AI pilot architecture: fix systems before better prompts
AI pilot architecture often decides whether automation helps or stalls. See how messy systems, weak states, and bad data stop useful results.
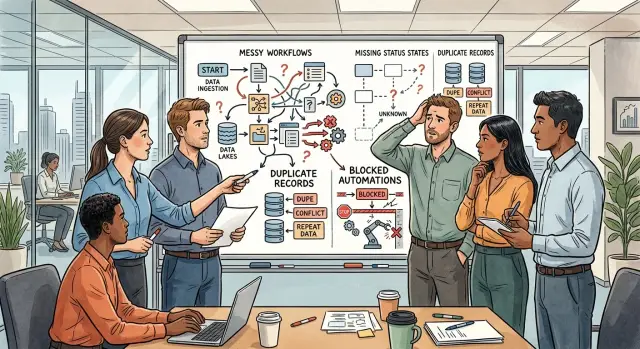
Table of Contents
Why the pilot stalls before prompts matter
A weak prompt can hurt an AI pilot. A messy workflow hurts it more.
If people do the same job in three different tools, skip important fields, and hand work off with no clear owner, the model has no stable path to follow. Teams often blame the model first because that is the part they can see. The answer looks vague, the summary misses context, or the task stops halfway through. But the model usually reflects the system around it. If the system is confused, the output will be confused too.
The pattern is usually simple. Customer notes live in chat, email, and a CRM. Nobody clearly owns the handoff from sales to delivery. Records miss fields like status, priority, or due date. One team uses labels that another team does not understand.
No prompt fixes that. You can ask for a better summary ten different ways, but the model still pulls from incomplete notes and mixed labels. You can ask for a smarter next step, but it still cannot tell whether the work is waiting, approved, blocked, or done.
A simple case makes this obvious. A team wants AI to draft follow-up emails after discovery calls. The drafts feel off, so they keep rewriting the prompt. Later they find the real problem: call notes sit in two places, the deal stage is often blank, and nobody records who promised what. The model did not fail on language. The process failed on structure.
This is the kind of issue that shows up early in AI pilot architecture. The work before automation is often dull, but it matters most: clean handoffs, clear states, and fields people actually fill in. Start there. Prompts come second. Once the workflow has a clear shape, the model usually improves fast, and the team stops guessing whether the problem is the AI or the way work moves through the business.
What messy systems look like in daily work
A messy system rarely looks dramatic. It looks normal from the inside. People still answer customers, move deals, approve work, and ship updates. They just spend a surprising amount of time patching gaps by hand.
One request can end up in four places before lunch. Someone gets it by email, mentions it in chat, adds a row in a sheet, and later creates a note in the CRM. Each tool holds a different version, so the team keeps asking the same question: which one is right?
That is where pilot design starts to matter. If an AI tool reads the CRM but the latest detail lives in chat, it gives a neat answer built on old information. The prompt may be fine. The system is not.
Duplicate records make the problem worse. A customer might appear once as "Acme Ltd," once as "Acme," and once under one employee's name. Sales sees one status, support sees another, and finance has a third record with a different email or billing contact. When automation touches that mess, it does not clean it up. It spreads the conflict faster.
Small teams usually notice the mess through daily friction. People copy the same update into several tools. Tasks end up with two owners, or none. Status changes live in chat instead of the main system. Someone checks an inbox every hour and forwards work by hand. Reports never match what the team believes happened.
Manual handoffs break automation chains in quiet ways. A lead comes in, but nothing happens until a manager reads the message and assigns it. A support issue gets tagged, but no one updates the customer record unless an operations person remembers. An approval sits still because the next step exists only in one person's head.
This is what messy workflows automation looks like in real life. The work still gets done, but only because people act as glue between disconnected tools. When the glue is human memory, any AI pilot hits a ceiling fast.
Where missing states break automation
A state is the current step of a task, order, ticket, or document. Labels like "new," "approved," "shipped," and "closed" tell both people and software what already happened and what can happen next.
