AI-generated infrastructure changes need tighter approvals
AI-generated infrastructure changes can hit networks, databases, and secrets harder than app code. Set narrow approvals, small scopes, and quick checks.
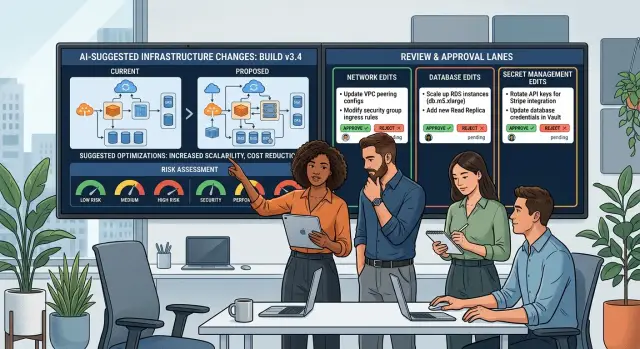
Table of Contents
What this problem looks like in real life
A team asks an AI tool to fix a small deployment issue. The diff is short, maybe ten lines. Nobody sees real danger because the change does not touch product screens or business logic. Then the team deploys it, and login fails, internal services stop talking to each other, or a background worker loses access to the database.
That is blast radius in plain words: how far a bad change spreads after it lands. A bug with a small blast radius annoys one group of users or breaks one page. A bug with a large blast radius can take down sign in, payments, admin tools, scheduled jobs, and support workflows at the same time.
This gets riskier with AI generated infrastructure changes because the output often looks neat and certain. The tool can change a firewall rule, a load balancer setting, a secret name, or a database permission in seconds. The patch looks harmless. The effect hits everyone.
A broken feature and a broken network rule do not fail in the same way. If a new search filter has a bug, people can usually still browse, buy, and contact support. If one network rule blocks traffic between services, the whole app can feel dead even when the code itself is fine.
The same pattern shows up with data and secrets. One wrong database edit can lock writes, break a migration path, or expose records to the wrong service. One secret edit can cut off email delivery, payments, storage access, or your AI pipeline if shared credentials stop working.
A simple comparison helps:
- A broken feature usually hurts one workflow.
- A bad infrastructure rule can hurt many workflows at once.
- A bad UI deploy is often easy to spot and roll back.
- A bad secret or database change can fail quietly, then spread.
Growing teams hit this early because they move fast and trust automation more each month. That trust is often earned. AI saves time on routine changes. But speed changes the risk math. When a tool edits app code, the damage is often local. When it edits networks, databases, permissions, or secrets, one fast mistake can become an outage across the company.
That is why these changes need tighter review than normal code. The diff length does not matter much. What matters is how many systems depend on it.
Why infrastructure edits need stricter approval
Most application code has a smaller failure zone. A bug in a checkout screen, a report filter, or a new admin page usually stays inside that feature. It still hurts users, but the damage often has edges.
Infrastructure changes do not behave that way. One edit to a network rule, load balancer, DNS record, secret, or database setting can hit every user at once. That is why AI generated infrastructure changes need tighter review than normal code changes.
The gap is easy to see. If an AI tool suggests a bad UI change, one page may look wrong. If it suggests a bad firewall rule, health check path, or ingress policy, traffic can stop for the whole product. The same goes for storage, queues, and service discovery. Shared systems create shared failure.
Database edits need even more care. A migration can look harmless in a diff and still lock a busy table, drop data, or make old code and new code disagree about what a record should look like. AI can write valid SQL and still miss the timing, order, or rollback plan. Production databases punish small mistakes fast.
Secret changes are another common trap. Rotating an API token, changing an environment variable, or moving credentials to a new store can break logins, payment calls, background jobs, and internal services in one deploy. Teams often notice only after sessions expire or retries pile up.
Why normal approval is not enough
A normal code review asks, "Does this work?" Infrastructure change control has to ask different questions: "Who else does this touch?" "Can we roll it back in minutes?" "What happens if the AI guessed wrong?"
That is why approval lanes should be narrower for network, database, and secret edits. Fewer people should approve them, but those people should know the system well. Broad approval from general reviewers often misses the real risk because the diff looks small while the blast radius is huge.
Teams that move fast with AI need stricter blast radius approvals, not looser ones. Caution is not bureaucracy here. It is basic safety.
Which changes need narrow approval lanes
Most application code can move through a normal pull request flow. Infrastructure edits need a smaller lane with fewer people allowed to approve them and clearer ownership. One wrong line in a policy file can cut off traffic, expose data, or break deploys for every service at once.
The test is simple: if a change can affect many systems, customer data, or account access, do not treat it like a routine code edit. Give it tighter approval, a slower rollout, and a reviewer who owns that area.
Put these changes in the strict lane
Start with network rules. Firewall edits, security group changes, ingress and egress rules, VPC routing, VPN settings, DNS records for production traffic, and service mesh policy updates can all change who talks to what. A small mistake can block payments, expose an internal admin panel, or break calls between services.
