Branch protection rules that fit your team as it grows
Branch protection rules should match how your team works. Start with simple checks on main, then add reviews, tests, and limits when real problems appear.
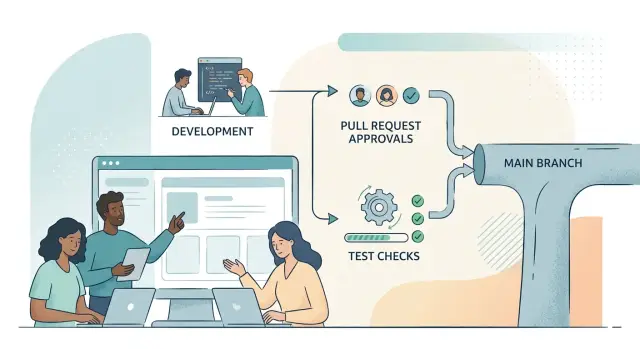
Table of Contents
Why teams need branch protection
A stable main branch saves time every week. Without clear rules, one rushed commit can break tests, delay a deploy, or ship a bad change. The damage usually looks small at first. Then it spreads through the week as hotfixes, rollbacks, and time lost figuring out what changed.
Most of these problems start in ordinary moments. Someone pushes straight to main for a quick fix and slips in one extra change. Someone else merges late because nobody knows who should review it. The next morning, the team is untangling regressions instead of building the next thing.
When risky merges go unchecked, fixes pile up fast. One patch fixes the first mistake, then another fixes the patch. Release work gets messy, and people stop trusting the branch everyone depends on.
Branch protection rules reduce that uncertainty. They define what can go into main, who approves it, and what has to pass first. The technical settings matter, but the clarity matters just as much. People waste less time asking whether a shortcut is okay or whether someone already made an exception last week.
The point is not extra friction. The point is main branch safety. If main stays stable, developers can pull fresh code without worry, product teams can plan releases with more confidence, and support sees fewer avoidable issues after deploys.
Small teams often feel the benefit first. A startup with four engineers and constant customer requests does not need a heavy process. It does need a branch it can trust. Protecting main, requiring pull requests, and running a few reliable checks before merge already prevents a lot of release mistakes.
Teams that skip these basics often think they are moving faster. Sometimes they are, for a day or two. Then one careless merge burns half a sprint, and the trade-off becomes obvious.
Start with the smallest safe baseline
Most teams do not need a long policy on day one. They need a short set of rules that protects the branch everyone relies on.
Start with the branch that affects releases. For many teams, that is main or master. If that branch stays clean, rollbacks are rarer and nobody spends an afternoon guessing which commit broke the build.
A good baseline is simple:
- protect the main branch
- block direct pushes for normal work
- require a pull request for every merge
- keep one clear emergency path for urgent fixes
That is enough for a lot of teams, especially small ones. You do not need three reviewers, a page of exceptions, and checks for every tool if you ship a few changes a week.
Blocking direct pushes matters more than it seems. One rushed commit can skip review, skip context, and create a mess the whole team inherits. A pull request slows that moment down just enough for someone else to catch a missing migration, a risky config edit, or a note that should have gone into the release.
You still need an emergency path. Production incidents happen. If the site is down and one person needs to patch it fast, allow that route, but keep it rare and obvious. Teams usually handle this well with two plain rules: use the bypass only for real incidents, and open a follow-up pull request right after so the change is documented.
Keep the whole setup easy to remember. If people need a diagram to merge a small fix, the process is too heavy. A good rule set should be easy to explain in about a minute.
Set up your first rules step by step
Most teams do better with one protected release branch than with a pile of rules spread across several branches. Pick the branch that feeds production, or the one you merge into before every release. For many teams, that is main.
Start with pull request approval. One approval is usually enough at the beginning. It catches more problems than many teams expect, especially small but costly mistakes like a missed config change, leftover debug code, or a hurried content edit that breaks a test. Save two approvals for later, when the team is larger or the code carries more risk.
Next, require passing checks, but only for jobs you already run and trust. If you have one unit test job and one build job, use those. Do not turn on five flaky checks just because the option exists. Rules people do not trust become background noise, and then nobody respects the process.
It also helps to name one person who can approve emergency overrides. On a small team, that might be the tech lead, engineering manager, or CTO. One owner keeps exceptions rare and clear.
Write the bypass rules in plain language. A short note in team docs is enough. Say when people can skip approval or checks, who can make that call, and what happens after the emergency ends. If the team hotfixes a payment bug directly into main, for example, they should still open a follow-up pull request to record the change and check for anything missed.
That is the balance you want. The normal path is clear, and the escape hatch is clear too.
Add gates only after real pain shows up
More rules do not make a team safer by default. They often just make people look for ways around the process. Small teams usually need a clear path to merge changes, not a wall of approvals and checks.
