AI workflow observability for business process bottlenecks
AI workflow observability helps operations teams track queue age, handoff time, approval rate, and rework so they can find the real bottleneck sooner.
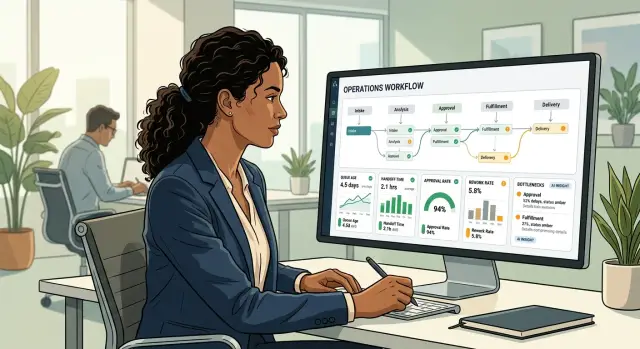
Table of Contents
Why fast AI can still leave work stuck
A model can answer in 12 seconds, yet the job still finishes tomorrow morning. That happens when the slow part is not the AI step. Work usually waits before the model runs, after it runs, or between the people who need to review it.
Most business processes move in bursts and then stop. A document enters a queue. Someone checks it when they have time. AI extracts fields or drafts a response, and then the item lands in another queue for approval, correction, or handoff. The model can easily be the fastest part of the chain.
Queues hide the problem because they look like work in progress even when nothing is moving. Ten invoices can sit untouched for three hours before anyone opens them. A support request can get an AI summary right away, then wait half a day for a manager decision. If you only watch model latency, everything looks fine. Customers and staff still feel the delay.
Human handoffs add more drag than most teams expect. Every transfer creates a pause. Someone misses a notification, asks for missing context, or checks the same work again because they do not trust the last step. Approvals make this worse. One sign-off sounds minor, but several sign-offs across finance, legal, or operations can turn a ten-minute task into a two-day task.
Rework wipes out the time AI saves. If AI drafts an answer in 30 seconds but an employee spends 15 minutes fixing tone, facts, or missing details, the gain disappears. If a bad extraction sends a file back to the start, the process slows again because the item joins the queue a second time. Many teams count the first completion and miss the second pass.
This is where AI workflow observability matters. Track queue age, handoff time, approval rate, and how often work loops back for another try. Those numbers show where the process actually stalls. Once you measure the whole path, you can see whether the fix is a faster model, fewer approvals, better prompts, or a simpler workflow.
Metrics that show where work slows down
Fast model response time can fool you. In AI workflow observability, the slow part often sits around the model, not inside it. Work waits in line, moves slowly between teams, or comes back for fixes.
Queue age is the easiest metric to explain. It is how long a task has been waiting in its current step. If an AI system classifies a request in 10 seconds, but that request sits untouched for 14 hours before anyone reviews it, the real delay is the queue.
This number shows pressure building before people notice it. A growing queue age usually means one of three things. Too much work arrived at once, items went to the wrong place, or the next team does not have enough time to keep up.
Handoff time measures the gap between one step ending and the next step starting. It is different from queue age, but the two often rise together. One team finishes its part, yet the next team does not pick it up until much later.
That gap sounds small on paper, but it adds up fast. If every handoff burns 20 minutes and a task changes hands four times, you lose more than an hour before anyone does real work.
Approval rate shapes throughput more than many teams expect. When most items pass on the first review, work keeps moving. When approval rate drops, reviewers spend longer on each case, managers step in more often, and the backlog grows behind them.
Rework is repeated effort after a task returns for correction. Teams often count it as normal work, but it is not. If someone fixes the same request twice because the AI draft missed fields or chose the wrong template, that is rework.
Exception volume tracks work that falls out of the normal path. These are the awkward cases: missing documents, duplicate records, unclear policy matches, or anything that needs manual escalation. A few exceptions are normal. A rising share of exceptions usually means your inputs are messy or your rules are too strict.
A weekly review gets clearer when you ask a few direct questions:
- Which step has the oldest queue?
- Where does handoff time jump?
- Did approval rate drop?
- How much work came back for rework?
- What share became exceptions?
Taken together, these metrics show the real bottleneck. The model may be fast. The process around it may still be slow.
