Cloudflare Workers vs origin code for simple edge rules
Cloudflare Workers vs origin code: learn where to place redirects, bot checks, and small auth checks without duplicating app logic.
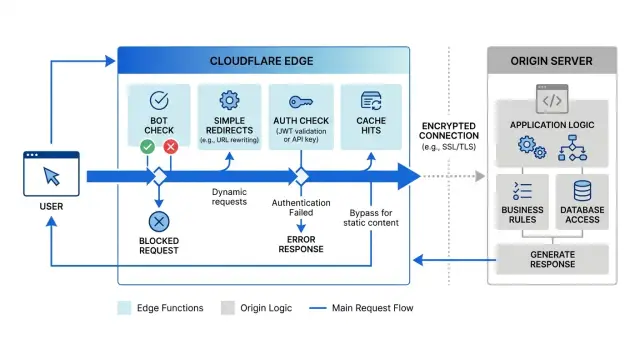
Table of Contents
Why this choice gets messy fast
Cloudflare Workers versus origin code gets confusing sooner than most teams expect. A request no longer follows one path. It can hit the edge first, get changed there, and then reach the app, where another set of rules runs again.
That sounds fine when the edge rule is tiny. Maybe you only want a redirect, a bot check, or a quick look at a session cookie. But now one request has two places that can make decisions, and both can change what happens next.
URL handling usually breaks first. A Worker might rewrite /login to /app/login or redirect example.com to www, while the origin still applies its own trailing slash fix, locale redirect, or old route mapping. Two layers now touch the same URL, and they do not always agree.
When that happens, bugs look random. One user gets a 301, another gets a 302, and someone else lands in a redirect loop because a header changed at the edge. Caching makes it worse. A bad redirect can stick around long enough to make you blame the app even when the app is fine.
Auth checks drift just as fast. It starts with a simple rule: if the cookie exists, let the request continue. Then you add token parsing, role checks, path exceptions, login redirects, refresh logic, and special handling for API calls. At that point, the edge is no longer doing a tiny gate. It is doing part of the app's job.
That split costs time every time something breaks. You check Worker logs, then app logs, then request headers, then cached responses. You reproduce the same request twice because the first version never reached the origin at all. A bug that should take 10 minutes can take an hour because the rule lives in two places.
The hardest part is not the extra code. It is the uncertainty. When a request fails, the team stops knowing where the truth lives. Even small changes start to feel risky.
What belongs near the edge
The edge works best for decisions that take a few milliseconds and use only the request in front of you. If a rule can run without a database call, without app state, and without another service, it usually belongs there.
Simple redirects are the easiest win. If a request hits an old host, an outdated path, or a plain HTTP entry point, the edge can return a redirect before the app does any work. That cuts origin load and avoids wasting time on requests you already know how to route.
Obvious bot traffic also fits well at the edge. If a request has a broken user agent, comes from a country you already block, or matches the junk traffic you see every day, stop it early. Your app should not spend CPU on noise.
A tiny allow or deny check can work there too. Think of a cookie that marks a signed-in session as present, or a header that marks an internal tool request. The edge can answer a basic question: continue or send the user to login. Keep it narrow. Presence checks are fine. Full permission logic is not.
Header cleanup is another good fit. The edge can normalize host headers, add cache hints, strip headers you do not trust, or set one simple header that tells the origin what it already learned.
A useful rule of thumb is boring on purpose:
- The rule uses only path, host, method, headers, cookies, or IP data already in the request.
- The rule finishes fast and does not need shared state.
- The rule is easy to explain in one sentence.
- If it breaks, the fix is obvious.
That last point matters. In Cloudflare Workers vs origin code, the edge should stay boring. Once a Worker starts calling APIs, reading complex session data, or making branching decisions that mirror your app, you are building a second app in front of the first one.
A clean example is enough: redirect /old-pricing to /pricing, block junk bot patterns, and check whether an auth cookie exists before letting someone reach /admin. Those actions stay fast, local, and easy to debug.
What should stay at the origin
If a rule needs full account context or changes real data, keep it in the main app. The edge is great for quick decisions, but it is the wrong place for anything that can charge money, grant access, or create a record you may need later.
