Architecture review checklist for AI assistant output
Use an architecture review checklist to define boundaries, data flow, and ownership so code reviews catch structural mistakes early.
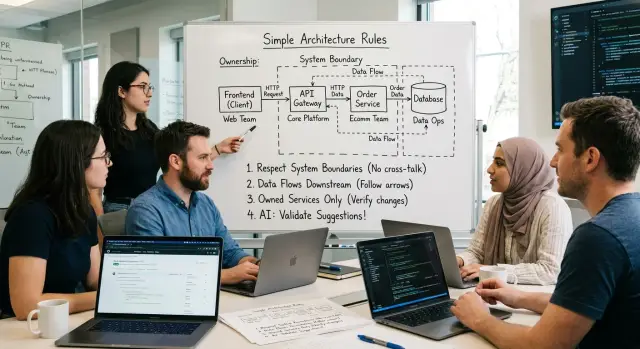
Table of Contents
Why good-looking output still causes structural problems
Clean code can still push a system in the wrong direction. Tests pass, types line up, and the diff looks tidy, but the change may put logic in the wrong layer, route data around a shared contract, or give one service knowledge it should not have.
This happens often with assistant-written code because it solves the local task in front of it. Ask for a feature, and it will usually find the shortest path to working behavior. A reviewer sees green tests and readable code, so the change feels safe.
The trouble shows up later. A handler starts talking to storage directly instead of going through the domain layer. A background job quietly reimplements permission checks. A new field moves from API to database with no clear owner, so three parts of the app start making their own assumptions about it. Nothing looks broken on merge day, but the system gets harder to change one pull request at a time.
Teams miss this because many architecture rules live in people's heads. One reviewer knows billing data must enter through one service. Another knows user status belongs to the account domain. If those rules are unwritten, reviews drift into taste and memory. Two smart people can approve the same structural mistake for different reasons.
A short architecture review checklist fixes more than it slows down. It gives reviewers a shared way to ask simple questions: did this change cross a boundary, did data follow the expected path, and does the right team own the rule? Those checks catch problems that unit tests often miss.
The goal is not extra ceremony. The goal is fewer merge-time surprises and fewer "why does this module know that?" moments a week later. Good reviews should stop code that works today but makes tomorrow's work messy.
That is why structural rules need a small written form. When boundaries, data flow, and ownership are visible, reviewers can judge the shape of the change, not just the syntax.
Boundaries to define before review
Reviews move faster when the team decides, in plain language, what the assistant can change and what it cannot. If that line stays fuzzy, reviewers end up arguing about style while larger design mistakes slip through.
Start with the change surface. Name the files, modules, and layers the assistant may edit. Be specific. "Backend only" is too loose. "API handlers, service layer, and tests, but not database schema or deployment files" gives reviewers something they can check in minutes.
Then write down what stays out of scope. This matters even when the assistant suggests a clever shortcut. A small fix should not rewrite auth, swap a queue, or move business rules into the frontend just because the diff looks neat.
Your checklist should also name every touch point the assistant may use. That includes APIs, internal services, queues, caches, and data stores. If an output introduces Redis in a new place, adds direct database reads from a UI route, or skips the usual service call, the reviewer should catch it right away.
Keep the rules close to real code. A simple version might say:
- The assistant may change request validation, service logic, and tests.
- The assistant may call the billing API and the user service, but not unapproved third-party tools.
- The assistant may read from PostgreSQL through the service layer, not with raw queries in controllers.
- The assistant may not change event formats, auth rules, or infrastructure files without separate review.
- The assistant must follow the team's patterns for errors, logging, and retries.
Teams should also write down which patterns they accept and which they reject. If the team uses one service per domain and keeps data access in repositories, say that clearly. If the team rejects shared utility dumps, hidden side effects, and cross-layer shortcuts, say that too.
This may sound strict, but it saves time. A reviewer can compare the output against ownership lines and system boundaries instead of debating taste. That is how structural problems get caught before merge.
How data should move through the system
Start with the first moment data appears. A user types a prompt, uploads a file, or a webhook sends a payload. Write that entry point down in plain words. If reviewers cannot point to the exact input, they will miss bad assumptions later, especially when the output looks correct on the screen.
Then trace every hop, one by one. Keep the language simple: browser to API, API to worker, worker to model, model response back to the app, app to database. A review checklist should treat this like a route you can follow with your finger. If one step feels vague, that is usually where bugs and hidden costs show up.
At each hop, say what the system does to the data. One service should validate shape and size. One place should map outside fields into internal names. One place should store the final record. When teams skip this and let several services "clean up" the same payload, they create drift. Two months later, nobody knows why one field gets trimmed on one path and rejected on another.
A short review note should answer four things. Where does the data enter? Which service checks it? Which service changes its format? Which service stores it, and for how long?