Teams run into trouble when those labels are loose or incomplete. If one person marks a request as "done," another uses "resolved," and a third leaves it as "in progress," the system stops telling a clear story. An AI tool then has to guess whether the work ended, waits for review, or needs follow-up.
That guess usually goes wrong.
AI works best when it can read a clean sequence: the request came in, someone checked it, someone approved it, the team delivered it, and then the record closed. If the system skips a state, the model loses context. It cannot tell what happened before, and it cannot choose the next action with much confidence.
Bad labels create dead ends
Vague statuses cause two common problems. The AI sends the wrong output, or the automation stops because no rule matches the current record.
A few labels cause trouble again and again: "pending" without saying who must act, "done" when the item still needs billing or review, "on hold" with no reason or time limit, and "closed" even though the customer can reopen it.
Take a simple shipping flow. If an order moves from "approved" straight to "closed," the AI may send a delivery message before anyone packs the box. If the team adds "shipped" but forgets "returned," the system fails when a package comes back. If a support ticket goes from "new" to "closed" with no "waiting for customer" state, the AI may nag the team even though the ball is with the buyer.
Edge cases matter more than teams expect. Customers cancel after approval. A manager reopens a closed item. A payment fails after the invoice looked fine. Those are normal events, not rare exceptions.
This is where AI pilot architecture often breaks. The prompt can be smart, but the record still needs a real state map. If the map is missing, the AI fills gaps with guesses, and guesses do not scale.
How weak data models create bad output
Weak data models confuse people first, and AI second. If your team cannot tell what a record means, the model cannot infer it consistently.
A common mess looks small at first. One customer appears as "Acme Ltd" in the CRM, "ACME" in billing, and "Acme Logistics" in support tickets. A person on the team may know these are the same company. The AI tool does not know that unless the systems share a clear ID.
This is one of the most common reasons an AI pilot needs architecture work before prompt work. Teams spend time rewriting prompts when the real problem sits in the data layer.
Free text causes a lot of the damage. If a sales rep types "hot lead," another writes "follow up next month," and a third enters "probably dead," no tool can sort those records cleanly. The words overlap, contradict each other, or mean nothing outside one person's habits.
Structured fields fix that. Instead of a notes box for everything, use specific fields for stage, next action, renewal date, owner, and source. Then both humans and AI can work from the same facts.
Missing fields create another kind of bad output. If a record has no customer ID, no last updated date, no owner, and no source, the model fills gaps with weak guesses. That is how teams end up with duplicate follow-ups, wrong summaries, and tasks sent to the wrong person.
The usual trouble spots are simple:
- no shared ID across tools
- no clear date for status changes
- no named owner for the next step
- no source field that shows where the record came from
- too many open text boxes
Imagine an AI assistant that drafts account summaries for weekly reviews. It sees three names for one customer, two conflicting status notes, and no owner. The summary sounds polished, but it is still wrong. That is worse than a blank field because people trust it.
Good automation data model work matters before prompt tuning. Clean states, clear fields, and shared identifiers give the model something solid to work with. Without that, AI turns messy records into tidy-looking mistakes.
A simple example from a pilot
A small software company tried an AI helper for sales follow-up after demo calls. The task looked easy. One customer record came in with notes from the call, a pricing question, and a request to move the next meeting.
The AI did its part well. It read the notes, caught the tone, and drafted a solid reply: confirm the new meeting time, answer the pricing question, and mention the setup steps for the trial. If you only looked at the draft, you would think the pilot worked.
Then the handoff stopped.
The customer record had no clear state. Was this company still a new lead, already in trial, or already paying through a manual invoice? The CRM said "demo done." A shared spreadsheet said "trial sent." The support inbox had an older thread that called them a customer. The AI could write the email, but it could not choose the next action because the system did not say what stage the customer was actually in.
A second problem showed up fast. No owner was set on the record. Sales thought support should answer the setup part. Support thought sales should handle pricing. The AI had no rule for who approves or sends the final message, so the draft sat there until someone noticed it.
Duplicate data made it worse. One record said the customer needed 12 seats. Another said 20. The AI pulled both into the draft and produced a polite but confused answer. A human had to stop, compare notes, and ask the customer to repeat information they had already shared.
