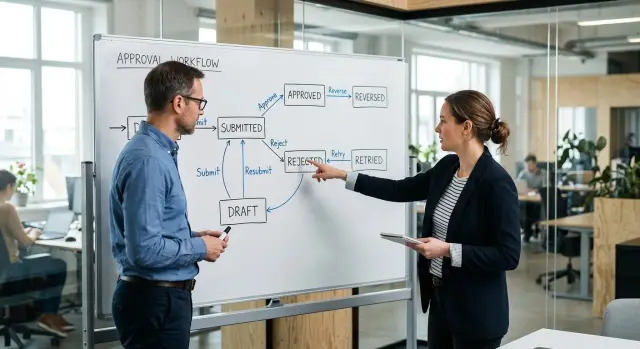
Rule engine vs code for approval workflows: how to choose
Rule engine vs code for approval workflows depends on how often rules change, who updates them, and what audit trail your team needs.

Table of Contents
Why this decision gets expensive later
An approval flow that looks clean in month one usually picks up extra rules fast. A manager approval for any purchase over $1,000 sounds simple until finance asks for a second check on software renewals, legal wants contract review, and urgent orders need a faster path.
Those exceptions rarely arrive all at once. They appear one by one, usually after a missed invoice, a risky vendor, or a complaint from a team that got stuck waiting. Each small fix feels harmless, but it changes cost, speed, and accountability at the same time.
If you bury those rules in application code too early, the workflow splits into paths that nobody sees unless they read the code. One request follows the normal route. Another skips a step because of department, amount, region, or vendor type. A third exists only because someone added a special case six months ago and never wrote it down.
The pattern is familiar. Larger amounts need extra approval. Contractors or new vendors follow a different route. Emergency requests bypass steps and get reviewed later. Department limits drift away from company limits. Regulated purchases end up with separate handling.
At that point, the cost is no longer just developer time. Product teams wait longer for changes. Finance loses trust because the policy lives in pull requests instead of a clear document or tool. Audits get harder because people have to explain why two similar requests took different paths and who approved each step.
This is where the choice between a rule engine and code starts to hurt. The first version is cheap either way. The real bill shows up when the business changes faster than the workflow. A shortcut that saved two days at the start can turn into months of patches, rework, and awkward questions later.
What actually changes in approval rules
Most teams assume approval rules will stay mostly fixed. They rarely do. The first version is usually simple, but growth, budget pressure, and new controls keep changing the details.
Approval limits usually move first. A company may start with manager approval over $2,000, then raise the limit after the team grows, then tighten it again when spending comes under review. If every threshold lives in code, even a small policy edit becomes a ticket, a test cycle, and a deployment.
The path can change even when the form does not. A purchase from an approved vendor might need one approval, while a new vendor, a higher amount, or a request from another region might trigger finance, legal, or security review. That is where approval workflow design gets messy. The flow looks stable, but the conditions around it keep shifting.
Urgent cases add another layer. A broken laptop for a new hire, a rush software renewal, or a temporary spending freeze can create exceptions that last a week or a month. Teams often add those overrides quickly and then forget them, especially when they sit deep inside application logic.
Policy owners also revisit rules more often than engineers expect. Finance may change spend bands. Operations may add regional checks. Leadership may ask for a second approval for certain vendors after one bad incident.
You can usually spot the moving parts early. Spending thresholds change with budget size. Certain regions or vendors need extra review. Temporary exceptions appear during urgent periods. Finance or operations rewrites policies more often than engineering expected.
That is why this decision should start with change frequency, not architecture preference. If the sequence stays the same but policy owners keep adjusting conditions, the rules are the moving part. Treat that part carefully.
Who will edit the workflow
When teams compare a rule engine with plain code, one question clears up a lot of debate: who will keep the rules correct after launch?
Developers can change code quickly when the rules are stable and easy to explain. That works well if the same team owns the app, understands the policy, and can ship a fix without delay. Trouble starts when the people who know the rule best do not read code and do not want to wait for engineering time.
In many companies, finance or operations knows the messy details. They know which spend needs a director, when a contractor request needs extra review, and which exception the CEO approved last quarter. If those details live only in code, the people who own the decision can spot mistakes, but they cannot fix them.
That matters most on a Friday afternoon. A payment gets stuck. A manager says the approval path is wrong. Who can safely change it before the weekend? If the answer is "only one backend engineer," you have a people problem, not just a tooling problem.
Ask four plain questions. Who writes the rule today in real life? Who notices first when the rule is wrong? Who can approve a change to that rule? Who can make the fix without risking other parts of the system?
If one small product team owns all four answers, code may be fine. If the answers are split across engineering, finance, and operations, a rule engine usually fits better because it puts rule editing closer to the people who own the policy.
Take a simple case. Purchase requests under $500 go to a team lead, over $500 go to finance, and anything from a new vendor needs another review. Finance will probably refine those thresholds and exceptions more often than engineering expects. Giving that team a safe way to edit rules can save days of back and forth.
Match the tool to the people who carry the risk when a decision goes wrong. That is usually the clearest answer.
