Cheap GitLab runners: avoid bottlenecks and flaky builds
Learn how small teams set up cheap GitLab runners with sane autoscaling, smart cache placement, and safe isolation to cut build costs and failures.
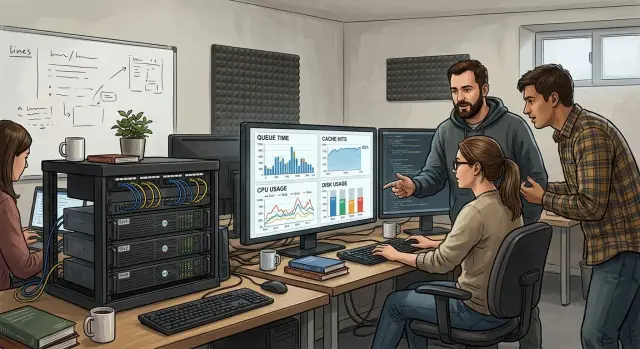
Table of Contents
Why cheap runners break under load
Cheap GitLab runners often look fine in light testing. The trouble starts when real team traffic hits. One build runs smoothly, but four jobs on the same low-cost machine can turn a decent setup into a slow, unreliable one.
CPU gets most of the attention, but it usually is not the first thing that fails. Slow disks drag out dependency installs, Docker layers unpack slowly, and artifact uploads back up. Network latency causes the same kind of pain when runners pull images, fetch packages, or talk to remote cache storage.
That is why a small VM can show free CPU and still feel overloaded. The runner spends most of its time waiting on disk reads, writes, and network responses. Developers watch pipelines stretch from 4 minutes to 18, and a simple dashboard still says the machine is fine.
Shared runners make small delays spread fast. If one job takes 3 extra minutes, the next jobs wait in line, new commits arrive, and the queue grows. A minor slowdown turns into an afternoon of waiting.
Random failures usually start with boring problems, not dramatic ones. A disk fills with old Docker layers or stale caches. An image pull stalls and hits a timeout. One noisy job grabs I/O, memory, or bandwidth, and unrelated builds start failing in ways that seem impossible to reproduce.
Picture one cheap machine running four jobs at once: a Docker build, a test suite, a package install, and an artifact upload. None of them looks huge on its own. Together, they fight over the same disk and network path, and the runner stops being cheap once you count the lost team time.
That is the pattern behind flaky CI on budget hardware. Small teams usually do not need bigger servers first. They need fewer hidden bottlenecks, less sharing, and a setup that does not let one bad job spoil the rest.
Match runners to the jobs you actually run
A lot of CI pain starts with one habit: treating every job as if it needs the same runner. It does not. Linting, unit tests, Docker image builds, database-heavy integration tests, and deploy jobs all stress different parts of a machine.
Start with the last few weeks of pipelines and sort jobs by what they really use. Some spike CPU for a minute. Some fill disk fast. Some need steady network access. A cheap machine can handle many of them, but not all at once on one shared runner.
Short jobs should stay away from heavy jobs. If a 20-second lint job sits behind a 12-minute Docker build, the whole pipeline feels slow even when the runner is technically busy. Split runners by workload so quick feedback stays quick.
For most small teams, a simple tag setup is enough: fast for linting, type checks, and small tests, build for Docker builds and long test runs, deploy for routine delivery jobs, and release for production-only work. Keep tags boring. If you create a maze of overlapping tags, people guess, jobs land on the wrong machines, and the split stops helping.
Release and production jobs need their own clean path. Give them runners that do as little else as possible. Do not let ad hoc test jobs, half-built images, or experimental scripts share that route. This does not require expensive hardware. It requires predictable hardware.
The goal is not to make every box identical. The goal is to make each box good at one kind of work. A 2 vCPU machine that only runs lint and unit tests often feels faster than a larger general-purpose runner that handles everything badly.
If you are not sure where to split first, separate Docker builds from everything else. That one change fixes a surprising number of slowdowns.