Database changes belong in the same lane. That includes schema migrations, index drops, table renames, retention policy changes, replication settings, backup rules, and any change to database roles or access grants. AI can write a migration that looks fine in a diff and still lock a hot table or remove data a job needs an hour later.
Secrets sit in this group too. Creating a secret, rotating one, changing where it is stored, widening who can read it, or changing how it reaches runtime should never pass on a casual review. Secret edits often look tiny. Their blast radius is not.
Identity and permission changes fit here as well. IAM roles, cloud account permissions, deploy tokens, CI runner permissions, and production admin access all deserve named reviewers. If approval rights are broad, mistakes spread fast.
What can stay in the normal lane
Not every config edit needs the strict path. A copy change, a non production log setting, a dashboard label, or a feature flag for one service usually does not need the same gate. The line is not whether a file sits in an infrastructure folder. The line is impact.
A simple split works for most teams. Keep one lane for changes that affect one service, one environment, or developer convenience. Use a strict lane for changes that affect shared network paths, shared data stores, secrets, access, backups, or production recovery. Keep a separate emergency lane for urgent fixes, but require a short follow up review once the fire is out.
Teams that use AI every day often learn this the hard way. The tool writes fast and sounds sure of itself. Approval rules need to care about blast radius, not writing speed.
How to set the rules step by step
Start with scope. A change rule only works if people can tell, in a few seconds, how much damage a bad edit could cause.
Most teams already review application code one way and production access another way. Infrastructure needs the same split, especially when AI generated changes can touch networks, databases, secrets, and deploy paths in one pull request.
Build the approval lanes
Sort changes by what they touch, not by who wrote them. A Terraform edit that changes tags or non production logging is not the same as a change to VPC routes, firewall rules, database roles, or secret rotation. Put each area into a small risk bucket so reviewers know the lane right away.
Keep the review group as small as possible. If a change touches database permissions, send it to the database owner and one backup reviewer. If it changes secrets, send it to the person who owns secret storage and rotation. Broad review groups slow teams down and often miss the real risk because everyone assumes someone else checked closely.
Named ownership matters. Every risky area needs a person, not a team alias, in the approval policy. If nobody owns production networking, nobody will catch an AI tool opening a port that looked harmless in the diff but changed real exposure.
Limit each request to one risky area at a time. Do not let a single pull request update security groups, database grants, and secret values together. Smaller requests make reviews faster. They also make rollbacks much safer.
Before anyone approves, require written rollback steps. Keep them short and plain:
- State what will change.
- State how to undo it.
- State how to verify the rollback worked.
- Name the person who will execute it if things go wrong.
Make the rule usable
Teams skip rules that feel heavy. Keep the decision simple with a short template in every risky change request: touched area, owner, second reviewer, rollback plan, and deployment window.
A growing team can start with three approval lanes: normal app code, risky infrastructure, and emergency fixes. That is enough for most startups. A database permission change should not wait in the same queue as a UI text update.
One practical example: an AI assistant proposes a change that updates Kubernetes manifests and also rotates a production API secret. Split that into two requests. Let the platform owner review the manifest change. Let the secret owner review the rotation plan, the storage location, and the rollback note. Two smaller approvals usually take less time than one large, messy review, and they cut the blast radius if the tool got part of the change wrong.
With lean teams, the pattern that holds up best is boring in a good way: clear ownership, narrow lanes, small requests, and a rollback note written before approval, not after trouble starts.
A simple example from a growing team
A small SaaS team ships fast. They have six engineers, one product manager, and an AI coding assistant that helps with pull requests, tests, and small refactors. On a normal week, that setup saves them hours.
One Friday, the team adds a new customer reporting page. The AI suggests two changes in the same pull request. First, it updates the API code so the page can load report data. Second, it changes the database access layer so the reporting service can read from a billing table it could not touch before.
At first glance, the pull request looks tidy. The app code is clear, tests pass, and the feature works in staging. That is where teams get into trouble with AI generated infrastructure changes. One diff can mix a safe UI or API edit with a much riskier permission change.
This team does not treat both edits the same way.
The API code goes through the normal review path. Two engineers check the logic, run tests, and approve it. That part has a limited blast radius. If the code has a bug, the team can roll it back quickly.
The database access change takes a different path. Their rules say any edit that changes network rules, database permissions, secret access, or production roles needs a narrower approval lane. The backend reviewer checks the query scope. The infrastructure owner checks the permission change. One person outside the feature team confirms the service gets only the access it needs.
That extra step catches the real problem. The AI had granted the reporting service broad read access to the whole billing schema, not just the data needed for the new page. It also suggested reusing an existing production secret instead of issuing a separate one.
The team fixes both parts before merge. They create a view that exposes only the required columns. They issue a new secret with a tighter scope and a short rotation window. The app code stays almost the same, but the risk drops a lot.
Without that tighter path, the feature would likely have shipped with wider access than anyone intended. A later bug, a leaked token, or one bad query could have exposed billing data or slowed the database for everyone.
The team still moves quickly. They just accept that code review and access review are different jobs. That one rule stops a small feature from turning into a full outage.