Some boundaries need a hard "never." Raw prompts with personal data should never go into logs. Secrets should never pass to the model. Internal admin notes should never return to the client. Derived summaries may move across services, while source documents stay in one protected store. Reviews catch more structural mistakes when these forbidden paths are written down instead of assumed.
This also clears up ownership. The API team may own validation, the assistant service may own prompt assembly, and the data layer may own storage rules. That split works when each handoff is obvious. If it is not, the assistant starts making hidden product decisions through code paths nobody reviewed.
When a team can draw the full path in six or seven short lines, review gets faster and merge risk drops.
Who owns each decision
Teams miss structural problems when everyone can comment but no one can decide. For each service, module, or shared library, name one owner. That person does not need to write every line, but they do need to say yes, no, or not yet when assistant output changes the shape of the system.
Ownership works best when it stays narrow and visible. If the assistant adds a queue, splits a service, or moves logic across boundaries, the owner of that area reviews the change. If nobody owns it, review turns into a group chat and the merge happens on guesswork.
Code ownership and product approval should stay separate. An engineer may own the billing service code, while a product manager decides whether a billing feature should ship. Mixing those roles creates avoidable fights. One person checks whether the code fits the system. Another checks whether the change fits the product.
A small split like this usually works:
- The module owner approves design and code shape inside that area.
- The product owner approves user impact, scope, and timing.
- The data owner approves schema changes, field meaning, and retention rules.
- The tech lead or CTO breaks ties when a change crosses several areas.
Schema changes need tighter control. A new column looks small in a pull request, but it can affect reports, APIs, jobs, and old data. Pick one person or one small group to sign off on every schema change. In fast-moving teams, that gate saves time because it stops hidden breakage before it spreads.
Gray areas need a named referee. Write down who settles border disputes in one day or less. In a startup, that may be the CTO or a fractional CTO. Fast ownership matters because one assistant-written change can touch code, infrastructure, and process at the same time.
A review checklist should show owners beside each decision. When a reviewer sees a change in boundaries, data flow, or schema, they should know exactly whose approval is missing.
Turn architecture rules into a one-page review sheet
A review sheet works only if someone can read it in about two minutes and still use it during a pull request. If it turns into a mini policy document, nobody checks it when code is moving fast.
Put the rules into three groups: boundaries, data flow, and ownership. That keeps the page small and makes structural mistakes easier to spot before merge.
What the sheet should say
For boundaries, use pass or fail language. Pass if a change stays inside the module or uses an approved interface. Fail if it reaches into another service's internals, shared database tables, or private helper code. A chat assistant can call the billing API, for example, but it should not write directly into billing tables because that breaks the service boundary.
For data flow, pass if the request path is easy to trace from input to storage to output. Fail if data skips validation, gets copied into side channels, or moves through hidden background jobs with no clear reason. User text might enter the assistant service, get filtered, then go to the model while logs keep only safe metadata. Raw prompts should not land in analytics by default.
For ownership, pass if one team or one named owner decides schema changes, interface changes, and rollback steps. Fail if the pull request forces another team to clean up the result later. If the platform team owns event contracts, a feature team can propose a new event, but the platform team should approve the final shape.
Each line should read like a gate, not advice. "Pass if" and "Fail if" wording removes debate and speeds up review.
A small startup team can keep this on one page and still cover the common failure points. That matters even more when one person acts as founder, reviewer, and part-time CTO, because fuzzy ownership leads to rushed merges.
If you want a checklist people will use, cut anything that needs a meeting to explain. The sheet should help a reviewer say yes, no, or ask one sharp question.
Review assistant output before merge
Start with the change summary, not the diff. If the summary is vague, the review already has a problem. A good summary tells you what changed, why it changed, and which parts of the system should stay untouched.
Then compare the touched files with the boundaries you set earlier. If a small UI fix also changes job workers, database models, or billing code, stop and ask why. Most structural mistakes show up as file changes that do not match the stated scope.
This is where a checklist helps. It keeps the review focused on structure, not just style.
A simple review flow works well. Read the summary and write the intended path in one sentence. Check whether the changed files fit that path and nothing else. Trace the data from input to processing to storage. Confirm who owns each risky area and whether that person reviewed it. Reject any change that creates a side path, a duplicate write, or a hidden state update.
Data flow needs a real trace, even for a small pull request. Follow one input all the way through. Ask where it enters, where code changes it, where the app stores it, and who reads it later. If you cannot trace that path in a few minutes, the change is too messy for a safe merge.
Hidden writes are a common problem with assistant output. A generated change may add a cache update, an analytics event, a background job, or a fallback save that never appears in the summary. The code may still pass tests. It can still break ownership and make future bugs hard to find.
Reviewers should also check the owner map. If the change touches auth, payments, or customer data, the right owner needs to sign off. A general reviewer can catch syntax issues. They should not approve boundary changes alone.