What you need to prove in an audit
Audits usually ask for history, not screenshots. You need to show the exact path a request took, the people involved, and the rule set that existed on that day.
A clean workflow audit trail answers four direct questions: who approved or rejected the request, when each step happened, which rule sent it to that person, and which rule version was active at that moment.
If your system only stores the latest workflow, you have a gap. A purchase request approved in March may follow a different policy in July. If your team overwrites old rules, you cannot prove why the March request went to a department head instead of the CFO.
A simple example makes the problem obvious. Say a $7,500 request routed to finance because the policy said "over $5,000 needs finance review." Three months later, the limit changed to $10,000. An auditor may still ask why that older request went through finance. You need the old rule version, not the current one.
To rebuild the decision later, store the request amount, type, and requester. Keep each approval or rejection with names and timestamps. Record the exact rule version that matched, the condition that triggered the route, and any manual override with the comment behind it.
Code can handle this, but only if your team keeps strict records. That means tagged releases, deployment logs, and decision logs that tie a request to a specific code version. Many teams skip that discipline when deadlines get tight.
A rule engine often helps because versioning and decision logs sit closer to the workflow itself. That does not make it better by default. It just lowers the chance that audit evidence gets scattered across pull requests, app logs, and someone's memory.
Permissions matter too. Decide who can change rules, who can publish them, and who can only review results. Keep those roles separate when approvals affect money, contracts, access, or compliance. If one person can edit a rule and approve the request it controls, you are creating a risk you do not need.
When audit pressure is high, choose the option that makes old decisions easy to explain six months later. If your team cannot do that in a few minutes, the workflow needs better records.
When plain code still works well
Code is often the better choice when approval rules stay stable for long stretches. If the policy changes once or twice a year, a rule engine can add more moving parts than you need. A small team may spend more time learning, wiring, and testing the tool than it would spend editing a few lines of code.
If developers own every workflow update, code keeps the process clear. Someone asks for a change, an engineer updates the service, runs tests, and ships it with the next release. It is plain, but plain is good when the workflow is small and the owner is obvious.
Code also fits when one small service handles the whole flow. If a single app checks the request amount, team, and approver chain, the logic stays close to the data and logs. That makes bugs easier to trace. When an approval stalls, the team has one place to inspect.
A simple purchase request flow is still easy to keep in code: requests under $1,000 go to a manager, requests above $1,000 go to finance, and contractor purchases need one extra approval. That is readable, easy to test, and easy to review in a pull request.
Skip extra tooling when the workflow has only a few branches and nobody outside engineering needs to edit them. A rule engine may make sense later, but adding one too early creates extra setup, extra permissions, and another place where things can break.
For many small companies, that setup is enough for a long time. If the rules are stable, the dev team owns every change, and one service runs the whole process, code is usually the cleaner option.
When a rule engine makes life easier
A rule engine helps when approval policy changes often enough that code releases start to feel like a tax. If finance changes spending limits every month, or legal updates review steps after each new contract type, hardcoded logic gets old fast. Developers end up doing small edits, testing them, waiting for release windows, and answering the same questions again.
This is where the decision starts to tilt. You want routing logic to move at the speed of policy, not at the speed of your app release process.
A rule engine also helps when the people who own the policy do not write code. A finance lead, operations manager, or compliance owner may not need to edit rules alone, but they should be able to read them and say, "Yes, this matches our policy." If they can review logic in plain conditions and clear steps, you cut down on translation errors between business and engineering.
Release delays matter more than many teams expect. Say a purchase request over $15,000 suddenly needs both department approval and procurement review. If your team ships once every two weeks, that delay can leave requests in limbo or push people into manual workarounds. A rule engine lets you change routing without bundling it into a larger app release.
It becomes even more useful when audit needs are strict. People will ask which rule approved the request, who changed that rule, when the new version went live, and who signed off on the change.
Plain code can answer some of this, but it usually takes more effort. A good rule engine keeps rule versions, approval history, and effective dates in one place. That makes audits less painful and policy change management much cleaner.
If your workflow changes often, several people need to review the logic, and release timing hurts operations, a rule engine usually pays for itself fairly quickly. It removes a lot of small, avoidable friction.
A practical way to choose
If you're weighing a rule engine against code for approval workflows, do not start with the tool. Start with the rules themselves. Most teams argue about architecture before they can even say, in plain English, what gets approved, by whom, and why.
Write every rule as a short sentence that a non-engineer can read. For example: "Finance approves any purchase over $5,000" or "A manager approves travel outside the home country." This flushes out hidden logic fast. Teams often find that two people describe the same policy in different ways, which usually means the workflow will drift later.
Then sort each rule by how often it changes. Some are rare, like a fixed compliance step. Some change a few times a year after budget reviews or team changes. Others move all the time, like spending limits, approver names, or exceptions for urgent requests.
That one pass tells you a lot. Rare rules usually fit well in code. Frequent rules are where policy change management gets painful if every edit needs an engineer and a deploy.
