Why AI transformation stalls in middle management teams
Why AI transformation stalls after a strong pilot: middle managers lack clear authority, rules, and ownership, so teams hesitate, split work, and slow down.
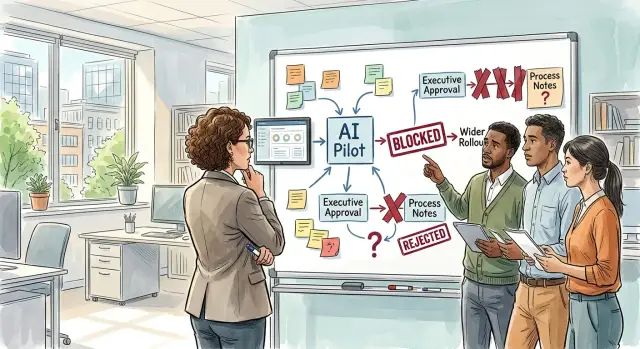
Table of Contents
What changes after a good pilot
A good pilot proves one narrow point: the tool works in a controlled test. That matters, but it does not change daily work by itself. The team still has the same meetings, the same approval chain, and the same fear of making the wrong call.
That is where many companies stall. The demo looked clear. Real work does not. A manager hears that AI should help with reports, support replies, or internal research, but nobody gives them a plain rule that says what they can change today.
Without that authority, even small fixes stop. Can the team change a support workflow? Can they let AI draft customer replies? Can they store prompts, or does legal need to review them first? When nobody answers clearly, managers do what feels safest. They wait.
The problem gets worse when departments give different answers. IT may allow the tool, security may ask for another review, and HR may want new policy text before anyone changes a task. Each answer makes sense on its own. Together, they stop progress.
So the pilot turns into a showpiece instead of a routine. People use the tool for a week, then questions pile up. Someone gets a strange output, someone else worries about compliance, and a team lead decides it is faster to go back to the old way.
The issue is rarely the model itself. Most of the time, the missing piece is basic operating permission: who can approve process changes, what the team may automate, and when they need review.
A support manager is a simple example. During the pilot, agents use AI to draft replies and save about 20 minutes a day. After the pilot, the manager wants to add a review step and update the template library. With no written authority, no shared rule, and no owner for approval, the change goes nowhere. The team keeps doing manual work even though the pilot already showed a better option.
Why middle managers freeze
Middle managers sit in the hardest spot during an AI rollout. They carry weekly targets, team complaints, and the blame if something goes wrong. But they often do not control the budget, the tool choice, or the rules for using AI in daily work.
A pilot can look great because it runs inside a small test. One team tries one tool against one clear metric. After that, a manager has to answer messier questions: who can use it, what data can go in, who pays for it, and what happens when the output is wrong.
Pressure comes from both sides. Executives want faster results and lower costs. At the same time, IT worries about access, finance questions licenses, and legal wants clear limits on data and ownership. Each concern is reasonable. Together, they leave a manager with mixed signals and no safe path.
Most managers fear a bad call more than a slow rollout. If they approve a tool too early and it creates a customer error, exposes internal data, or breaks a workflow, everyone remembers who said yes. If they delay for another month, the cost is real but less visible.
That fear changes behavior fast. Instead of changing how the team works, managers start collecting approvals. Meetings pile up. Small choices move upward. Staff keep doing the old work by hand because nobody has set clear authority or simple rules.
That is why good pilots often fade after the demo. The problem is not a lack of interest. The manager who owns the result usually does not own the decision. In many companies, one technical owner has to close that gap. Sometimes that person is internal. Sometimes it is a fractional CTO who can set boundaries, answer objections, and give managers enough cover to act.
How unclear authority slows the team
A pilot can go well and still lead nowhere. One team proves the tool works, saves time, and gets decent results. Then progress stops because nobody can say, plainly, who has the right to change daily work.
