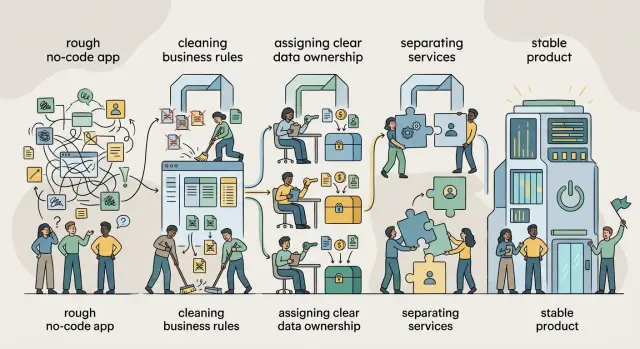
AI rollout for messy source data without costly rework
AI rollout for messy source data works better when you fix owners, names, and update timing first, so models stop pulling stale or mixed inputs.

Table of Contents
Why messy source data breaks AI work
AI does not clean up confusion for you. It repeats whatever sits in your forms, spreadsheets, CRM fields, and old exports. If the inputs clash, the output may look polished, but it still carries the same mistakes.
That is why so many AI projects stumble early. Teams expect more speed and better clarity. The model only sees patterns in the data it gets. If one team writes "customer start date" and another writes "go live date" for the same thing, the model treats them like different facts.
The problem grows when teams use the same label in different ways. Sales may call an account "active" after the contract is signed. Support may use "active" only after setup is done. Finance may tie it to the first invoice. Then someone asks the model for "active customers," and three departments give three different answers.
Old data creates quieter failures. Someone exports a CSV in March, saves it to a desktop, and reuses it in May because it is easy to find. That stale file ends up in a prompt, a dashboard note, or a weekly summary. The model then produces a clean update with old numbers, and the error spreads because people trust the format.
Once trust drops, every result turns into an argument. Teams stop asking, "What should we do next?" and start asking, "Which number is real?" That shift slows decisions and makes even simple automation feel risky.
Growing companies feel this fast. One person updates the CRM, another keeps a spreadsheet for renewals, and a third pulls billing data into a monthly report. A model can combine all of it in seconds. If the inputs disagree, that speed just spreads the mess faster.
Source data usually matters more than the prompt. Clear ownership, shared names, and update habits people actually follow solve more AI problems than prompt tweaking.
Map where the data really comes from
Most teams think they know where their data lives. Then they trace one workflow and find the same customer name in a CRM, a sales sheet, an intake form, two exports, and an inbox folder.
Start with one real workflow, not the whole company. Pick something people do every week, like handling new leads or updating order status. Then list every place that workflow touches, including files people keep on their own laptops.
For each field, write down four things:
- where the value first appears
- who enters it
- where it gets copied next
- who can change it later
This sounds basic, but it quickly shows the gap between the official process and the one people actually use.
Take a common example. A lead submits a website form. Sales copies the company name into the CRM, finance exports it into a billing sheet, and support edits the contact email in a shared spreadsheet after the first call. Now one customer has three versions of the same record. If you feed that into a model, the model will not sort it out. It will repeat the conflict.
Pay close attention to the first place each value is created. That source matters more than the cleanest-looking dashboard. If a phone number starts in a form, the form is the source. If product status starts in an internal sheet before it reaches the CRM, that sheet is the source, even if nobody likes saying it out loud.
Mark every handoff, copy, and export too. Manual re-entry creates errors. CSV exports go stale. Quick edits in chat or email often never make it back into the main record.
The fields that cause the most pain are usually the ones people edit in more than one place: address, deal stage, plan type, account owner, renewal date, and contact email.
When the map is done, you should be able to answer one simple question for every field: where does this value start, and where should people trust it after that? If you cannot answer that, stop there and fix the map first.
Decide who owns each field
Shared data falls apart when nobody owns it. If sales, support, and ops can all change the same field in different ways, the model sees three versions of the truth.
Pick one owner for every field that matters to a workflow. In a small company, that may be one person. In a larger company, it may be one team. The rule stays the same: one field, one final decision-maker.
A common mistake is giving ownership to "everyone involved." It sounds fair, but it creates drift. Names change, blank values stay blank, and nobody fixes the mess because everyone assumes someone else will.
Keep ownership rules simple. For each shared field, write down who owns it, who can edit it, who can only read it, and where the value comes from first. Put this in one short table. Do not bury it in a policy document nobody opens.
Take customer status as an example. Sales may suggest the status, support may view it, but only revenue operations should change the final value. If support spots a mistake, they should request the change instead of editing it directly. That removes silent conflicts.