Pick machine sizes with real bottlenecks in mind
Small teams often buy runner machines by CPU count alone. That works until builds start timing out for reasons that look random. In practice, slow disks, low memory, or weak network throughput usually hurt first.
Watch a normal week of jobs before you change anything. Check CPU use, RAM pressure, disk wait, and network traffic during the builds you run most often. One noisy Monday tells you less than five ordinary workdays.
A pattern usually shows up fast. If CPU stays low while jobs crawl, the processor is not the problem. If memory fills up and the machine starts swapping, builds slow down hard. If package downloads, Docker layers, or artifact uploads take forever, check disk and network before you spend more on cores.
Fast local SSDs matter more than many teams expect. Build folders, temporary files, dependency unpacking, and container layers hit storage constantly. A modest machine with a good SSD often beats a larger box with cheap network storage.
RAM is usually the next thing to buy. Teams often raise concurrency because one machine looks underused, then wonder why flaky failures appear. If each job needs 2 to 3 GB at peak, four parallel jobs on an 8 GB runner is already risky once the OS, Docker, and GitLab Runner take their share.
A few simple rules help. Add RAM before you push concurrency higher. Keep build directories and temp files on local SSD. Treat swapping as a warning that the runner is already too full. If jobs pull large images or dependencies, measure network speed instead of guessing.
Machine variety causes its own problems. A pile of random one-off boxes is hard to tune and harder to debug. Use two or three stable machine types instead, such as a small default runner and a larger one for memory-heavy jobs.
That makes budget runners easier to trust. You get fewer surprises, clearer capacity planning, and a setup the team can understand without guessing why one runner behaves differently from the rest.
Set up autoscaling step by step
Autoscaling works best when the default path stays simple. Leave one runner on all the time for fast jobs like linting, unit tests, and small builds. That runner gives developers quick feedback instead of making every pipeline wait for a new machine to boot.
Then add burst runners for jobs that truly need more power. Docker image builds, browser tests, and large integration suites are the usual candidates. Small teams often get better results from this split than from throwing every job into one shared pool.
Set a hard ceiling before you turn anything on. If five machines is your budget limit, make that cap strict in the runner manager and in the cloud account if you can. Autoscaling without a cap is how a short traffic spike turns into a monthly bill nobody expected.
New machines also need to join fast, or autoscaling feels broken. Keep startup scripts short. Install only what the job needs, pull a small base image, register the runner, and start taking work. If boot time is three minutes, developers still wait even though you technically scaled.
A practical default is simple: keep one small runner online and let a few larger runners appear only when the queue grows. A team with 10 to 15 developers might keep one 2 vCPU machine ready for everyday jobs and allow two or three temporary machines for heavier pipelines during busy hours.
Idle shutdown needs balance too. Stop extra runners quickly so they do not burn money, but do not kill them the second a job finishes. A short idle window, often 5 to 15 minutes, usually works better because it catches the next wave of commits.
For the first week, watch three numbers: average queue time, runner startup time, and peak machine count. If queue time stays low and the pool rarely hits the cap, the setup is probably close. If the queue spikes every afternoon, add a little buffer for that window instead of paying for bigger machines all day.
Place caches where they save time
A bad cache wastes more time than no cache at all. The goal is simple: keep downloads and setup work short without dragging around huge files that go stale after two jobs.
Cache small, reusable parts. Package downloads and dependency folders are the usual wins: npm or pnpm stores, pip download caches, Cargo registry files, and Go module caches. Avoid caching the whole workspace. That usually creates large archive uploads, slow restores, and weird failures when one job leaves behind files another job did not expect. If a build artifact must move to the next stage, use artifacts for that job chain and keep caches focused on dependencies.
Share a cache only when jobs really use the same tools and versions. A Node 18 job and a Node 20 job should not fight over one cache. The same goes for different lockfiles, OS images, or CPU types. Build cache keys from the language version and dependency lockfile, and a lot of silent breakage disappears.