That gap sounds small, but it changes behavior fast. A manager may get approval to test an AI tool and still lack permission to rewrite the review process, adjust team targets, or update scorecards. The tool is there, but the old rules stay in place. People keep doing the old work because their manager still measures them the old way.
Budget creates the same kind of delay. The team may need a modest amount for training, licenses, or setup time. If that spending decision sits in another department, rollout can sit for weeks. By then, the energy from the pilot is gone.
Problems get worse when something breaks. If the tool gives a bad answer, who owns the fix? The team lead may blame IT. IT may say operations owns the process. Operations may point to compliance. Nobody feels safe making the call, so the issue stays open longer than it should.
You can usually spot unclear authority when teams keep asking the same questions: Who approves a new workflow? Who changes team metrics? Who pays for training and tool access? Who handles errors, risk, and audit questions? Who decides whether the pilot becomes standard practice?
When leaders leave those answers fuzzy, people learn a simple lesson: trying new things creates extra work and little reward. After that, they stop pushing. They wait for someone above them to decide, even when the next step is obvious.
Middle managers feel this most. They sit close enough to see what should change, but not high enough to force the change across reviews, budgets, and policy. An outside advisor or fractional CTO can help, not by picking tools first, but by giving each decision an owner, a budget path, and a rule for what happens when the tool makes a mistake.
What operating rules teams need
Teams run into trouble when one group uses AI for drafts, another uses it for decisions, and nobody can say where the line is. A working pilot hides that problem for a while. Day-to-day use exposes it quickly.
The fix is not a thick policy file. Most teams need a short rule set that answers a few plain questions.
Put clear limits on use
Start with the tasks people may hand to AI. Be specific. "Summarize meeting notes" is clear. "Handle customer issues" is not. Teams usually move faster when they name the safe jobs first: first drafts, summaries, ticket tagging, document cleanup, simple research, and code explanations.
Then define when a person must review the output before it goes anywhere else. Public replies, legal text, pricing changes, customer promises, security settings, and anything that changes data should never go out unchecked. If the model writes an internal draft, review can be lighter. If it affects a customer, money, or production systems, review should be mandatory.
Data rules need the same level of detail. Teams should know what may leave internal systems and what must stay inside. Customer records, contracts, source code, health data, payroll data, and private company plans usually need tighter limits. If a tool sends prompts to an outside model, people need to know that before they paste anything in.
Make the work traceable
Store prompts, outputs, and errors in one agreed place. It can be a shared folder, a ticket, a project space, or part of the normal workflow. What matters is consistency. When teams save the prompt, the answer, and a short note about what happened, they can spot bad patterns early instead of arguing from memory.
Bad answers need a written response, not just frustration. Tell people what to do: stop, mark the output as wrong, log the case, fix it manually, and flag it for review if the mistake could spread. If the model invents the same fact twice, that is no longer just a user problem. The team needs to change the prompt, the tool, the data source, or the approval step.
One page is often enough. If every manager can answer the same five questions the same way, teams stop guessing and start using AI as part of normal work.
A simple example from a support team
A support team tries a small AI tool that writes short summaries for incoming tickets. The support lead gives it to two agents first. Instead of reading a long message thread, they get a clear recap with the issue, past actions, and likely next step. Each agent saves 15 to 20 minutes a day. Response time improves a little, and the agents like it.
Then the pilot hits a wall.
QA still scores tickets with the old checklist. Reviewers expect the same manual notes, the same tags, and the same handling steps as before. So agents use the AI summary, then redo part of the work by hand to satisfy QA. The team saves time, but not enough to change the day.
The support manager sees the problem but cannot fix it. She does not control the scorecard, so she cannot tell QA what to measure. She also cannot buy more seats for the wider team without approval from another budget owner. The pilot works for two people, but it cannot spread to twenty.
Security makes it worse by staying vague. Nobody says which customer fields the tool may use. Can it read names? Order history? Payment notes? Because no one gives a clear rule, the team guesses. Some agents paste full tickets into the tool. Others strip out half the context first. The results vary, and nobody trusts the process.