Urgent fixes need a rule too. If a bad value can block an order, trigger the wrong email, or confuse an AI agent, give one backup owner permission to fix it. The main owner can review it later that day or the next morning. Fast enough, but still controlled.
Some fields do not survive this review, and that is fine. If nobody wants to own a field, ask why it exists. Old fields often stay in forms and exports long after the business stopped using them. They add noise and make cleanup harder than it needs to be.
Delete or archive fields that have no owner, no clear source, or no real use in decisions. Fewer fields usually lead to better output.
Fix names, labels, and duplicates
When teams feed the same idea into a model under different names, the output gets messy fast. One table says client, another says customer, a third says account, and nobody is sure whether those words mean the same thing.
Start with one plain name for each field. Pick the word people already use most often, keep it short, and use it everywhere. If sales says customer and finance says account, choose one and rename the field in every sheet, export, and form that feeds the workflow.
Make the field list boring
Boring names are good. They leave less room for guesswork. A field called start_date is clearer than something vague like activation, because different teams hear different things in that word.
Loose terms need short definitions. Keep them to one sentence. If qualified lead means a company that booked a demo, write that down. If active customer means they paid in the last 30 days, write that down too. Otherwise people label records by instinct, and the model learns the inconsistency.
Use one field name for one concept. Delete duplicate labels once you map them. Write a short definition for any term people argue about. Keep one format for dates, currency, and units.
Formats cause more damage than teams expect. If one system stores revenue as 12000, another as $12,000, and a third as 12k, cleanup scripts get harder and errors slip through. Dates are worse. Pick one format, such as YYYY-MM-DD, and stick to it. Do the same for units like kg versus lb, hours versus minutes, and net versus gross amounts.
Duplicates need human review before they need automation. Two records with slightly different company names may still be the same customer. A simple rule like same email domain plus same billing address catches many obvious cases. Edge cases need a person to decide once, then document the rule.
If a company spends two weeks standardizing names before building the workflow, it often saves months of rework later. Clean labels feel slow at first. They make every prompt, sync, and report easier after that.
Choose update cycles people can keep
A refresh schedule should match the job, not an ideal version of the company. If a team checks stock once a week, pushing that data into an AI tool every morning adds noise, not clarity. People start ignoring errors because the numbers never quite match reality.
Most update problems come from copying a reporting habit into an operating process. A finance report might run every Friday. A support team may need fresh ticket tags every two hours. Use the pace of the real task. If people act on the data weekly, update it weekly. If they act on it after every order, update it after every order.
Daily refreshes sound disciplined, but they often hide a mismatch. A supplier file that changes on Tuesday should not trigger daily prompts from Monday through Sunday. That only creates false urgency and extra cleanup.
Pick one shared cutoff time for anything that depends on the same data. Reports, dashboards, and AI prompts should all pull from the same snapshot. If the sales team closes updates by 5 p.m. on Thursday, the summary should run after that cutoff, not before lunch and not the next morning when someone has already changed a few fields by hand.
You also need a rule for late data. Decide in advance what happens when a file arrives late, a manager misses approval, or one system fails to sync. Do you skip the run, use last week's numbers, or flag the output as incomplete? People should not guess.
A modest schedule that people follow beats an ambitious one they ignore. If the source data changes every Wednesday and Friday, build around that rhythm and keep it simple.
Clean one workflow step by step
Start with one task that already wastes time. Pick something people repeat every week, such as moving leads from a form into a CRM, matching support tickets to customer records, or copying order data into invoices. If people already fix the same mistakes by hand, that task will expose the real problem quickly.
Do not clean every source at once. Freeze the exact inputs this task needs for the next two or three weeks. Make a small sheet that shows each field, where it comes from, who can change it, and how often it should update. That keeps the work from turning into a giant cleanup project with no finish line.
Then trim the inputs hard. Rename fields people cannot understand at a glance. "status2," "owner_new," and "client name final" are warning signs. Remove dead columns, merge duplicates, and pick one source for each field that matters.
A short checklist is enough:
- keep only the fields the task actually uses
- give each field one clear name
- set one owner for each field
- choose an update rhythm people can keep
- mark fields that can go stale
Ownership matters here. If nobody owns account status, the model will make decisions from old or conflicting values. If three people can edit the same field without rules, the workflow will drift within a week.
After that, test the workflow with current data and stale data. Use real records, not perfect sample rows. Try a lead with an old phone number, a company with two spellings, or a customer record that missed last week's update. You want to see where the workflow breaks before the team depends on it.
Keep notes while you test. Write down what failed, who fixed it, and where the fix belongs. Some fixes belong in the prompt. Many belong in the source table, the field names, or the update timing.
