Bounded contexts for marketplaces: split rules early
Learn how bounded contexts for marketplaces help you separate buyer, seller, payout, and support rules before one shared schema creates conflicts.
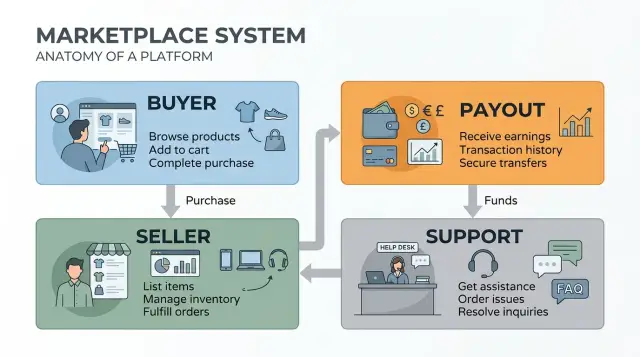
Table of Contents
When one schema stops working
A single marketplace schema feels fine at the start. One order record, one status field, one user table. That works while the product is small and the happy path is simple.
The trouble starts when buyer and seller actions stop lining up. A buyer wants to browse, pay, cancel, return, and get updates. A seller needs to accept or reject the order, prepare it, ship it, handle stock issues, and answer claims. They both touch the same transaction, but they do not follow the same rules.
Support makes the gap wider. Checkout wants a clean flow. Support deals with damaged items, partial refunds, address fixes, fraud checks, lost packages, and manual exceptions. If those cases live inside the same schema logic as checkout, the model gets noisy fast. Fields that looked simple, like status or refund_reason, start carrying too many meanings.
Payouts split off next. Orders happen when a buyer pays. Payouts happen when the platform decides funds are safe to release. That can be days later, or even longer because of returns, reserve periods, chargebacks, or compliance checks. When one order schema tries to own both purchase timing and payout timing, teams start forcing unrelated states into one timeline.
A small example shows the strain. A buyer orders handmade furniture. The seller confirms it two days later. Support changes the delivery address after checkout. The item arrives damaged, so support approves a partial refund. The seller's payout stays on hold until the claim closes. That is one customer story, but it contains four different rule sets.
You can usually spot the breaking point by the flags. Teams add fields like manual_review, seller_confirmed, refund_pending, payout_hold, and support_override. Then they add combinations of flags because one flag is no longer enough. After that, nobody trusts a single row to explain what is actually happening.
This is where bounded contexts stop being theory. In a marketplace, they help keep buyer flow, seller operations, support exceptions, and payout rules from fighting inside one schema.
The first four rule sets to split
Marketplaces look simple early on. One user table, one order table, one product table. Then refunds affect seller balances, support agents make exceptions, and tax fields show up where they do not belong.
The first split should usually follow business ownership.
Buyer rules belong together. This area owns search, cart, checkout, payment status the buyer can see, and refund requests. It answers plain questions: what can this person buy, what price do they see, and what happens if they cancel?
Seller rules are different enough to separate early. Sellers care about listings, inventory, fees, policy violations, and disputes tied to fulfillment. A seller may accept an order, reject a return reason, or pay a category fee. None of that should change how the cart works.
Payout rules need their own model even if money first appears inside orders. Payouts track holds, settlement timing, reversals, tax details, and the final amount owed after fees and refunds. An order can say paid while the payout side still says hold for 7 days. Both are correct, just in different contexts.
Support needs a separate home too. Support agents open cases, add notes, collect evidence, and make manual decisions. They may approve an exception that the normal product rules would reject. That does not mean support should own seller fees, payout math, or buyer checkout logic.
A simple ownership map helps more than another schema tweak:
- Buyer owns purchase flow and customer-facing refunds.
- Seller owns listings, stock, fees, and dispute responses.
- Payout owns holds, settlements, reversals, and tax records.
- Support owns cases, notes, and manual overrides.