Start with a simple workflow map
Before you measure anything, draw the path the work actually takes. Many teams jump into dashboards too early and end up tracking model speed while the real delay sits in an inbox, an approval queue, or a handoff nobody owns.
Start with one common request and follow it from the first trigger to the finished outcome. Use plain boxes and arrows on a single page. If a new customer request turns into five approvals, two edits, and one final delivery, put all of that on the page in order.
For AI workflow observability, the map should show more than where the model runs. It should show where people stop, check, edit, approve, or send work back. That is where business process metrics become useful later.
A simple map works best when each step answers a few basic questions: what happens here, who does it, where the work waits before the step starts, and who owns the handoff to the next step.
Mark AI actions and human decisions differently. A small label is enough. You might note "AI drafts reply" and then "team lead approves or edits." That makes it easy to see where automation helps and where human judgment still controls the pace.
Pay close attention to waiting points. Teams often forget these because no one thinks of an inbox or queue as a real step. It is a step. If requests sit in email for six hours before anyone opens them, that delay belongs on the map. The same goes for ticket backlogs, shared chat channels, "waiting for review" columns, and approval folders.
Handoffs need names, not job titles alone. "Finance reviews" is less useful than "accounts payable lead reviews." When a handoff has no clear owner, work drifts. People assume someone else will pick it up, and handoff time grows without anyone noticing.
Keep the first version small. One page forces you to focus on the normal path instead of every rare exception. If the map gets crowded, cut it back to the path that handles most of the volume.
A good first map looks almost too simple. That is fine. If an operations lead can read it in one minute and point to every queue, decision, and owner, you have something you can measure.
How to measure the workflow step by step
Choose one workflow that begins and ends in plain view. A good first pick is something routine, such as an access request, a customer refund, or a purchase approval. If the start or finish is fuzzy, your numbers will be fuzzy too.
For AI workflow observability, the process matters more than the model call. Many teams log when the AI answered and stop there. That leaves out the part where work sits in a queue, waits for a person, gets sent back, or needs a second review.
The minimum setup is simple. Add a timestamp every time the work changes hands or status: when the request enters the workflow, when the AI finishes its part, when a person or team receives the task, when that person first acts on it, and when the work is approved, returned, or closed.
Those timestamps let you measure queue age tracking and handoff time without guessing. If one manager opens tasks six hours after receiving them, you can see it. If the AI finishes in 20 seconds but the next step waits until tomorrow, the delay is no longer hidden.
Names matter too. Log who received the task, or at least which team did. Two people can have the same approval step on paper and very different response times in real life. You are not trying to watch people too closely. You are trying to see where work piles up.
Rework needs its own markers. Count every return, edit, second approval, and resend. When a task loops back, record why it happened. A short reason like "missing field" or "policy mismatch" is enough. Over a week, approval rate and rework analysis will tell you whether the process is clear or whether people keep fixing the same problem.
Keep the first review period short. One week is often enough to spot patterns, and it keeps the setup light. If you add ten metrics on day one, most teams stop checking them.
A small, clean set of business process metrics is better than a big dashboard nobody trusts. After one week, look for the longest wait, the most common rework reason, and the step with the lowest approval rate. That gives you a real starting point for change.
A simple example: invoice approval with AI
An invoice workflow shows why fast AI does not always mean fast operations. A model can read a PDF in seconds, yet the invoice can still sit for two days before anyone approves it. That gap is what AI workflow observability should expose.
Say a supplier emails an invoice. The system captures the file, runs AI extraction, pulls out the supplier name, PO number, due date, amount, and cost center, then sends the record to finance. A finance reviewer checks the fields, fixes obvious errors, and routes the invoice to the manager who owns the budget. The manager approves or rejects it, and the payment team schedules payment.
If you only watch model latency, the numbers look great. The extractor returns data in 12 seconds. Finance review takes 4 minutes. The full cycle, though, takes 31 hours. Most of that time sits in one place: the manager approval queue.
A simple scorecard for this workflow should track queue age before finance review, handoff time from finance to the manager, wait time in the manager queue, approval rate on first review, and rework when staff send invoices back for fixes.