Placement matters as much as cache contents. A local SSD or NVMe disk on the runner often beats remote storage for speed and reliability, especially for small teams with steady workloads. If you need shared cache storage, keep it as close to the runners as you can. A cache on the far side of a slow network can erase most of the gain.
Old caches also need cleanup rules. If you keep every version forever, dead data pushes out useful data. Short expiry times work better than many teams expect. For fast-moving projects, a week or two is often enough.
Do not assume a cache is helping just because the pipeline stays green. Check the job logs after every cache change. Look for real cache hits, compare warm and cold runs, and watch restore time itself. If restoring a cache takes 90 seconds to save 30 seconds, delete it and keep the runner lean.
Isolate runners before one bad job poisons the rest
Most flaky CI problems start with shared state, not weak hardware. On cheap runners, you feel this faster because a full disk, a stuck Docker daemon, or a leftover file can break the next job without much warning.
A simple split goes a long way. Keep trusted internal pipelines away from untrusted merge request jobs, especially if outside contributors can trigger builds. One messy job should not share a machine with release work, private test data, or deployment credentials.
Use separate runners for different kinds of work, even if the machines look similar. The point is isolation, not perfect hardware matching. In practice, that often means one runner group for internal branch and release jobs, another for merge requests and less trusted code, another for Docker-in-Docker image builds, another for shell tasks and host-level scripts, and a small separate group for deploy jobs.
Docker-in-Docker jobs deserve their own runners because they leave behind images, layers, networks, and odd failures. Shell runners also need distance from container jobs. They touch the host more directly, so a bad script can leave packages, files, or changed permissions that break later pipelines.
A common failure looks dull but costs hours: a merge request builds a large image, fills the disk, and leaves gigabytes in the work directory. The next internal pipeline fails during checkout or cache restore. People blame GitLab, but the machine is simply dirty.
Reset work directories after jobs that create large artifacts or temporary files. If a job uses Docker heavily, clean the workspace and prune what you can on a schedule. Small machines do not forgive leftovers.
Keep privileged mode on the smallest possible set of runners. Many teams enable it everywhere because one image build needed it once. That spreads risk across the whole fleet. Put privileged jobs behind specific tags, and let only those jobs use those runners.
Production deploy runners should stay separate from build runners and should have a narrow role. Give them only the permissions they need to deploy to the target environment. No broad admin access, no mixed-purpose jobs, no extra secrets. When one runner does one kind of work, failures stay smaller and much easier to trace.
A small-team setup that works in real life
For a small team, a good runner setup is usually simple. Keep one small machine online all day for linting, unit tests, type checks, and other fast jobs. These jobs need quick start time more than raw power, so a modest runner often feels better than a larger machine with a longer queue.
Then add two burst runners for heavier work. Start them only for Docker builds and integration tests, and shut them down when the queue clears. This is where budget runners make sense: you pay for bigger machines only when a pipeline actually needs them.
Cache placement matters more than most teams expect. If every dependency cache lives on the main runner disk, disk I/O becomes the bottleneck and the always-on machine slows down for everyone. Put shared dependency caches in object storage or another nearby shared store, and keep the local disk focused on active jobs.
Release work also belongs on a separate deploy runner. That runner should handle staging and production deploys only, not feature branches or random test jobs. When teams mix deploys with everyday branch work, one bad script can fill the disk, leave stale containers behind, or change permissions in ways that break the next release.
In practice, this split is enough for many teams: one always-on runner for fast checks, two burst runners for builds and integration tests, one deploy runner with strict tags and limited access, and one shared cache store. It is not fancy, but it is easy to understand and easy to maintain.
The weekly review can stay short. Check average queue time and cache hit rate. If queue time keeps growing, add capacity or move noisy jobs off the default runner. If cache hits are low, fix cache keys before you spend money on more machines.
This lean approach matches how Oleg Sotnikov works with small teams: keep the daily path light, burst only for heavy work, and keep deploys away from noisy pipeline traffic.