In Cloudflare Workers vs origin code, money and permissions should usually stay at the origin. Your app already knows the user's plan, trial status, seat limits, account flags, and past actions. Duplicating that logic in a Worker looks fast at first, then turns into two sources of truth.
The split is simple. A Worker can check whether a request has a session cookie and send anonymous users to login. But if you need to know whether that user can open the admin area, download a paid report, or exceed a usage cap, the origin should decide. Those checks depend on full user records, not just headers and a token.
Billing belongs there too. If a request might start a paid action, apply credits, count billable usage, or unlock a feature, let the app that owns the data handle it. One billing bug at the edge can do real damage fast.
The same goes for audit logs. When a user changes a password, exports data, accepts a contract, or reaches a sensitive page, write the audit entry next to the app code that made the decision. That keeps the action, the reason, and the stored record in one place.
Keep permission checks that read account data, pricing and billing decisions, audit logs for sensitive actions, multi-step flows like checkout or account recovery, and side effects like emails or invoice creation at the origin. Redirects, bot checks, and tiny auth steps fit well near the edge. Stateful work does not.
Use one rule to split the work
Most teams get stuck on Cloudflare Workers vs origin code because they sort by technology first. A better split is risk first.
If a rule is fast, obvious, and cheap to get wrong, put it at the edge. If it depends on session state, billing, permissions, or anything that can block a real user from doing business, keep it at the origin.
That usually means the edge handles small checks with clear outcomes. A redirect from an old path to a new one fits well there. So does dropping a request with a bad bot score or rejecting a missing header before it burns app time. These rules are short, repeatable, and mostly the same for every request.
The origin should own anything with memory or money attached to it. Login state, account limits, plan access, coupon logic, and checkout rules belong in the app. If a mistake can lock someone out, leak data, or charge the wrong person, the Worker should not make the final call.
Give each route one clear owner. If /login belongs to the app, let the Worker do only a thin guard in front of it, such as rate limiting or a basic country block. The app still decides whether the user can sign in. If /checkout lives at the origin, keep the whole decision path there instead of splitting half the checks into edge code.
Write the full rule in the app first, even if you think it may move later. That gives you one place to test, log, and debug. After that, add a thin edge guard only if it saves real work, such as cutting obvious junk traffic or handling a redirect that never needs app data.
A quick filter helps. If a rule needs a session, database, or fresh account data, keep it at the origin. If a mistake can cost money or block a paying user, keep it there too. If the same answer works for almost everyone and the edge version removes enough noise to matter, the edge is probably a good fit.
Teams that run lean on purpose usually do better with this split because it keeps the edge fast and the app sane.
How to decide step by step
Most teams make this harder than it needs to be. Writing a redirect or a bot filter is not the hard part. Keeping the rule easy to find, cheap to run, and obvious to change six months later is.
Start with a plain inventory. Write down every redirect, bot check, and small auth step you already run or plan to add. Use real rules, not vague labels. "Redirect /old-pricing to /pricing" is useful. "Handle legacy URLs" is not.
Then sort each rule with a few basic tests. First, ask whether it needs data from your app, such as a database lookup, user record, feature flag, or session state. If it does, keep it at the origin unless you have a very strong reason not to.
Next, ask how often the rule changes. Marketing redirects that stay the same for months fit well at the edge. Login logic that changes with product work usually does not.
Then check the cost of a mistake. A wrong country redirect annoys people. A wrong auth decision can lock users out or let them in. High-risk checks belong close to the code and logs your team already trusts.
Move only the cheap, stable rules to the edge. Fixed redirects, simple bot filtering, header normalization, and tiny pre-checks like "does this request even have a token?" are good candidates.
Finally, give every rule an owner, a log entry, and a fallback path. Someone should know where the rule lives, what it did, and what happens if the Worker fails or gets bypassed.
A small example makes the split obvious. If you want to block obvious scraping, redirect old campaign URLs, and protect /dashboard, the redirect and the first bot screen can run at the edge because they are fast and mostly static. The actual dashboard permission check should stay at the origin because it depends on live user state.
If a rule starts simple but keeps growing, pull it back. That is usually the warning sign. Once a Worker needs shared constants, app-specific exceptions, and database-shaped thinking, you are no longer shaping requests. You are building a second app.
Teams with lean operations often do better with fewer edge rules, not more. A tiny set of stable checks is easy to reason about. That usually beats clever edge logic that nobody wants to touch.