Every rule should map to a problem the team has actually felt. If nobody can name the problem, the rule will feel random. That is when people start clicking through approvals without reading or waiting on checks they do not trust.
Match each rule to a real failure
If obvious mistakes keep slipping into main, add a reviewer. One careful second pair of eyes catches a lot.
If broken code reaches main and blocks other work, require a small set of automated checks before merge. Start with the basics: tests that must pass and maybe one build check. Slow feedback teaches people to hate the gate, so keep it tight.
If the same part of the codebase causes trouble again and again, require code owner review for that area only. Billing logic, deployment files, and authentication are common examples. You do not need stricter review across the whole repo to protect a risky corner of it.
Large pull requests create their own problems. Reviewers skim, comments show up too late, and bugs hide inside big rewrites. When that keeps happening, ask people to split work into smaller merges or set a reasonable pull request size limit.
Rules can age badly. A check nobody understands, an approval step everyone bypasses, or a requirement that no longer fits the team's workflow should go away. Dead rules do not make anyone safer.
A simple approach works well: add one rule for one repeated problem, watch it for a few weeks, and keep it only if it stops the same mistake from happening again. If it creates delay without much benefit, remove it.
A simple example from a growing team
Imagine a three-person product team shipping a small SaaS app. One person works on the backend, one on the frontend, and one handles bugs, support, and small product changes. They talk every day and move fast. They do not need a heavy process.
Their rules start with one goal: keep main usable. They protect that branch, require one approval, and run a basic test check before merge. That gives them a safety net without slowing every change.
For a while, that is enough. Most pull requests are small. People know the codebase, and the cost of waiting on extra reviews would be higher than the risk.
Then two Friday merges go wrong. The first breaks the signup flow. The second does not take production down, but it changes behavior in a way support notices within an hour. In both cases, someone merged in a rush because they wanted to finish before the weekend.
So the team changes one rule. They block direct pushes to main.
Nothing else changes. They keep one approval. They keep the same tests. The new rule targets the actual problem: rushed merges with no pause between writing code and shipping it.
A few months later, the product grows and billing logic gets more sensitive. Refunds, plan changes, and invoice timing now affect revenue, so mistakes cost more than a minor UI bug. The team does not respond by tightening everything. They require code owner review only for billing-related files.
That matters. Pricing changes now get reviewed by the person who knows that area best, while normal product work still moves quickly.
And they stop there. Two approvals on every pull request would only create waiting. Extra status checks would repeat what the current tests already catch. The process stays just strict enough to protect main, and no stricter.
Mistakes that make people fight the process
People stop trusting rules when those rules block normal work more often than they stop real mistakes. That usually happens when a small team copies a process built for a much bigger company.
A two-person or five-person team does not need the same setup as a company with separate QA, security, and release managers. If one person writes most of the code and one other person reviews it, asking for two approvals turns every pull request into a waiting game. The rule looks careful on paper, but in practice it teaches people to work around it.
Another common problem is broken checks that nobody can fix. A flaky test suite, a slow staging job, or a CI permission issue can block merges for hours. After the third false failure, people stop seeing checks as protection. They just see noise.
Hotfixes expose the gap between process and reality. If production breaks, the team may need one small patch in ten minutes. Forcing that patch through every review and every long-running check can make a bad day worse. A lighter emergency path with clear follow-up rules usually works better.
Teams also keep old rules long after the original problem disappears. Maybe a required approval was added after one rushed change caused a bug. Six months later, the risky part of the code is gone or the team has changed, and everyone still waits on the same extra gate. Rules should solve a current problem, not memorialize an old one.
You can usually tell the process is off when merges wait on unavailable people, checks fail for random reasons, urgent fixes get trapped behind slow release steps, or nobody remembers why a rule exists.
Good process feels boring. It protects the main branch, keeps review reasonable, and lets urgent fixes move fast.
Quick checks for your current setup
You can judge your setup by looking at what happens on a busy day. If one tired person can push straight to main, skip review, and ship a bad change in seconds, your safety net is too thin.
Good rules are easy to explain and easy to follow. If the team keeps asking what a rule means or why it exists, the setup is probably solving the wrong problem.
Start with five plain questions. Can one person break main with a single click? Do reviews catch obvious risks before merge? Do tests finish fast enough for daily work? Can the team explain each rule in one sentence? Do emergency fixes have a clear path?
Those questions reveal most problems fast. If direct pushes are still open, block them for normal work. If reviews miss missing tests or risky config edits, tighten the review standard. If checks take 40 minutes, people will resent them and try to avoid them. A short test suite that finishes in 5 to 10 minutes protects the main branch better because teams actually use it.