Here is a simple example. A growing company routes inbound leads with AI, but sales still rechecks half of them by hand. The team cuts the input from 42 columns to 11, renames five unclear labels, assigns one owner to each field, and sets a daily update for lead status. Rework drops because the model now reads the same facts the team trusts.
A simple example from a growing company
A 40-person software company built an AI summary for account reviews. Sales stored new leads and deal notes in the CRM. Support tracked renewals and churn risk in a shared sheet because that was faster for their team. Finance exported revenue once a month from the billing system, but the account names did not always match what sales or support used.
The mess stayed hidden until the summary pulled all three sources into one report. For one customer, the model paired last month's revenue export under "Blue River LLC" with this week's churn note under "BlueRiver." Sales read the summary and thought the account looked healthy. Support read the same summary and saw a likely cancellation. Finance could not match either name to the monthly report without manual cleanup.
The model was not the problem. The inputs disagreed.
The team fixed three small things before touching the prompt again. They chose one customer ID that every system had to carry. They gave each field one owner, so revenue came from finance and churn status came from support. They also set a weekly refresh for the merged dataset, because daily updates sounded good but nobody kept them current.
That changed the result fast. When the AI summary ran on Tuesday, it used the same customer ID across the CRM, the renewal sheet, and the finance export. Old revenue no longer sat next to fresh churn notes unless the dates matched. If finance had not posted the latest month yet, the summary showed the last approved revenue date instead of guessing.
The team cleaned a few account names too, but they did not spend weeks chasing every label problem in the company. They fixed the names tied to the workflow they cared about first. That was enough to stop the obvious contradictions.
After that, the next account summary stopped fighting with the monthly finance report. Sales, support, and finance saw the same customer story, even if each team still worked in a different tool. That is usually what this kind of rollout needs: less prompt tweaking and more agreement on what a field means and when it updates.
Mistakes that slow the rollout
These rollouts usually stall for ordinary reasons, not fancy technical ones. Teams move fast, wire a model into a process, and only then notice that the source data changes shape every week.
One common mistake is automating a broken handoff. If sales exports a spreadsheet, operations fixes half the rows by hand, and support adds missing notes later, the model inherits that mess. It can look like an AI problem, but the real problem is the handoff.
Another issue is letting several teams rename the same field. One system says "customer name," another says "account," and a third says "client." People may understand that these mean the same thing. A model often will not, especially when definitions shift from team to team.
Mixed dates cause quiet damage too. If finance sends last Friday's export, support sends this morning's file, and product pulls data once a month, the model gets three versions of reality. That is how you end up with summaries that look polished and still feel wrong.
Teams also lose time when they try to clean every system at once. It sounds thorough, but it spreads attention too thin. Pick one process, fix the fields it uses, set the update rhythm, and leave the rest for later.
Skipping a real user test is another expensive habit. Internal reviews miss basic problems because the people who built the process already know what the data should mean. Give the draft output to the people who use it every day and watch where they stop, question, or correct it.
A few warning signs show up early:
- people keep asking which file is the latest
- two teams use different labels for the same thing
- someone still fixes rows by hand before each run
- nobody can say who updates a field
- the first user test happens after launch
Most slow rollouts do not need better prompts. They need fewer guesses in the data.
Quick checks and next steps
A rollout is ready only when simple questions have simple answers. If nobody can tell you where an input comes from, who changes it, or how often it should update, the model will inherit the same confusion your team already fights by hand.
Before you expand anything, ask five plain questions:
- Can one person point to the source for every input the workflow uses?
- Does each shared field have one owner, even if several teams read it?
- Do names match across forms, sheets, and reports?
- Does the update timing match how people actually work?
- Have you tested one workflow from start to finish before copying the setup to other teams?
Any "no" matters. Fix that item first. Small gaps turn into expensive rework when prompts, automations, and reports all depend on the same messy field.
A clean test beats a wide rollout. Pick one workflow with a clear result, such as lead handoff, invoice checks, or support tagging. Clean the inputs, assign owners, set the update rhythm, and run it for a short trial with real work. If people stop asking which sheet is right, you are moving in the right direction.
You do not need perfect data across the whole company before you start. You do need one workflow where names are consistent, ownership is clear, and update cycles fit the way people actually work.
When the cleanup touches product decisions, data flows, and infrastructure at the same time, outside help can save a lot of back-and-forth. Oleg Sotnikov at oleg.is works as a Fractional CTO and startup advisor for companies making this shift, including the data and workflow cleanup that has to happen before AI automation starts paying off.
Pick one workflow tomorrow. List every input, name the source, assign one owner to each shared field, and set an update schedule people can keep. Then test it end to end before you expand.