A real example with redirects and login checks
Picture a visitor who clicks an old campaign URL from an email sent three months ago. They hit /promo/spring, but that page no longer exists. A Worker can catch that request at the edge and send one clean redirect to the current landing page before the request touches your app server.
That is a good fit for the edge because the rule is simple and stable. The Worker does not need product data, account history, or database reads. It just maps an old path to a new one and returns the response fast.
Now add basic traffic filtering. If the request matches an obvious bot pattern, the Worker can stop it early. That might be a bad user agent, a burst of repeat hits, or a request pattern no normal browser would send. You save origin capacity for real users instead of spending it on junk traffic.
The same request flow can handle a small auth check for /app. When someone asks for that path, the Worker looks for a signed cookie. If the cookie is missing, expired, or fails signature validation, the Worker redirects the visitor to the login page right away.
That check should stay narrow. The Worker should not decide what the person can see inside the product. It should answer one small question: does this request look like it belongs to a signed-in user?
If the cookie passes, the Worker forwards the request to the origin. The origin then does the heavier work. It loads the user record, checks the subscription plan, reads team membership, and decides whether the person can open billing, edit a project, or invite coworkers.
This split keeps the flow clean. The edge handles fast answers with almost no context. The origin handles business rules.
That setup feels boring in the best way. Redirects stay quick, obvious bots stop early, and login gating happens close to the user. The app server still owns the real decisions, so you do not end up with product logic scattered across two places.
Mistakes that create two apps
The mess usually starts with a shortcut. A team copies an allow list into a Worker for fast blocking, then keeps the same list in the app because "the app still needs it." Two weeks later, one list changes and the other does not. Now the edge says yes, the app says no, and nobody trusts either answer.
That drift gets worse when teams push role checks into the edge layer. A Worker can see a cookie, a token, or a header. It usually cannot see the full user state that the app knows about, like suspended accounts, team membership, plan limits, or a manual support override. If the Worker decides who counts as admin and the app also decides, you now have two auth systems with different facts.
A common trap looks harmless: a Worker lets users into /reports if a token claim says role=manager, but the app blocks them because their subscription expired that morning. Users call it a random bug. It is not random. The rule lives in two places.
Calling outside services before the app sees the request creates the same problem. A bot score API, a feature flag check, or a remote allow list can add delay and another failure point before your own code runs. When that service times out, teams start adding bypasses. Those bypasses pile up fast.
The drift starts small
Shared request IDs make a big difference. If the Worker blocks or rewrites a request, it should attach one request ID and pass it to the origin. The app should log the same ID. Without that trail, you end up staring at Cloudflare logs and app logs that never line up.
The warning signs are pretty clear:
- The same path rule exists in Worker code and app code.
- The edge makes role or plan decisions.
- The Worker calls third-party services on the request path.
- Edge logs and app logs do not share one request ID.
- Exceptions keep growing for partners, legacy clients, or one-off campaigns.
That is when Cloudflare Workers vs origin code stops being a clean split and turns into two apps pretending to be one. Keep redirects at the edge, reject obvious junk there, and do only tiny checks that rely on facts in the request itself. Let the origin own user state, billing, roles, and business rules.
Quick checks before you ship
Most Cloudflare Workers vs origin code arguments get simpler when you ask a few plain questions before a rule goes live. If a rule fails this test, move it back to the origin or rewrite it until it is boring.
A good edge rule is small enough that a new teammate can explain it in about a minute. If they need a whiteboard, three caveats, and a diagram of cookies, the rule is too big for the edge.
Use a short checklist:
- Skip rules that need a database read on every request.
- Ask someone else to explain the rule out loud.
- Give the Worker and the origin the same request ID and log it in both places.
- Make sure the origin can still handle the request if the Worker breaks, times out, or gets rolled back.
- Put one owner next to each rule.
A small example makes this real. Say you run redirects at the edge for old campaign URLs and you do a light auth check for the admin area by looking for a signed cookie. That can work well. The Worker can redirect /spring-sale to the current page and reject obvious bad bots before they hit the app. But the origin should still know how to serve the final page and verify the session properly.
That last part matters. If the Worker only checks whether a cookie exists and the app assumes the cookie is valid, you created a hole. If the Worker falls over and the origin cannot continue, you created downtime.