On paper, the company is testing AI. In practice, the wider team sees no change. Most agents still work the old way, QA still checks the old way, and managers still wait for approvals from three different places.
A rollout only moves when someone makes a few plain decisions: QA updates the scorecard to match the new workflow, one manager gets authority to expand tool access, and security names the exact fields the tool can use. Until that happens, the pilot stays small. The team proves the tool can help, but the company never turns that small win into a normal way of working.
How to move from pilot to routine
A pilot proves that a tool can work. Routine starts when the team changes one real job, assigns one owner, and writes down a few rules people can follow without asking for permission every morning.
That is where many rollouts stall. Teams test a model, everyone likes the demo, then nobody decides how the work should happen on Tuesday at 10 a.m.
Start with one workflow that wastes time every day. Pick something small, repeated, and annoying, like turning sales call notes into CRM updates or sorting incoming leads. If the task happens ten times a week, that is enough to learn from.
Then name one manager who owns the rollout. Not a committee. Not "IT and operations together." One person should answer for adoption, errors, and whether the new process stays in place.
That manager needs clear authority to make three decisions on their own: which task the team must run through AI, when a human must review the output, and when the team should stop using the workflow and switch back to manual work.
Keep the first rule sheet short. One page usually beats a 20-page policy pack that nobody reads. It should say what tool the team uses, what data cannot go into it, where people report mistakes, and what "good enough" looks like.
Run it for 30 days. During that month, track a few plain numbers: time saved, error rate, and how often people bypass the process. Those workarounds matter. They usually show that the rule is clumsy, not that the staff is lazy.
After 30 days, adjust the rules and keep going. Maybe review only high-risk outputs. Maybe narrow the workflow. Maybe expand it to one more team. A fractional CTO or outside advisor can help set this up, but the day-to-day owner still needs to be inside the business. Without that, the pilot stays a demo.
Mistakes that keep rollout stuck
Most stalled rollouts fail for ordinary reasons. The pilot worked, people liked the demo, and then the company kept testing instead of deciding. Another pilot feels safe because nobody has to own the messy part: who can change a process, who signs off, and who answers for the result.
A common pattern is easy to recognize. Leaders ask for one more pilot in a new team even though the first team already proved the tool can work. A small workflow change goes through legal, IT, security, operations, and a department head before anyone can try it. Managers show polished outputs in meetings, but nobody tracks daily numbers like tickets closed, handoff time, or error rate. Teams treat every task as high risk, so a low-risk email draft gets the same review path as a customer refund.
That mix slows adoption more than model quality does. People stop using the tool because each small step feels heavy. After a month, the team says adoption is "mixed" when the real problem is process design.
Another mistake is quieter and more damaging. Companies tell managers to train staff, answer questions, and push the rollout, but they do not give those managers authority to change rules. A manager cannot improve much if they still need five approvals to edit a template, change a queue, or set a review threshold.
Risk should have levels. High-risk work needs tighter checks. Low-risk work should move fast. If every task goes through the same gate, safe work piles up and staff go back to the old way.
This is where operating rules matter. Teams need a named owner, a short approval path, and a few daily measures tied to real work. That means less time scoring demos and more time asking plain questions: Did response time drop? Did output hold up? Who can change the process this week?
A short check before you scale
Scaling too early creates a mess. One team uses AI every day, another avoids it, and managers keep asking the same approval questions. A lot of rollouts stall here because the pilot proved the tool works, but nobody fixed how work should change.
Before you push AI into more teams, check a few basics. A frontline manager should be able to approve a small workflow change today without waiting for three layers of sign-off. Staff should be able to explain approved AI use in one plain sentence. Everyone should know where the current rules live. Teams should track time saved, errors introduced, and rework created from the start. People also need a clear stop point so they know when to pause, ask for help, or hand the task back to a person.