Write that down before touching tables. If a return comes in, the buyer side can accept the request, support can review edge cases, seller rules can handle the dispute, and payout rules can adjust settlement. That is much easier to reason about than one order table trying to act like a cart, ledger, seller portal, and help desk at once.
How to find a real boundary
A real boundary usually shows up before the code looks terrible. You feel it when one part of the product changes every week while another part needs to stay stable.
Start with ownership. Ask who asks for rule changes most often. If the support team keeps changing case rules, but payout rules only move when finance asks, those parts probably do not belong in the same model. A shared schema makes every small change feel risky because each team pulls the same records in a different direction.
Words are another giveaway. If the same term means different things to different people, you likely already have two contexts. Order is the classic example. A buyer thinks of an order as one purchase. A seller may treat it as one shipment or one line item. The payout side cares about when money clears. Support may treat that same order as a conversation with status, notes, and attachments.
State changes tell the same story. A buyer-facing purchase might go from pending to paid to delivered. A payout record might go from pending to on hold to released. A support case follows a different path again. When one table tries to hold all those states, teams start adding flags to explain exceptions, and the model gets harder to trust.
A few checks work well in practice:
- One group changes the rules far more often than another.
- One word needs different definitions in meetings.
- One record moves through different states depending on who uses it.
- One small change breaks tests or workflows in another area.
That last point matters more than people expect. If a seller policy update breaks buyer emails, or a support note changes payout behavior, the boundary is already there. The code just has not caught up yet.
There is also a simple test: can you explain a rule without mentioning another team's concerns? If you can describe seller acceptance rules without talking about refund handling, or support triage without talking about payout release timing, split the ownership there. Keep shared identifiers if you need them, but stop forcing one schema to own every meaning.
A practical way to split the model
Start small and stay literal. Write one short user story for each side: a buyer places an order and asks for a return; a seller accepts, packs, and ships; payout releases money after checks pass; support steps in when something goes wrong. If one story needs a different set of decisions, it probably needs its own model.
Then list the states each side moves through. A buyer order might go from cart to paid to delivered to return requested. A seller shipment has its own path: accepted, packed, shipped, delayed, cancelled. Payout and support need separate state lists too, even when they touch the same order.
Once the states are visible, put each rule where the decision happens. Can the buyer cancel after shipping? belongs to buyer and order rules. Can the seller combine two shipments? belongs to seller fulfillment. When does money release? belongs to payout. Who can approve an exception? belongs to support.
If two groups care about the same fact, one group should still own the decision and publish the result.
A small example makes this easier. If a buyer opens a return, support may approve the exception, but payout should not read the whole support case and guess what happened. Support can send a simple event like return_approved with the order ID and a reason code. Payout reads that event and applies its own rule for hold, partial release, or reversal.
Keep shared data boring and stable. IDs, timestamps, totals, and a few basic status values can be shared or copied where needed. Policy rules, notes, internal flags, and workflow details should stay inside the group that uses them.
A good split is usually simple: each group owns its own states and rules, shared records stay thin, other groups read IDs and facts, and nobody edits another group's private fields.
It feels slower at first. Later, it saves a lot of cleanup.
A marketplace example with returns and payouts
A refund request shows why one shared schema gets messy fast. A buyer receives an item on Monday and asks for a refund on Tuesday. The order still says delivered, but that status cannot carry the rules for support, seller evidence, and money movement.
Support opens a case in its own model. That case has a reason, a status, deadlines, messages, and evidence. The order does not need all of that, and the payout record definitely does not.
At the same time, the payout flow places the seller's transfer on hold. That hold is a payout rule, not an order rule. The buyer still has a completed purchase, and the seller still has a shipped order. Support changes. Payout reacts.
The seller then replies inside the case. They might add tracking details, delivery photos, or a signed receipt. Support needs that proof to make a decision, but payouts only need one fact: keep the money on hold, release it, or reverse it.
You can model that split without much drama:
- Buyer data covers the order, items, refund request, and messages the buyer can see.