Next, name the real owner of each rule. Some rules belong to engineers because they depend on system behavior. Others belong to finance, operations, or managers because they reflect company policy. If a rule belongs to finance but only developers can change it, you already have a mismatch in business rules ownership.
After that, define the audit record each rule needs. Do you need to show who approved, when they approved, what rule fired, and which policy version applied? If yes, design the workflow audit trail before you choose the implementation.
Use one live workflow as a test case. Purchase requests work well because they usually involve budget limits, department managers, and exceptions. Make one policy change, run one request through the full path, and watch what happens. If that small change needs a code edit, review, deploy, and manual explanation for auditors, a rule engine may save you pain. If the change stays rare and the logic stays simple, plain code is often enough.
Example: purchase requests in a growing company
A small company can live with approval logic in code for a while. Picture a 10-person team with one simple rule: if a purchase request goes above $1,000, the manager must approve it. A developer adds that check in a day, and nobody complains.
At that size, the rule barely changes. The person who asked for the change probably sits a few desks away from the person who shipped it.
How the workflow grows
By 40 people, the request no longer stops with one manager check. Finance wants to block new vendors until someone verifies tax details. Department leads want budget checks before approval. Operations wants a different path for software subscriptions than for office equipment.
Now each new policy change waits for engineering time. A finance lead says, "Raise the limit for marketing tools, but only for the EU team this quarter," and that small request turns into a ticket, a code review, a test run, and a deployment.
At 80 people, the mess gets harder to ignore. Regional rules pile up because Germany handles invoices one way and the US another. Temporary exceptions never stay temporary. One team gets a special threshold during hiring season. Another gets a faster path for urgent vendor renewals. Nobody feels sure which rules still apply.
At that point, the question is no longer theoretical. The problem is change.
What the team needs now
At this stage, the company usually needs one owner for policy changes, often finance or operations. It needs version history that shows who changed a rule and when, a workflow audit trail for each request, and faster updates without waiting for the next release.
If the team keeps every rule in code, developers become policy clerks. They spend time editing thresholds, exception lists, and routing rules instead of improving the product.
A rule engine will not fix bad approval workflow design by itself. But in this kind of company, it can separate stable application code from business policy that changes every month. That split makes daily work calmer. Finance can own the rules, engineering can guard the system, and auditors can see why request 1842 passed while request 1843 stopped.
Mistakes that trap teams
Teams get into trouble when approval policy ends up in three places at once. One rule lives in a controller, another in a background job, and a third in a database script that someone added during a late fix. The workflow still runs, but nobody can explain the full decision path without reading code for an hour.
It gets worse when the same rule leaks into email text and screen checks. A request form might warn that purchases over $5,000 need director approval, while the backend now uses $7,500 because a developer changed one condition and missed the rest. Users see one policy. The system follows another.
Exceptions cause even more damage than bad defaults. Teams add a quick bypass for a rush order, a special vendor, or one senior employee. Then they leave it there. If nobody owns that exception, and nobody sets an end date, a temporary patch turns into normal policy.
A small growing company feels this fast. Finance asks for a one-off shortcut for end-of-quarter purchases. Engineering adds it in code. Six months later, nobody remembers why it exists, but it still skips one approval step for the wrong cases.
A few habits prevent a lot of this. Write each rule change as one plain test case before you ship it. Record who owns the rule and when you will review it. Keep policy text separate from UI copy and notification templates. Note decisions when you make them, not when auditors ask.
The test case does not need fancy tooling. A short sentence often works: "If a contractor submits a software purchase above $3,000, the department head and finance must approve it." That single line gives developers, operations, and managers the same reference point.
Waiting for an audit to document decisions is usually the most expensive mistake. By then, people disagree, logs are messy, and old rule changes look accidental. A simple changelog with the rule, the reason, the owner, and the date saves a lot of pain later.
Quick checks and next steps
A fast way to judge this choice is to look at what already happened in your team. Old changes tell the truth better than future plans. If rules changed every few weeks, people argued about exceptions, or approvals stalled because only one developer knew the logic, take that seriously.
Keep the review short. Look back six months and count real rule changes, not just feature releases. Three or four policy edits may already be enough to make hardcoded logic annoying. Ask who can update the workflow safely today. If the honest answer is "only a developer who knows this service," ownership is too narrow. Pull one approval from last quarter and explain why it was accepted, rejected, or escalated. If nobody can trace the decision step by step, your workflow audit trail is weak. Then write out one workflow on a page before you choose any tool, including inputs, rules, exceptions, and who owns each rule.
After that, pick one workflow only. Purchase requests, refund approvals, or vendor onboarding all work well for a first pass. Keep the first version boring. If plain code covers the rules, the owner is clear, and you can explain each decision later, code is fine. If policy change management already eats time and business rules ownership sits outside engineering, a rule engine will probably age better.
This is also where teams overbuild. They buy a large workflow product before they can describe one clean approval path. That usually creates more places for messy policy to hide.
If you want a second opinion before you commit, Oleg Sotnikov at oleg.is does this kind of work as a Fractional CTO and startup advisor. A short review of the workflow, ownership model, and audit needs can save a lot of rework later.