Background job monitoring before users notice delays
Background job monitoring helps teams spot aging queues, repeated failures, and customer delays before support inboxes start filling up.

Table of Contents
Why stuck background jobs stay hidden
A lot of the work users care about happens after they click a button. The page loads, the order looks complete, and everyone assumes the rest finished too. Behind the scenes, a worker still has to send the receipt, create the account, sync data, or build the report.
That gap hides trouble. Once the user leaves the page, the app stops giving you clear signals. No spinner hangs forever. No red error box appears. The failure sits in a queue, a worker log, or a retry table that nobody checks during a normal day.
Most teams hear about it from support first. A customer writes, "I paid but never got the email," or "my export still says pending." By then, the first failed job may be hours old, and the queue behind it has grown quietly.
One broken worker can block far more than people expect. If that worker handles a narrow task, like invoice creation or email sending, every new request for that task lines up behind the same bad process. The app can still look fine from the front, so the backlog grows without much drama.
Retries make the problem harder to spot. They often bury the first useful error under a pile of later noise. Instead of seeing "SMTP login failed" or "database connection refused," the team only sees "job hit max attempts" after several rounds. That is a much worse clue.
Ownership gets fuzzy too. Product teams watch the user flow. Infrastructure teams watch servers. Support teams watch complaints. Nobody feels responsible for checking whether queued work is moving at a normal pace, so stuck jobs sit in the middle where no one looks closely.
That is why background job monitoring often trails the real problem. Server uptime can look good while customers wait 30 minutes for something that should take 30 seconds. The system is technically up, but the work users asked for is not getting done.
Once the support inbox starts filling up, the issue is already bigger than one failed job. Now you have delayed actions, confused customers, and cleanup work that gets messier by the hour.
What to watch before a backlog turns into a problem
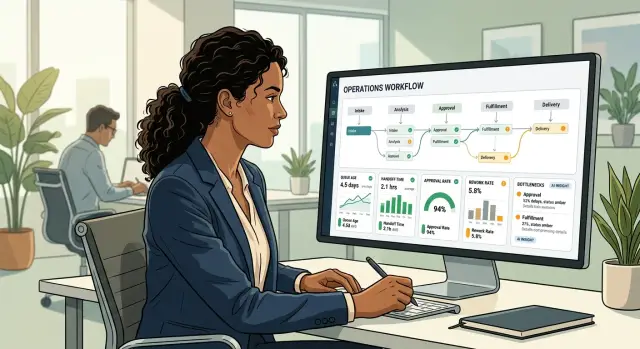
A queue can look fine right up until customers feel the delay. Job count alone often hides the real issue. A queue with 200 waiting jobs may be healthy if work clears in seconds, while a queue with 20 jobs may already be stuck if the oldest one has been sitting there for 40 minutes.
Start with the age of the oldest job in each queue. That number tells you how long work has gone without finishing. If email jobs usually clear in under two minutes and the oldest job is now 18 minutes old, you have a real signal even if the total queue size still looks small.
Failure totals help, but failure reasons help more. One burst of temporary network errors means something very different from a database timeout, a bad API key, or broken input data. Group failures by reason so you can spot patterns fast. When one reason suddenly jumps, your team can check the right system first instead of digging through logs for half an hour.
Retry volume matters too. A job that succeeds on the second try is annoying but manageable. A queue full of jobs that retry five or six times can burn workers, slow everything else, and hide the original fault. Watch how many jobs retry, how long they take to finish, and how many never get there.
Separate slow work from stalled work
Some jobs still move, just more slowly than usual. Others stop moving at all. Those are different problems, and they need different fixes.
If processing time rises but jobs continue to finish, you may have a capacity issue, a slow dependency, or one heavy task type crowding the queue. If the oldest age keeps rising and completion drops to almost zero, workers may be frozen, crashing, or blocked on the same failure.
A simple way to tell the difference is to watch two lines together: completion rate and oldest-job age. If completions hold steady, you are slow. If completions collapse while age climbs, work is stuck.
Compare against a normal day
Raw numbers can mislead you. Compare today with a normal day for the same hour and the same queue. A payment queue at 9 a.m. behaves differently from a report queue overnight.