Write these checks into the rule ticket or config comment. Six months later, that short note will matter more than the code itself.
Next steps for a cleaner setup
A clean setup usually starts small. Pick one redirect group or one bot rule and move only that to the edge. Leave the rest alone for now so you can measure the result without turning the request path into a guessing game.
Most teams get into trouble when they move five tiny checks at once, then lose track of which layer made the decision. A small first move keeps Cloudflare Workers vs origin code from turning into two separate apps with overlapping rules.
Keep the rollout simple:
- Choose one rule with a clear yes or no result.
- Define what data the edge can read and what it must ignore.
- Note what still belongs at the origin.
- Log every decision the new rule makes.
- Set a date to review the results.
Then watch the logs for a full week. Look for false bot blocks, redirect loops, login friction, and requests that still need origin data. If support tickets go up or the logs look messy, stop there and fix the rule before moving another check.
Write the boundary in plain language and keep it somewhere the team will actually read it. One sentence often works: "The edge may redirect, block obvious junk, and check for a simple token. The origin decides permissions, pricing, account state, and all business rules."
That line saves time in code review. It also helps new engineers avoid adding "just one more" rule to the Worker because it feels convenient that day.
If the split still feels fuzzy, a second opinion can save a lot of cleanup later. Oleg Sotnikov at oleg.is works as a Fractional CTO and startup advisor, and this kind of boundary setting between edge rules, app logic, and infrastructure is exactly the sort of problem that is easier to fix early than after months of drift.
The cleaner setup is usually the boring one. The edge handles fast, obvious checks. The origin handles the parts that need context.
Frequently Asked Questions
When should I use a Worker instead of origin code?
Use a Worker for fast request checks that only need the URL, headers, cookies, method, host, or IP. Good examples are simple redirects, header cleanup, and stopping obvious junk traffic.
Keep the rule at the origin if it needs user records, billing data, team membership, feature flags, or anything that changes business behavior.
Should login and permission checks run at the edge?
No. Let the Worker do a thin check, like "does this request have a valid signed session cookie." Let the app decide roles, plan access, limits, and account state.
Once the edge starts making permission decisions, you end up with two auth systems that drift apart.
Are redirects a good fit for Cloudflare Workers?
Yes, most fixed redirects fit well at the edge. Old campaign paths, host redirects, and plain path remaps usually work best there because they are fast and do not need app data.
Keep one owner for each redirect. Do not let the Worker and the app both rewrite the same path.
What bot checks belong near the edge?
Block traffic that looks obviously wrong without asking the app for help. Bad user agents, repeated junk hits, or requests that no normal browser would send are good candidates.
Do not turn the Worker into a full fraud or abuse engine unless you are ready to own the extra delay and failure points.
Why do redirect loops happen with edge rules?
They usually happen when both layers touch the same URL. The Worker rewrites or redirects one way, then the origin applies its own slash rule, locale rule, or host rule and sends the user somewhere else.
Pick one place to own each URL rule. That removes most loops fast.
Should a Worker call my database or another API?
Usually no. A Worker should stay fast and local. If it needs a database read or a remote API call on the request path, the rule probably belongs at the origin.
Remote calls add delay, extra outages, and hard to trace failures before your app even sees the request.
How do I stop edge and origin rules from drifting apart?
Give every request one ID at the edge and pass it to the origin. Log that same ID in both places so you can trace one request from start to finish.
Also keep one clear owner per rule. If the same path check lives in two places, drift starts almost right away.
What should happen if the Worker fails?
The origin should still handle the request safely. If the Worker times out, gets rolled back, or stops running, your app should keep serving the route and recheck anything that matters.
Do not let the Worker become the only place that knows how a sensitive request works.
What is the safest way to move rules to the edge?
Start with one small rule that has a clear yes or no result. A fixed redirect or a basic bot filter makes a good first move.
Watch logs for a full week before you move more. If support tickets rise or behavior looks messy, fix that rule first instead of stacking new ones on top.
What is a simple rule for splitting edge work from app logic?
Use a simple test. If the rule is fast, obvious, and cheap to get wrong, put it at the edge. If it needs session state, account data, money, or permissions, keep it at the origin.
That split stays boring, and boring is what you want for request handling.