Mistakes that create random failures
Random CI failures often look like code problems, but runner setup causes a lot of them. A test passes, then fails 10 minutes later, and the team starts chasing ghosts. In many small setups, the real issue is shared hardware, stale state, or a cache that behaves badly.
Packing too many jobs onto one machine is a common mistake. CPU limits matter, but disk pressure usually bites first. If several jobs download packages, unpack archives, build Docker layers, and write artifacts at the same time, one small SSD can stall every pipeline. Then timeouts, slow tests, and failed pulls look random even though the machine simply cannot keep up.
Cache design trips people up too. One shared cache for Node, Python, Go, and system packages sounds cheap and simple. It often is neither. Different tools expect different folder layouts, file locks, and cleanup behavior, so one large cache creates strange misses and occasional corruption. Split caches by language and toolchain version. A smaller clean cache beats a large messy one.
Long-lived runners create their own mess over time. Old containers stick around. Temp files pile up. Docker layers grow. Package managers leave data behind. After a few weeks, the machine starts acting cursed, but nothing magical happened. The runner filled itself with junk. Ephemeral runners fix this best, but scheduled cleanup still helps a lot.
Mixing deploy jobs with untrusted code is another avoidable mistake. If the same runner handles production deploys and merge request code from many contributors, risk goes up and failures get harder to explain. Keep deploy runners separate, lock them down, and give them a narrow scope.
The cheapest VM can cost more than a slightly better one. Retry storms, long queue times, and failed builds burn team time fast. In practice, one stable runner with fast local disk often beats two bargain machines with noisy storage.
A few warning signs usually show up early:
- Jobs fail more often during busy hours.
- Cache hit rates look fine, but installs still take forever.
- Disk usage climbs every week.
- Manual retries fix builds with no code changes.
- Deploy jobs slow down when test pipelines spike.
Teams running lean GitLab setups usually do better with fewer clean runners than with a pile of overloaded ones. If one machine handles too much, split the workload first. Buy another runner only after you fix disk contention, cache sprawl, and job isolation.
Quick checks before you buy more machines
Buying another VM often hides the real problem. Budget runners usually waste money in quieter ways: jobs sit in queue, one runner fills its disk, or one noisy build slows everything else.
Start with the queue. If pipelines wait a long time before work starts, you may need better autoscaling, better tags, or lower concurrency on heavy jobs. If jobs start fast but fail halfway through, extra machines may do nothing. That usually points to memory pressure, disk contention, bad cache behavior, or weak isolation.
Watch the runners for a full workday, not just one failed pipeline. Compare queued time with run time. Long queues usually mean capacity, tagging, or scheduling problems. Check whether disk usage rises all day. Docker layers, logs, and artifacts can quietly fill the runner until builds fail. Look at repeated jobs from the same branch. If cache hits do not save real time, cache placement is wrong or the cache churns too often. Make sure heavy jobs have their own tags, limits, or separate runners. Large Docker builds should not fight tiny lint jobs. Group failures by runner name and by time of day too. If most failed jobs come from one runner or from busy hours, the issue is probably local.
A common mistake looks like this: a team sees random failures in the afternoon, adds another cheap machine, and nothing improves. Later they find one runner with a nearly full disk and shared Docker state from earlier jobs. The fix was cleanup and isolation, not more hardware.
Once you answer these checks with real numbers, the next step gets clearer. You may need one more runner. You may just need cache cleanup, separate tags for heavy jobs, or a better schedule. That is how you reduce CI build costs without making builds flaky.
Next steps for a lean runner setup
Cheap GitLab runners stay cheap only when they are predictable. A runner that saves $40 a month but breaks two releases is not cheap.
Start with three numbers your team can review every week: monthly CI spend, average queue time before a job starts, and build failure rate caused by runner issues rather than bad code. Put a real target next to each one. Keep it simple. For example, stay under $300 a month, keep queue time under 2 minutes, and keep runner-caused failures below 1 percent.