Three small gaps blocked the whole flow:
- the customer state was unclear
- nobody owned the next step
- the same account existed in more than one place
This is where architecture matters more than better prompts. The writing was fine. The system around the writing was not. In pilots like this, teams blame the model first. Most of the time, the model is not what broke the process.
Fix the foundation first
Most teams try prompts first because it feels fast. In practice, that order usually wastes time. If the workflow itself is fuzzy, the model only makes the confusion faster.
Start with one workflow, not the whole company. Pick a path that happens often and has a clear end, like "new lead arrives" to "proposal sent" or "support request opened" to "issue closed." Draw every step in plain language, even if it feels obvious.
For each step, write down four things: who owns it, what decision they make, what input they need, and what output they produce. This simple map exposes the real problem quickly. You may find that two people approve the same thing, one field gets copied by hand three times, or nobody knows what "ready" means.
After that, define the states. Keep them few and strict: new, reviewing, approved, blocked, done. Each state needs a clear meaning, and each move needs a rule. If a task can jump from new to done, or sit in "in progress" for weeks, AI cannot act confidently because the system itself has no clear logic.
Next, clean the fields that drive the workflow. Remove duplicate columns. Split mixed fields like "status/notes" into separate parts. Make dates, IDs, owners, and priority consistent. If the automation data model is messy, the AI will guess, and guesses get expensive fast.
Only then should you test AI. Give it one narrow job, such as classifying inbound requests, drafting a first reply, summarizing a handoff, or flagging missing information. Measure one result that matters, like cutting triage time from 12 minutes to 4 or reducing rework from bad handoffs.
That boring cleanup is usually the highest-return work in an early pilot. Better prompts help later. Clean states, clear transitions, and reliable fields help on day one.
Mistakes teams make early
Teams often start with the shiny part: a chat screen, a prompt library, a few polished replies. It looks like progress, but a demo is not a process. The first failure usually comes from the work behind the screen, not from the wording of the prompt.
Another common mistake is skipping the messy edge cases. People say the process is simple, then handle five awkward exceptions in email, chat, or memory. The model never sees those branches, so it gives smooth answers for the easy path and falls apart when a real case lands outside it.
The warning signs show up quickly. One status means different things to sales, support, and operations. Two people think the other person owns the next step. Records have blank fields, stale notes, or placeholder text. The team tests with clean examples instead of normal messy work.
Status names matter more than teams expect. If one person marks a case as "pending" and another uses "waiting," the AI has to guess whether those states match. If nobody owns the handoff after review, the model can produce a good answer and still leave the work stuck.
Data quality is another early trap. If you would not trust a record enough to approve a refund, send a quote, or close a contract yourself, do not ask AI to act on it with confidence. Bad records do not become better because a model reads them. They become faster mistakes.
Teams also judge the pilot the wrong way. They focus on whether the reply sounds smart. That matters, but it is only one part of the result. A useful test is whether the system chose the next action, updated the status correctly, sent the task to the right person, and reduced rework. A polished answer that lands in the wrong queue still wastes time.
A quick check before expanding the pilot
If the pilot only looks good in a demo, stop there. Expansion makes sense when the system can carry a real task from start to finish with little hand-holding.
Run a short review with the people who use the process every day. You do not need slides. You need clear answers.
Ask one teammate to explain the workflow in one place, such as a whiteboard or a single document. If they need five tabs open to make sense of it, the process is still split. Sample a few recent records. Each one should show who owns it now, what status it is in, and what happens next. If any of that is missing, the model will fill the gaps with guesses.
Compare status labels across the team. A label like "in review" must mean the same thing for sales, support, and ops. Trace a few fields back to the source. If nobody knows where "priority" or "customer type" came from, bad outputs will look random even when the prompt is fine.
Then make the pilot complete one real job. Draft text alone does not count. The system should move work forward, update the record, and send it to the right person.
A support workflow shows this fast. If the model writes a good reply draft but leaves the ticket status wrong, skips the owner, and fails to log the next action, the team still does the hard part by hand.