Those numbers tell a clearer story than "the AI is fast." Imagine 100 invoices this week. The model handles all 100 in under 20 seconds each. Finance accepts 82 on the first pass, but sends 18 back because the PO is missing, the vendor name does not match, or the total looks wrong. Managers approve 63 the same day, 29 the next day, and 8 after that. Now the constraint is obvious.
Rework matters because it creates delay that most dashboards miss. When finance sends an invoice back, someone has to find the missing detail, correct the record, and route it again. One small extraction error can add six hours if the invoice misses the manager's normal approval window.
That is why total cycle time matters more than model response time. If the model saves 40 seconds but the manager queue adds 24 hours, the business problem is not model speed. The problem is routing, ownership, or approval habits.
Teams usually find one of two issues. Too many invoices go to manual correction, or too many ready invoices wait for one busy manager. When you measure queue age, handoff time, approval rate, and rework together, you can decide whether to fix extraction quality first or change the approval path.
Mistakes that hide the real bottleneck
A fast model can still sit inside a slow process. Teams often celebrate a 2-second AI response while the task waits 6 hours for a person to review it, fix it, or move it to the next system. Good AI workflow observability looks past the model call and follows the work until someone finishes it.
The first mistake is staring at API latency and little else. Model speed matters, but it rarely explains why work piles up. If queue age keeps rising, the problem is often staffing, approvals, missing data, or a messy handoff between tools. A quick model does not help much when items wait all afternoon in a review queue.
Another common mistake is mixing very different cases into one neat average. That average usually hides the messy work. A simple invoice from a known vendor might pass in two minutes, while an invoice with missing tax data might bounce around for a day. If you blend both into one number, you lose the story. Split the process by type, risk level, source, or exception reason.
Teams also miss the work that leaves the normal path. This is where time and cost often grow. Maybe the AI extracts the wrong field, then someone fixes it in a spreadsheet. Maybe a manager asks for more proof in chat, and the case sits there until the next morning. If your dashboard only tracks the clean path inside one tool, you miss the part that hurts.
Hidden manual fixes make this worse. People patch broken steps in email, chat, side notes, and quick calls because they want to keep work moving. That is practical in the moment, but it makes the process look healthier than it is. If three people quietly repair bad outputs before approval, your approval rate looks fine while rework stays invisible.
Too many metrics can hide the truth too. Teams sometimes add twenty charts before they trust four basic numbers. Then nobody knows which number matters, or whether the data is even clean. Start small. Check that the timestamps are real, the status changes are consistent, and the exceptions actually get logged.
A few warning signs usually mean your dashboard hides the bottleneck. Model speed looks great, but queue age keeps growing. One average covers simple cases and messy cases together. Approval numbers look fine, but people still fix work in private messages. Rework appears low because nobody records off-system corrections.
If you clean up those mistakes first, the bottleneck usually becomes obvious. It might be a reviewer, a handoff, an exception type, or a missing rule. Then you can fix the process instead of blaming the model.
Quick checks for a weekly review
A weekly review works best when it stays short and looks at the same numbers every time. Ten or fifteen minutes is enough if the team focuses on where work waited, who picked it up, and how often it came back for edits.
Fast model output can hide a slow process. AI workflow observability helps when it tracks the business path around the model, not just the model call itself.
Use one simple review sheet for every workflow. Look at the single oldest item in each queue, not just the average age. Check the gap between when a team receives work and when someone first acts on it. Compare approval rates by step and by owner. Count how many tasks come back for edits, then ask whether one rule change or one form change would stop that rework next week.
A small example makes this clear. Say an operations team uses AI to draft purchase requests. The model finishes in seconds, but final approval still takes three days. The weekly check shows that finance opens requests late on Mondays, and 30% of requests return because one cost-center field is often missing. That is not an AI speed problem. It is a queue problem and a form problem.
This review works better when teams avoid broad debates. Do not spend the meeting arguing about every exception. Pick the biggest blockage you can fix quickly.
Most weeks, the best fix is plain: add one required field, change one routing rule, set a response window for one team, or remove one approval that adds no real control.
Then check the same numbers again next week. If queue age drops, handoff time gets shorter, and fewer tasks bounce back, you fixed the right thing. If nothing moves, keep the review simple and inspect the next step where work waits.
What to do next with the numbers
Numbers help only when they lead to one clear change. If queue age is high, handoff time is low, and approval rate looks fine, do not try to fix all three. Pick the bottleneck that blocks the most work and set a small target you can reach in a short window.