After that, slow down your changes. If you swap machine types, change cache rules, and turn on autoscaling in the same week, you will not know what fixed the problem or what broke it. Change one part, then watch a full week of builds. Small teams usually learn more from seven normal days than from one afternoon of testing.
Write things down, even if your setup is small. Keep a short note with the machine type for each runner, which jobs use which tags, where caches live, and any limits on concurrency. Six weeks later, that note saves more time than another round of guessing.
A simple split often works. Frontend jobs may run fine on a small machine, while Docker image builds choke on disk and network. Give each job type its own runner tag and record why you made that choice. That one habit cuts a lot of random failures because people stop sending every job to every machine.
Sometimes the runner setup is only one part of the mess. CI cost, uptime, deployments, and team workflow pull on each other. If you need a second opinion, Oleg Sotnikov at oleg.is works with startups and small teams on lean infrastructure, Fractional CTO support, and practical automation, including GitLab runner design.
The next useful move is usually not buying more machines. Pick your three targets, make one change this week, and keep notes the whole team can read. That is how a lean setup stays lean.
Frequently Asked Questions
Do I need bigger runners, or a better setup?
Usually you need a better split first. Many slow pipelines come from disk, memory, or network contention on one shared runner, not from low CPU.
Separate fast checks from heavy builds, cap concurrency, and clean up old Docker data. Buy more machines after you confirm the queue still grows or jobs still fight over the same bottleneck.
What should I separate first on cheap GitLab runners?
Split Docker builds away from everything else first. They pull images, unpack layers, write temp files, and hit disk and network harder than most jobs.
That one change often keeps lint and unit tests fast without changing the rest of your pipeline.
How many jobs should one cheap runner handle at once?
Start lower than you think. A cheap runner may handle several light jobs, but memory and disk pressure rise fast when builds run in parallel.
If each job needs a few gigabytes at peak, four parallel jobs on a small machine already feels risky. Raise concurrency only after you watch normal workloads for a few days.
What matters more than CPU on a budget runner?
Fast local SSD storage often matters first. Dependency installs, Docker layers, artifacts, and temp files hit disk constantly, so a slow disk makes the whole runner feel overloaded.
RAM usually comes next. If the runner swaps, build times jump and flaky failures start showing up.
Should every CI job use the same runner?
No. One shared runner for linting, tests, Docker builds, and deploys creates slow feedback and strange failures.
Use simple tags and send similar work to the same type of runner. Keep the tag set small so people do not guess.
What should I cache, and where should I put it?
Cache dependency downloads and tool caches, not the whole workspace. Large workspace caches take too long to upload and restore, and they often leave behind files that break later jobs.
Put caches close to the runners. Local SSD works well for steady workloads, while nearby shared storage helps when several runners need the same data.
How do I use autoscaling without getting a surprise bill?
Keep one small runner online for quick jobs, then let a few larger runners start only when the queue grows. Set a hard machine cap in your runner manager and cloud account.
Also keep boot time short. If new runners need several minutes to join, autoscaling will look slow even when it works.
Why do my builds fail randomly even when nothing changed?
Shared state usually causes it. Old Docker layers fill the disk, stale caches stick around, one noisy job takes most of the I/O, and the next job fails for no obvious reason.
Clean work directories, prune Docker data on a schedule, and isolate heavy or less trusted jobs from the rest of the fleet.
Should deploy jobs run on the same runners as tests and builds?
Keep deploys on their own runners. Production work should not share a machine with merge requests, test jobs, or image builds.
That split reduces risk and makes failures easier to trace. It also protects deploy credentials and keeps release jobs from waiting behind noisy pipeline traffic.
What does a practical runner setup look like for a small team?
A simple setup works for many teams. Keep one small always-on runner for linting, type checks, and unit tests, add two burst runners for Docker builds and integration tests, and keep one separate deploy runner for staging and production.
Review queue time, cache hit rate, and runner-caused failures every week. If those numbers stay healthy, you do not need a more complex design.