This check sounds basic, but it saves weeks of confusion. If managers cannot make a small call, staff will work around them. If rules sit in five places, each team will invent its own version. That is how the same AI tool looks successful in one department and risky in another.
A good rule is easy to repeat. "Use AI to draft the first version, but a human approves anything sent to customers" is clear. "Use good judgment" is not. Teams need rules they can remember under pressure, not a policy document nobody reads.
Next steps for leaders
If a pilot went well but the team still hesitates, start smaller than you think. Pick one department where delays already cost real time or money, such as support, billing, or internal reporting. People move faster when the problem is obvious and the cost of waiting is easy to see.
Then give one manager written authority for the first rollout. Keep it simple. That person should have the right to choose the workflow, approve the first rules, assign reviewers, and stop the test if quality drops. When two or three managers share that job, nobody feels safe making the call.
A short weekly meeting helps more than a large steering group. Focus it on blocked decisions: what got stuck this week, which approval slowed the team down, what rule was missing, and what the manager should decide now. Those meetings should end with actual decisions, not notes for later. If the same issue appears twice, write a rule for it.
Keep the first rule set short. One page is often enough. Teams do not need a thick manual on day one. They need a few clear answers: when staff can use AI, what a human must review, where data can go, and who owns mistakes. After two or three weeks of real use, update the rules based on what the team actually ran into.
A support team is a good place to start. If agents use AI to draft replies, the first rules might say that AI can write the draft, a person must check refunds or policy exceptions, and the support manager tracks errors each Friday. That is enough to begin.
Some companies need outside help because no one in-house wants to set decision rights or work through edge cases. For that kind of hands-on setup, Oleg Sotnikov at oleg.is works as a fractional CTO and advisor for startups and small to medium businesses, helping teams define authority, operating rules, and practical AI rollout steps. The best next move is usually not a wider launch. It is a narrow one with a clear owner.
Frequently Asked Questions
What usually stalls after a successful AI pilot?
Most teams stall after the demo because nobody decides who can change real work. The tool may work, but meetings, approvals, scorecards, and review steps stay the same, so staff drift back to the old process.
Why do middle managers hold back even when the pilot worked?
Middle managers carry the risk but often lack the authority. If they approve a tool too early and something goes wrong, everyone remembers their name. If they wait, the delay hurts the company, but the blame stays softer and less direct.
What authority should one manager have during rollout?
Give one manager the right to pick the workflow, set the human review step, and stop the process if quality drops. That same person should also own adoption and error handling, so the team knows who makes the call.
What rules should a team write first?
Start with plain rules for allowed tasks, required review, data limits, and where people report mistakes. Keep it short enough that a manager can explain it in a minute and a team can follow it without asking for permission all day.
How long should the first rollout run?
Run the first real workflow for about 30 days. That gives the team enough time to hit normal problems, adjust the rules, and see whether people keep using the process once the pilot excitement fades.
What should we measure during the first rollout?
Track time saved, error rate, and how often people bypass the workflow. If staff keep working around the tool, the process probably feels clumsy or the rules still block normal work.
How should a team handle AI mistakes in daily work?
When the tool makes a bad call, stop that output from moving further, fix the work by hand, and log what happened. If the same mistake shows up again, change the prompt, the data source, or the review step instead of blaming the team.
Why doesn’t running more pilots solve the problem?
More pilots rarely fix a decision problem. If the first pilot already proved the tool can save time, the next step is not another demo. The next step is naming an owner, setting rules, and changing one real workflow.
How do we know a team is ready to scale AI use?
You are ready when a frontline manager can approve a small workflow change fast, staff can explain the rule in plain words, and everyone knows when to stop and hand the task back to a person. If those basics are still fuzzy, scaling will create confusion, not speed.
When should we bring in a fractional CTO or advisor?
Bring in outside help when teams keep arguing about ownership, approvals, or data limits and nobody inside wants to settle it. A fractional CTO can set decision rights, write simple operating rules, and give managers enough cover to move from pilot to routine.