Keep that target plain and specific. A good example is cutting average queue age from 18 hours to 6 hours in the next two weeks. Small targets are easier to test, and they keep teams from arguing over abstract goals.
Change one thing at a time. That might be one approval rule, one owner, or one extra review step that no longer earns its place. If you change the prompt, the routing logic, and the approval policy in the same week, you will not know which move helped.
A simple record is enough for most teams. Note the date of the change, the single change you made, the metric before the change, the metric one or two weeks later, and one short note about what staff noticed.
This log keeps the discussion honest. If approval rate went up but rework also jumped, the process did not really improve. You only moved the mess downstream.
Share the numbers with both operations and product leads. Operations leaders often spot policy problems first, such as too many approvals or unclear ownership. Product leads often see software issues, such as a bad handoff, missing status, or AI output that forces people to redo work.
A short weekly review usually works better than a long monthly meeting. Put the trend on one screen, name the current bottleneck, and decide on one test for the next week. That rhythm is boring in a good way. It keeps teams focused on flow instead of opinion.
When a workflow crosses AI, software, and several teams, setup gets harder fast. In cases like that, outside help can save time. Oleg Sotnikov at oleg.is works with startups and smaller businesses on AI-first software development, automation, and Fractional CTO support, so he can help teams decide what to instrument first without turning the project into a heavy reporting exercise.
Good numbers should lead to the next small fix. If they do not change a decision, track less and act more.
Frequently Asked Questions
What does AI workflow observability actually mean?
It means you track the full path of the work, not just the model call. You log when a task enters the workflow, where it waits, who picks it up, when it loops back, and when it closes.
That gives you the real source of delay. Sometimes the model runs fast, but a queue, approval step, or bad handoff slows everything down.
Why can a fast AI system still leave work stuck?
Because the model often finishes before the hard part starts. Work can sit in an inbox, wait for approval, or come back for edits long after the AI step ends.
If a draft takes 20 seconds but a manager reviews it tomorrow, the process still feels slow to staff and customers.
Which metrics should I track first?
Start with queue age, handoff time, approval rate, and rework. Those four numbers show where work waits, where ownership breaks, and where people keep fixing the same task.
If you want one more metric, track exception volume. That shows how much work falls out of the normal path.
How do I measure queue age in a simple way?
Log the time when a task enters a step and the time when someone first acts on it. The gap between those two timestamps gives you queue age.
Watch the oldest item too, not just the average. One very old task often tells you more than a smooth-looking average.
What is the difference between queue age and handoff time?
Queue age tells you how long work waits inside a step. Handoff time tells you how long the gap lasts after one step ends and before the next one starts.
They sound similar, but they point to different problems. Queue age often points to backlog, while handoff time often points to weak ownership or slow pickup.
How do I know if rework is the real problem?
Count every return, correction, resend, and second review. Then record a short reason, such as missing field, wrong template, or policy mismatch.
When the same reason shows up again and again, rework is eating your time. Fix the form, rule, prompt, or routing at that source.
Should I map the workflow before I build a dashboard?
Yes. Draw one common workflow on a single page before you open a dashboard tool. Show each step, each waiting point, each owner, and where AI acts versus where people decide.
That simple map stops you from measuring the wrong thing. Many teams chase model speed while the real delay sits in an inbox or approval queue.
What should I look at in a weekly review?
Keep it short and use the same numbers every week. Check the oldest item in each queue, look for slow pickups, review approval rates, and find the top rework reason.
Then choose one small change for the next week. A short review works better than a long meeting full of debate.
What changes usually improve workflow speed first?
Fix the bottleneck that blocks the most work first. That often means removing an extra approval, adding one required field, setting a clear owner, tightening a routing rule, or improving the AI input.
Change one thing at a time. If you change three things at once, you will not know what helped.
When does it make sense to get outside help?
Bring in help when the workflow crosses several teams, tools, and approval steps, and nobody agrees on where the delay starts. Outside support also helps when your team logs a lot of data but still cannot turn it into one clear change.
Oleg Sotnikov works with startups and smaller businesses on AI-first software development, automation, and Fractional CTO support. He can help you decide what to instrument first and keep the setup lean.