- Seller data covers shipment details, proof of delivery, and response history.
- Support data covers case status, evidence, internal notes, and deadlines.
- Payout data covers hold state, amount, ledger entries, and the release or reversal result.
Once support decides, payouts act on that result. If support approves the refund, the payout flow reverses the held funds and records the refund outcome. If support rejects the claim, payouts release the money to the seller.
This matters even more as rules get more specific. Partial refunds, damaged-item claims, or payout delays for high-risk orders all sound manageable in isolation. Put them in one order table and every new rule turns into another flag, another exception, and another late-night bug. Keep each group's facts local and share only the signals the next group needs.
Data that looks shared but should not be
Teams often keep one table for anything that feels common. A marketplace makes that tempting. The same person can buy, sell, contact support, and receive money, but each action follows different rules.
A single status field is usually the first trap. Active can mean a buyer may place orders, a seller may publish items, a payout may move, or a support case is still open. Those are not the same state. When one column tries to cover all of them, the team starts adding flags and exceptions until the data says less, not more.
The same problem shows up with users. One login account does not mean one user model. A buyer needs addresses, returns, saved payment methods, and order history. A seller needs tax details, store settings, moderation history, and payout preferences. The same person may hold both roles, but the business rules still live in different places. Shared identity is not shared meaning.
Support notes are another common leak. If an agent writes, "seller agreed to replace the item after photo review," that note belongs to the support case. It does not belong in the seller record. Case notes are messy, temporary, and tied to a specific dispute. If you store them as seller data, another team may read them later as a permanent fact.
Payout data needs the same boundary. A payout table should answer finance questions: how much the seller earned, what fees applied, what amount stays on hold, and when money can move. It should not decide whether a listing needs approval, whether a category has special rules, or whether a return window changed. Finance records should capture the outcome of those rules, not own the rules.
When data feels shared, ask a few plain questions. Do two teams read the field for different reasons? Is this temporary case detail getting mixed into long-term profile data? Is a payout record storing catalog behavior instead of amounts and dates? Reuse identity where it helps, but keep role-specific rules separate.
Mistakes that create rework
Teams usually create rework when they treat every marketplace action as part of one big order record. It feels faster at first. A few extra columns, a few new flags, one more status. Six months later, nobody can change refund logic without breaking payouts or seller reporting.
One common mistake is using a single status field for three different things: the buyer order, the support case, and the payout. Those flows move at different speeds and follow different rules. An order can be delivered, a support case can still be open, and the payout can be on hold. If one status tries to say all of that, people start adding values like completed_pending_review or paid_except_dispute.
Support access causes another mess. If support agents can edit seller settings or payout data directly, they can solve one ticket and create two accounting problems. Support should record a request, approve an action, or trigger a workflow. They should not rewrite payout ownership, bank details, or seller policy fields by hand.
The giant order table is another trap. Teams keep packing exceptions into it because the order looks shared by everyone. Soon it holds dispute notes, payout retries, seller exceptions, manual review reasons, tax fields, and internal comments. At that point, the table stops describing an order. It becomes a dumping ground.
Copying every field into every service creates a slower kind of damage. One team copies seller name, payout status, case reason, and fee breakdown "just in case." Then data drifts. Support sees one value, finance sees another, and nobody knows which system owns the truth.
There is a smaller mistake that still costs time: changing names without changing ownership. Renaming merchant_status to seller_health does nothing if the same team, table, and edit path still mix onboarding, compliance, and payout rules.
If changing one field needs approval from different teams with different goals, that field probably sits in the wrong place. Split ownership before you add another flag.
Quick checks before adding another flag
A new flag often feels cheap. Add is_paused, payout_hold, or needs_review, and the release moves on. A few months later, one order record carries buyer steps, seller promises, payout timing, and support exceptions at the same time.
The problem is usually not the flag itself. The problem is that the flag smuggles a whole new set of rules into a model that already does too much.
