice.
A quick checklist before you choose
A memory profile can save you from a very expensive guess. In many teams, CPU looks fine, but memory growth, allocation churn, and garbage collection pauses push costs up long before the processors get busy.
If you are weighing C++ vs managed runtime memory, ask what fails first under real load. That answer usually matters more than language preference.
- Does the service hit memory limits before it runs out of CPU? If memory tops out first, tighter control over allocations can let you pack more work into each worker.
- Do short pauses break your latency target? For a batch job, a pause may not matter. For a request path with a 50 ms budget, it can ruin the tail.
- Would smaller workers lower hosting cost in a noticeable way? Cutting each instance from 2 GB to 512 MB changes the bill fast when you run dozens or hundreds of them.
- Can your team handle ownership rules without creating bugs? C++ can cut waste, but only if the team writes and reviews that code with care.
- Could a small C++ component solve the hot path while the rest stays in a managed language? That is often the most practical middle ground.
A simple example helps. Say an API spends most of its time parsing payloads, building short-lived objects, and serializing responses. If the managed version needs larger heaps to keep pause times down, each worker may cost more to run. A small C++ parser or request-processing core can shrink memory use enough to fit more workers on the same hardware.
Team reality matters just as much as benchmark numbers. If your engineers rarely work with manual ownership, the extra control may not pay off. If one endpoint drives most of the bill, a narrow native rewrite often beats a full rewrite.
That is also the pattern Oleg Sotnikov often pushes teams toward in AI-first and startup work: measure the hot path, change the part that burns money, and leave the rest alone.
What to do next
Do one more test when traffic is at its worst, not when the system is calm. A memory profile taken at 2 p.m. on a quiet day can hide the very spikes that raise your cloud bill or push tail latency past your limit. If you can, replay a real production pattern with bursts, warm caches, and the same request mix your users create.
Do not jump straight to a rewrite. A hybrid design often gets most of the gain for much less risk. Keep the control plane, admin paths, or slower business logic in a managed runtime, and move only the hot path to C++: parsing, serialization, matching, compression, or any loop that creates too many short-lived objects.
Before you change languages, look hard at allocator strategy and object lifetime. Many teams blame the runtime when the real problem is churn from tiny allocations, poor pooling, or objects that survive one cycle too long. In C++, that means checking arenas, pools, and ownership rules. In a managed runtime, it means checking promotion rates, heap growth, and what keeps objects alive.
A practical order looks like this:
- repeat the benchmark under peak load
- inspect allocation hot spots, not just CPU time
- test a narrow hybrid cut instead of a full rewrite
- compare cost per request after the change, not just raw speed
If the answer still feels muddy, bring in someone from outside the team. A fresh architecture review can spot issues that internal teams miss because they already accept them as normal. That is especially true when both options look "good enough" in isolation but create very different costs at scale.
This is the kind of review Oleg Sotnikov does with startup and SMB teams. He can look at profiling data, system design, and unit economics together, then tell you whether C++, a managed runtime, or a mixed approach makes more sense. That is usually cheaper than betting months on the wrong rewrite.
Pick one service, measure it honestly, and follow the memory profile where it points. The numbers tend to settle the argument fast.