Reviews need a simple standard too. The reviewer should understand what changed, what could break, and how the author checked it. If that is not clear, the pull request is not ready.
Emergency work deserves the same level of clarity. Decide in advance who can approve a hotfix, what can be skipped, and what follow-up check happens after the fix ships. A production issue at 2 a.m. is the worst time to invent a process in chat.
If your team can answer those five questions without arguing, the setup is probably close to right. If every answer starts with "it depends," simplify the process before you add anything else.
When stricter rules start to make sense
Loose settings work when a small team talks all day and changes are easy to track. They stop working when more people touch the same code every week. Two developers edit the same service, someone changes shared config, and a small miss slips into main. That is usually the point when stricter rules start saving time.
You will notice it after releases too. If support tickets spike right after deploys, the problem is often not one careless developer. More often, the repo has no clear pause point before risky code lands. A required review, a passing test check, or a release branch can stop a mistake that would otherwise reach customers in minutes.
Some code deserves tighter rules earlier than the rest. Payments, access control, customer records, and regulated data are obvious examples. In those areas, a slower merge is cheaper than a billing error or a security incident.
New hires change the picture as well. Experienced teammates know which folders are fragile and which shortcuts are safe. New people do not know that yet, and they should not have to guess. Clear boundaries help them learn faster. Review from a code owner on the risky parts of the codebase is often enough.
Release pressure is another signal. When timing matters, surprise fixes hurt more than a slightly longer review queue. A team shipping an internal tool can accept more mess than a team with paid users, promised release dates, or customer demos on the calendar. Merge speed feels good in the moment. Predictable releases feel better the next morning.
A simple rule works here too: make a gate stricter only when you can name the pain it prevents.
What to do next
Open your repo and check the main branch settings this week. Many teams assume they have enough protection, then discover that anyone can push straight to production code or merge without a second look.
Start with a quick audit. Check who can push to main, whether pull requests are required, and whether failed tests block merges. Then fix one pain point, not five. If your last release broke because someone merged without review, add a review requirement. If bad builds keep slipping through, require a passing check before merge.
After a few release cycles, review the setup again. Ask two direct questions: did this rule prevent repeat mistakes, and did it slow normal work too much? If it did not prevent problems, remove it. If it slowed the team too much, simplify it.
Sometimes the hard part is not the setting itself. It is choosing rules that fit the way the team actually ships. If you need help with that, Oleg Sotnikov at oleg.is works with startups and small companies as a fractional CTO and advisor. An outside view can be enough to cut release mistakes without turning every merge into a meeting.
If you do only one thing now, make main a little safer this week. Then watch what improves and earn every extra rule.
Frequently Asked Questions
What branch protection rules should a small team start with?
Start with a small baseline. Protect main, block direct pushes for normal work, require a pull request, and ask for one approval before merge.
That setup stops many rushed mistakes without slowing a small team too much.
Should we block direct pushes to main?
Yes, for normal work, block them. Direct pushes let one rushed commit skip review and checks, and that often creates avoidable release problems.
Keep one clear emergency bypass for real incidents, then open a follow-up pull request right after.
How many approvals do we actually need?
Most small teams do fine with one approval. One careful review often catches missed config edits, debug code, or changes that need more context.
Ask for more approvals only after team size or risk goes up.
Which checks should we require before merge?
Require only the checks you already trust. A build job and a small test suite usually give enough protection at the start.
Skip flaky or slow jobs until you fix them. People ignore gates they do not trust.
What should an emergency hotfix process look like?
Make the emergency path short and obvious. Let one named person approve the bypass for a real production issue, then document the change in a follow-up pull request.
That keeps fixes fast without turning exceptions into normal habits.
When should we add code owner review?
Add code owner review when one part of the repo keeps causing costly mistakes. Billing, auth, deployment files, and access control often need tighter review first.
You do not need stricter review for the whole codebase just to protect one risky area.
How can we tell if our rules are too strict?
Watch how people behave on a busy day. If merges wait on unavailable reviewers, checks fail for random reasons, or people keep looking for ways around the rules, the setup is too heavy.
Good process feels boring and easy to explain.
How fast should CI checks be?
Aim for checks that finish in about 5 to 10 minutes for normal work. Fast feedback keeps the team moving and still catches common mistakes.
If checks take 40 minutes, people start to resent them and try to skip them.
When do stricter branch protection rules start to make sense?
Tighten rules when the pain shows up in real work. More people touching the same code, support issues after deploys, sensitive billing or security code, and new hires all raise the risk.
At that point, stricter gates usually save time instead of wasting it.
How often should we review our branch protection setup?
Review them after a few release cycles or after a painful incident. Ask two direct questions: did this rule stop repeat mistakes, and did it slow normal work too much?
If a rule no longer solves a real problem, remove it.