Set a baseline for queue age, finish time, retry count, and common failure reasons. Then alert on changes from that baseline, not just fixed limits. That catches odd behavior early, before support tickets describe it for you.
How queue problems turn into customer problems
Most teams watch workers, retries, and server load. Customers do not care about any of that. They feel the delay when a real action stalls: a signup does not finish, an export never arrives, or an account update stays wrong for hours.
Start by naming the customer action behind each queue. "Email queue" is too vague. "Send password reset email," "create invoice PDF," and "sync new order to the warehouse" tell you who is waiting and why the delay matters.
For each queue, keep a small map that shows the queue name, the customer action, how fast a user notices the delay, and a rough count of how many accounts are affected if it stops. You do not need exact numbers. Labels like "all new accounts," "paid plans only," or "one customer per failed import" are enough.
That last point changes urgency fast. A blocked job that affects one report request is annoying. A blocked job that touches every new signup can turn into a support spike in ten minutes.
Some delays are obvious right away. Password reset emails, one-time codes, checkout confirmations, and data imports usually create instant complaints. Other delays show up later, like weekly summaries, invoice archiving, or internal sync jobs. Marking that difference helps your team decide when to wake someone up and when to fix the issue during working hours.
The status view should stay the same for product, support, and operations. If each team reads a different dashboard, they waste time arguing about scope. One shared view can stay plain: oldest job age, last successful run, common failure reason, and estimated affected accounts.
That shared view helps support too. If support can see that the export queue has been stuck for 47 minutes and affects about 120 accounts, they can give clear answers instead of asking users to retry. Product sees the same problem and can pause a release or change the message inside the app. Operations can fix the failure without guessing who is affected.
At that point, monitoring stops being just a system chart. It becomes a customer impact chart, and teams notice stuck work before users pile into the inbox.
Set up a basic view step by step
Start with one screen that answers a simple question: which jobs are waiting, failing, or running far too long right now? Good monitoring does not need a huge setup. It needs a small view that people can read in 10 seconds.
First, give every queue a clear name and a short purpose. "emails" is fine if it only sends mail. "default" is a bad habit if it hides billing syncs, exports, receipts, and webhooks in one pile. When a queue name tells the truth, your team can spot trouble faster.
Then show a few numbers for each queue: current queue age, throughput, retry count, recent failure count, and running jobs. That is usually enough to tell the difference between healthy work, slow work, and stuck work.
Queue age matters more than raw queue length in many systems. A queue with 5,000 tiny jobs may clear in a minute. A queue with 40 jobs can still hurt customers if the oldest one is 25 minutes late.
Failure logs need cleanup too. Raw stack traces are useful for engineers, but they are bad for daily scanning. Group errors into plain buckets that anyone can read: "third-party API timeout," "bad customer data," "missing record," "rate limit," or "code error after deploy." If one bucket jumps, the problem is obvious.
Keep alerts narrow. Set one alert for age spikes, because rising age usually means customers are waiting. Set another for repeat failures, because one bad job is noise and 30 copies of the same failure is a real issue. If you alert on every single failure, people stop paying attention.
A small team can build this with a dashboard, logs, and two or three alerts. The tooling is rarely the hard part. Choosing signals that match customer pain is harder.
Test every alert before you trust it. Push one safe job that you know will fail, or point a test worker at a fake dependency, and make sure the alert fires, shows the right queue, and lands where someone will actually see it. A silent alert is worse than no alert because it gives false comfort.
If you do only one thing this week, add queue age and plain-language failure buckets. That alone catches a surprising amount of stuck work.
A realistic example: receipt emails stop sending
A customer pays for an order and expects the receipt email within a minute or two. The payment goes through, the order appears in the admin panel, and nothing looks broken on the surface. The first failure happens in the background, where most teams are not looking every minute.
A small template change can break the email worker in a very ordinary way. Maybe the template expects a customer name field that no longer exists, or it tries to render a value that comes back empty. The worker picks up the job, throws the same error, retries it, and puts it back into the queue.
Queue length alone is a bad comfort metric here. Retries keep jobs moving, so the queue can look stable even while no receipts actually leave the system. A flat chart can hide a real outage.