Before you add one more field to a shared table, stop and ask:
- Can one team change this rule on its own?
- Does this area own its own states?
- Do other parts need the full record, or just an ID and a few facts?
- Can support pause a case without rewriting checkout?
- Would a new payout rule force buyer schema changes?
A short example makes this concrete. Suppose finance wants to hold payouts for new sellers for 7 days. That belongs in payout rules. The buyer still sees the same purchase status. Support still tracks cases in its own flow. If the payout hold adds columns to the main order state machine, the boundary is already blurry.
Separate states are often the cleanest test. When two areas move at different speeds, let each one keep its own status names and logic. Pass IDs and a few facts between them. If a new flag stays local, keep it local. If it changes the meaning of the same record for three teams, split the model instead.
What to do next
Start with one workflow that already causes confusion. Put it on paper. A return with a partial refund and a delayed seller payout is a good example because teams often mix buyer promises, seller rules, money timing, and support exceptions in one flow.
Write each step in plain words. Who makes the decision? Who owns the rule? What data do they need at that moment? If one box needs facts from three teams to decide a simple outcome, the model is already mixing boundaries.
Pick one boundary to separate in the next sprint. Only one. Payout is often a good first move because money rules tend to stay strict while buyer and support rules change more often. If payout is too risky, support can be the safer first split because it needs its own notes, overrides, and case history.
Keep the change narrow. Map the current workflow step by step, mark each decision as buyer, seller, payout, or support, move one set of rules under one clear owner, keep old fields readable until reports catch up, and review real edge cases after release.
Do not break reporting while ownership shifts. Keep dashboards stable with a simple reporting layer, export job, or read model that still produces the same numbers for finance and ops. Teams get nervous when totals change in the middle of a migration, even when the product behaves better.
If your model already sprawls across too many flags, exceptions, and shared tables, it helps to get a second opinion before cutting it apart. Oleg Sotnikov at oleg.is works with startups as a Fractional CTO and advisor, and this kind of product architecture review is often enough to spot the risky joins before they turn into a painful rewrite.
The next step is rarely a full rebuild. It is one clean boundary, one messy workflow mapped clearly, and one release that makes the next change easier.
Frequently Asked Questions
When does one order schema stop being enough?
It stops working when one record tries to explain buyer checkout, seller fulfillment, support cases, and payout timing at once. If your team keeps adding flags just to explain normal work, split the model.
Which context should I split first?
Start with the area that creates the most friction. Payout often goes first because money rules stay strict, while support often goes first when exceptions and notes keep leaking into orders.
How do I spot a real boundary before the code gets worse?
Watch who changes the rules and how people talk about the same record. If support, sellers, and finance use the word order in different ways, or one small change breaks another area, you already have separate contexts.
Can one person be both buyer and seller without one giant user model?
Yes. Share login and identity, then keep buyer data and seller data in separate models. The same person can hold both roles, but addresses and returns do not belong next to tax details and payout settings.
Where should refunds live?
Let the buyer side own the refund request that the customer sees. Put evidence, case notes, and exception handling in support, and let payout own the money result.
What data should contexts share?
Share boring facts like IDs, timestamps, totals, and clear outcome codes. Keep notes, policy logic, internal flags, and workflow details with the group that makes those decisions.
Should I keep one status field for orders, support, and payouts?
No. Give each context its own states. An order may say delivered while support says open and payout says on_hold, and that does not create a conflict.
How should support tell payouts what happened?
Support should send a small, clear result such as return_approved with the order ID and reason code. Payout then decides whether to hold, release, or reverse funds by using its own rules.
Do bounded contexts mean I need microservices right away?
No. You can split models, rules, and ownership inside one app first. Separate services help later, but clear boundaries matter more than your deployment shape.
Do I need a full rebuild to fix a messy marketplace schema?
No. Map one painful workflow, mark who owns each decision, and move one boundary at a time. Keep old fields readable until reports catch up, then remove the leftovers.