Rejecting a merge for structure is often the right call. Clean code in the wrong place still makes the system harder to run. A short delay before merge is cheaper than a week of cleanup after release.
A simple example from a startup team
A startup asks an assistant to add a support form. The generated code looks fine at first glance. It has a clean UI, a submit button, and a success message. The risk sits under the surface.
The clean version is simple. The form sends one request to a backend API such as POST /api/support-requests. That API checks the input on the server, strips junk data, attaches the logged-in user ID from the session, and writes one new record to the database. After that, it triggers one follow-up action, such as a notification job.
That path keeps the boundaries clear. The browser collects input. The API owns validation and permission checks. The database stores the final result. Each part does one job.
The bad version often looks faster because the assistant tries to be helpful. It adds client-side checks, then lets the frontend call two places at once: one endpoint for a ticket record and another for an email log. Sometimes it trusts a hidden form field for the account ID. Now the same submission can write twice, store mismatched data, or let a user send a ticket under the wrong account.
A reviewer can miss that if they focus only on whether the form works. It does work. It just breaks the system rules.
A checklist helps because it forces a few blunt questions:
- Does the browser send data to one approved API?
- Does the server validate and assign ownership fields?
- Does one action create one database record?
- Does any side effect happen after the main write, not beside it?
Those four checks catch most of the trouble. If the output sends data straight from the form into multiple writes, the reviewer stops it. If validation happens only in JavaScript, the reviewer stops it. If ownership comes from the client instead of the server session, the reviewer stops it.
This is why rule sheets work better than taste-based review. A nice interface can hide structural mistakes. A short checklist gives the reviewer a fixed standard, so they can reject code that crosses boundaries even when the demo looks polished.
Mistakes that slip through reviews
Most review mistakes look harmless in a diff. The code is tidy, tests pass, and the output reads well. The problem sits one level deeper: the change bends system rules in a way that will cost you later.
A common miss is the cross-service call added for convenience. The assistant sees two services, notices one already has the data, and wires them together to save a step. That feels efficient in the moment, but it often creates a hidden dependency, slower requests, and a new failure path nobody planned for.
A startup team might see this when the account service starts calling billing directly during login just to check plan status. It works. Then billing slows down, login slows down, and one team ends up owning a problem that started in someone else's area.
Another problem slips in through helper code. The diff says "refactor" or "cleanup," but the new helper does more than format or validate data. It also writes to a table, updates a cache, or emits an event. That kind of change is easy to miss because the write is buried behind a friendly function name.
These changes often pass review because they look small. A utility method now saves state. A read path now triggers a side effect. A service imports one more client "just for this case." A background job starts owning business rules.
Ownership checks also get skipped on small changes. A reviewer may think, "It is only 20 lines." But a tiny patch can still move a decision from one team to another. If pricing logic appears inside checkout, support, and analytics code, nobody really owns pricing anymore.
This is where vague rules fail. Teams write lines like "keep boundaries clean" or "avoid tight coupling," and everyone nods. Then a real pull request appears, and those rules give no clear answer. A useful architecture review checklist needs rules a reviewer can apply to a diff without debate.
Good rules sound plain. "Profile service can read profile data only." "Billing writes billing records only." "Helpers do not write unless their name says so." These rules may sound almost too simple, but they catch more structural damage than clever wording ever will.
When assistant output is involved, plain rules matter even more. The assistant is very good at making a shortcut look reasonable. Reviews catch more when the team checks boundaries, data writes, and ownership before admiring how neat the code looks.
Quick checks and next steps
A review goes faster when the team uses the same three questions every time:
- Where does this data go after it enters the system?
- Who owns this logic, table, service, or workflow?
- What boundary changed, even if the feature still works?
If a reviewer cannot answer all three in a minute or two, the change probably is not ready. Good output can still hide a bad split of responsibilities, a new data path, or logic placed in the wrong layer.
Keep these rules close to the codebase docs, not in a slide deck nobody opens. Put them next to API notes, service ownership docs, schema rules, and review templates so engineers see them while they work.
For many teams, one page is enough. It often works better than a long policy because people will actually use it during pull requests.
Failed merges are useful if you treat them as feedback. When a change slips through and causes rework, add one plain rule that would have caught it. Over time, the review sheet gets sharper and easier to trust.
A small startup team can do this without heavy process. If one assistant-written change lets a UI layer write user data straight into reporting tables, that is a rule failure, not just a coding mistake. The next rule might say that only backend services can write reporting data, and reviewers must check that path.
If a team needs help turning that into a lightweight process, Oleg Sotnikov at oleg.is works with startups and smaller companies as a Fractional CTO. His focus is practical: tighter architecture rules, clearer ownership, and AI-augmented development that does not turn into review chaos.
Start small. Write the three questions down, store the rules with the docs, and update them after each avoidable review miss.