The number that tells the truth is queue age. At 9:05, the oldest unsent receipt might be 4 minutes old. By 9:45, it is 44 minutes old. New customers keep paying, but older receipt jobs keep waiting behind the same failure loop.
The pattern is usually simple: payments succeed at a normal rate, receipt jobs keep retrying with the same template error, queue depth stays close to normal, the oldest job age climbs without dropping, and support starts hearing from customers before engineering sees a clear spike.
That last part matters more than teams expect. Customers do not describe the problem as a queue issue. They say, "I paid but never got my receipt." Some ask for the email again. Some try to pay twice because they are not sure the first order worked. Finance or sales often gets dragged in next, because missing receipts create extra manual work fast.
Good monitoring should connect the technical signal to the customer signal. If payment success stays normal but receipt delivery drops, that should trigger attention. If one failure reason repeats hundreds of times, that should stand out. If the oldest receipt job keeps aging, someone should get an alert before the inbox fills with complaints.
In many cases, the fix is small. One template patch and one deploy can clear the queue. But if nobody watches age, repeated failure reasons, and customer impact alerts, a tiny bug turns into a support problem that looks much bigger than it is.
Mistakes that keep teams blind
Most teams do not miss stuck jobs because they lack a dashboard. They miss them because the dashboard answers the wrong question.
The most common mistake is alerting on queue size alone. A queue can look healthy at 20 jobs and still hide a real problem if the oldest payment, invoice, or signup task has been waiting for 18 minutes. Queue length tells you volume. It does not tell you whether work is aging, looping in retries, or blocking a customer.
Another bad habit is mixing every job type into one chart. That makes the graph look tidy, but it hides the jobs that matter most. Receipt emails, webhook deliveries, nightly reports, and image processing do not have the same normal pace or the same business cost when they stall. If you blend them together, slow low-risk work can cover up urgent failures.
Retries cause a different kind of blindness. Teams often let a broken job retry for hours because it feels safer than dropping it. In practice, that can bury the real issue. The queue stays busy, graphs keep moving, and nothing useful finishes. Put a limit on retries, use sensible backoff, and move poison jobs out fast so people can inspect them.
Error details get hidden too often. A red "failed" label is not enough. The team needs the raw message, the last retry time, the upstream status code if there is one, and enough context to see who is affected. If a job fails because an email provider rejects a template or a third-party API returns 401, that should be visible without digging through five systems.
The last mistake is waiting for complaints. By then, the queue has already turned into user pain. Support hears "I never got my receipt" or "my export is still pending," and engineers start from zero.
A small setup works better. Track oldest job age for each queue, split charts by job type instead of one blended total, cap retries and surface dead jobs quickly, show raw error text with customer or tenant context, and alert on affected users or blocked actions instead of job counts.
That is usually enough to catch trouble early. One stuck email queue may affect 200 receipts in ten minutes. One stuck billing job may affect five customers, but that is still the issue you want to see first.
A quick weekly check
Fifteen minutes once a week can catch the slow drift that daily alerts miss. Good monitoring goes beyond red alarms. It helps you spot queues that are getting older, noisier, or harder to recover long before users send angry messages.
Use the same dashboard every week and check it on the same day. A single spike may mean nothing. A small pattern that repeats for three weeks usually means something is off.
Check the oldest job in every queue first. Total job count can stay flat while one stuck item sits for hours and blocks follow-up work. Then read the top few failure reasons and group similar errors together, even if the wording changes a bit, so you see the real cause instead of three versions of the same problem.
After that, look for queues where retries keep rising. That often means workers are wasting time on jobs that will not recover by themselves. Confirm one owner for each alert too. Shared responsibility sounds nice, but one named person responds faster.
It also helps to review one recent incident and ask what showed up first. If retry noise appeared on Monday and support heard from users on Wednesday, you found two days of warning you can use next time.
Keep notes in one simple table or document. You do not need a long report. Write down what changed, what needs a fix, and who will look at it.
This habit works well for small teams because it stays cheap. A founder, team lead, or fractional CTO can do the check without turning it into a meeting. The point is to keep weak signals visible before they turn into backlog, missed emails, delayed exports, or stale customer data.