This is the unglamorous side of AI pilot architecture, but it decides whether automation helps or creates cleanup work. Clean states and traceable fields beat clever prompts almost every time.
This is also the kind of review an outside technical advisor often does before a team adds more agents or tools. Oleg Sotnikov at oleg.is works with founders and smaller teams on AI-first operations and Fractional CTO work, and this early workflow cleanup is usually where the real gains start.
If several checks fail, keep the pilot small. Fix the workflow, tighten the data model, and make one task reliable before you expand.
What to do next
Pick one workflow that happens often and creates real work for the team. The best first target has repeat volume, a clear owner, and a result you can measure. If a task shows up twice a month, leave it alone for now. If it lands on someone's desk 30 times a week, start there.
Before you buy another AI tool, clean up the workflow itself. Name the states in plain language. Decide which fields every record must have. Remove fields nobody trusts or nobody fills in the same way. A model cannot guess whether "approved" means budget cleared, legal signed off, or someone just moved the item forward.
Keep the first test short. Two to four weeks is usually enough. Set the rules before the pilot starts: what enters the pilot, what counts as a good output, when a human steps in, what failure looks like, and which metric decides whether you continue.
That last point matters more than most teams expect. A few good examples do not prove much. You want less rework, faster turnaround, fewer missed cases, or more consistent outputs. If none of that changes, better prompts will not save the pilot.
If your team keeps patching around the same mess with side spreadsheets, manual checks, and special-case rules, the problem is not prompt quality. It is the workflow, the state model, and the data underneath it. Those need a hard look before anyone expands the test.
Outside help can save weeks of wasted effort, especially when the team is too close to the process to see where it breaks. A practical Fractional CTO or advisor can review the workflow, tighten the data model, and break the rollout into small steps the team can actually manage. The point is simple: make one task reliable first. Then expand.
Frequently Asked Questions
How do I tell if the pilot has a prompt problem or a workflow problem?
Trace one real task from start to finish. If people switch between tools, leave fields blank, or argue about who owns the next step, fix the workflow first. Prompt changes help later, but they will not repair a broken handoff.
What should I fix first before I touch prompts?
Start with one common workflow and map it in plain language. Write down who owns each step, what input they need, what decision they make, and what output they produce. That usually shows the real gaps fast.
Why do missing or vague statuses break automation?
Automation needs a clear current state to choose the next action. If one person writes "done," another writes "resolved," and a third leaves the item open, the system starts guessing and work gets stuck or moves the wrong way.
Which fields matter most in an early AI pilot?
Keep the basics consistent: a shared ID, current state, owner, last update date, source, and next action. When those fields stay empty or drift across tools, the model fills gaps with guesses and the output loses trust fast.
Can AI still help if our data is messy?
Yes, but keep the job narrow and low risk at first. Use AI to draft, classify, or flag missing info while you clean records and merge duplicates. Do not let it run important actions on data your team does not trust.
How many workflow states should we use?
Use a small set of strict states that people actually follow. In many teams, four to six states work well because they stay clear without hiding edge cases. If a record can sit anywhere for weeks, the state model is too loose.
What makes a good first workflow for an AI pilot?
Pick a task that happens often, has one clear owner, and ends with a result you can measure. Good examples include new lead to proposal sent or support request opened to issue closed. Leave rare special cases for later.
Why do duplicate records cause so much trouble?
Duplicate records split the truth. One tool says one thing, another says something else, and the model may combine both into a polished but wrong answer. People then waste time checking which version to trust.
How should we measure an early AI pilot?
Measure business results, not just nice wording. Look for less rework, faster triage, fewer missed cases, cleaner handoffs, and correct routing to the right person. If the text sounds good but the task still stalls, the pilot is not working yet.
When should we expand the pilot or ask for outside help?
Expand only after the system can handle a real task from start to finish with little manual patching. Bring in outside help when your team keeps relying on side spreadsheets, chat memory, and one-off rules, because that usually means the workflow and data model need a hard cleanup first.