After a month, patterns get easier to spot. Maybe one queue always ages after a release. Maybe one failure reason climbs whenever a vendor API slows down. Those are the kinds of warnings that save support time later.
If you keep one rule, keep this one: when the oldest job age rises for two weeks in a row, treat it as a real issue and assign it that day.
What to do next
Pick one queue first. Do not start with every worker, every retry path, and every alert. Start with the queue that touches money, signups, or first-day onboarding, because that is where silent delays hurt fastest.
If you are setting this up for the first time, smaller is better. A crowded dashboard looks busy, but it hides the one number that actually changed. Put only the basics on the first screen: queue age, jobs waiting, failure count, and the last few failure reasons.
A simple first pass is enough. Choose one high-impact queue. Add one dashboard with four to six metrics. Set two or three alerts with clear thresholds. Then test one alert on purpose so the team sees it fire.
Write down who responds to each alert. If queue age spikes at 2 a.m., one person should own the first check. If failures come from a third-party email service, another person may need to step in. Shared ownership often means no ownership.
Keep the alert message plain. "Receipt queue age is 18 minutes. Last successful job was 21 minutes ago. 143 jobs are waiting. Top error: template field missing." That gives the on-call person something they can act on right away.
If your team keeps finding these issues through support tickets, an outside review can help. Oleg Sotnikov at oleg.is works with startups and small businesses on architecture, infrastructure, and fractional CTO support, and this kind of operational blind spot is exactly the sort of thing worth fixing early.
The goal is simple: catch stuck work while it is still a small fix, not a customer-facing incident.
Frequently Asked Questions
What should I monitor first in a background job system?
Start with the age of the oldest job in each queue. That tells you how long real work has waited.
If a queue usually clears in a minute or two and the oldest job is now 15 or 20 minutes old, you likely have a customer problem even if the queue does not look large.
Why is queue length a weak signal by itself?
Queue size only shows volume. It does not show whether jobs finish, retry in a loop, or sit untouched.
A small queue can still hurt users if one job type stops moving. An older oldest-job age is often a better warning than a bigger job count.
How can I tell the difference between slow jobs and stuck jobs?
Watch completion rate and oldest-job age together. If jobs still finish but take longer, you are slow. If completions drop hard while age keeps rising, work is likely stuck.
That quick check saves time because slow systems and frozen workers need different fixes.
What failure details should I put on the dashboard?
Show the plain error text, the last retry time, and enough context to know who is affected. Include the queue name and, when relevant, the tenant, account, or customer action.
"Failed" is too vague. "Template field missing" or "SMTP login failed" gives your team something they can act on fast.
Which queue should I set up first?
Pick the queue tied to money, signups, password resets, receipts, or first-day onboarding. Those delays create pain fast and usually reach support first.
Do not start with every worker at once. One high-impact queue gives you a useful setup much faster.
How many alerts do I need at the start?
Keep it simple. One alert for age spikes and one for repeated failures covers a lot of ground.
If you add alerts for every single failed job, people learn to ignore them. A few clear alerts beat a noisy setup.
How should I group background job errors?
Group them by reason people can read at a glance. Use buckets like third-party timeout, bad input data, missing record, rate limit, auth error, or code error after deploy.
That makes patterns easy to spot. Ten copies of the same failure should look like one problem, not ten separate mysteries.
When should a queue issue page someone after hours?
Wake someone when a stuck queue blocks a customer action users notice right away, like payments, password resets, one-time codes, or signup completion.
For slower-impact queues, you can often fix the issue during working hours if the delay will not confuse users or block revenue.
How often should I review queues if alerts are already running?
Do a short review once a week even if alerts look quiet. Alerts catch sharp failures, but they often miss slow drift.
Check oldest-job age, rising retries, and repeated error reasons. Fifteen minutes is usually enough to catch patterns before customers do.
What does a useful queue alert message look like?
Use plain language and real numbers. A good message says which queue has trouble, how old the oldest job is, when the last success happened, how many jobs wait, and the top error.
That gives the on-call person a clear first move instead of forcing them to dig through three tools at 2 a.m.