Mistakes teams make when they trust the tool too much
The usual failure is not that the model writes bad code every time. It is that people start treating AI generated infrastructure changes like normal pull requests, even when one small edit can lock out users, break deploys, or expose data.
A frequent mistake is batching unrelated edits together. One change set might include an app fix, a security group update, a database migration, and a secret rotation. That saves review time on paper, but it ruins judgment. Reviewers skim. They approve the harmless app change and miss the network rule that opens too much access. When infrastructure has a wide blast radius, each risky change needs its own lane and its own reviewer.
Secrets are another place where teams get careless fast. If an AI tool can update tokens, API keys, or database credentials without a named human owner, nobody is fully accountable when something goes wrong. Someone must own every secret change, confirm where the new value came from, and check who or what depends on it.
Urgent fixes cause a different kind of damage. Teams rush a production patch, skip rollback notes, and tell themselves they will document it later. Later rarely comes. Then the patch fails under load, and nobody remembers the old setting, the previous image tag, or the order needed to undo the change. A rollback plan does not need to be long. It just needs to exist before deploy.
Another bad habit is giving the same small group blanket approval for everything. That creates blind spots. The person who knows app logic may not spot a risky IAM edit. The person who understands infrastructure may miss a migration that can lock tables. Split approvals by area. It feels slower for a minute. It is much faster than cleaning up an outage.
Staging also gets more trust than it deserves. A change can pass every test there and still fail in production because traffic shape, data size, timeouts, permissions, and third party limits are different. A database migration that looks clean on a small copy can drag for minutes on a live table. A secret change can work in staging because fewer services use it.
When teams see warning signs, they should pause before merge. Watch for a pull request that mixes app, network, database, and secret edits, or a change with no named owner for the credential update. Stop if the rollback note is missing or too vague to run under stress. Stop if the same approvers sign off on every type of change. And stop if staging passed but nobody checked the production specific risks.
That pause feels annoying. Restoring access at 2 a.m. feels worse.
Quick checks before you merge or deploy
A small infrastructure diff can change far more than it seems. One AI suggestion might touch a firewall rule, a database role, and a secret name in the same commit. That is enough to break logins, block traffic, or expose data if nobody slows down and checks the exact change.
Before you approve anything, map the blast radius in plain language. Do not ask, "Does this look reasonable?" Ask, "What systems will feel this in the next 10 minutes?" If the answer includes production network paths, customer data, auth, backups, or secrets, treat it with tighter approval than normal app code.
A short check before merge works well:
- Name every system this edit can touch, including side effects.
- Confirm the owner for each system.
- Test the change in a smaller scope first.
- Make rollback fast and boring.
- Read the exact diff, not just the AI summary.
A simple example shows why this matters. An assistant proposes a "cleanup" commit that removes an old secret, updates a Kubernetes manifest, and tightens a database permission. The summary sounds harmless. The diff shows that one service still reads the old secret name during startup, and a reporting job still needs the permission that got removed. If the team checks only the summary, they merge a failure.
Smaller tests catch this early. Deploy the manifest to staging, rotate the secret for one service, and run the reporting job against a copy or limited environment. That takes a bit longer, but it is much cheaper than a production outage at 4 p.m.
Ownership matters just as much as testing. AI generated infrastructure changes often cross team lines, and shared systems fail in messy ways. A narrow review lane keeps the right people involved, and that usually saves time instead of wasting it.
What to do next
Start small and pick the changes that can hurt you fastest. For most teams, that means network rules, database schema or permission edits, and anything that touches secrets. Those are the places where AI generated infrastructure changes can go from helpful to expensive in one merge.
Do not redesign your whole process at once. Write a short rule set that fits your team size and release pace. A team of four does not need the same approval path as a company with separate platform, security, and data owners. Keep the rules plain: who can propose the change, who must review it, and what proof they need before deploy.
A good first pass is simple. Put network, database, and secret edits in a separate approval lane. Require a reviewer who owns that area, not just any engineer on rotation. Ask for a short note on impact, rollback, and affected systems. Block automatic merge for these files, even if normal application code can merge automatically. Log every exception so the team can review it later.
Then look backward before you look forward. Pull a sample of recent infrastructure pull requests and sort them by risk. You will usually find that small looking edits had a larger blast radius than expected: an open port, a secret rename that broke deploys, or a database change that looked safe but locked a table at the wrong time. That quick review gives you real examples, which makes your approval rules easier to defend.
Keep the process alive. Once a month is enough for most teams. Review incidents, near misses, rollback events, and changes that took longer than expected. If a rule creates friction with no safety benefit, cut it. If one class of change keeps causing trouble, tighten it.
This does not need to slow normal work. Most application code can still move fast. You are only putting narrower approvals around the edits that can take down environments, expose data, or break access.
If your team needs outside help setting those lanes, Oleg Sotnikov at oleg.is works with startups and small companies as a fractional CTO and advisor. He helps teams tighten AI assisted engineering, infrastructure review, and approval rules without turning every deploy into a meeting.
Frequently Asked Questions
What does blast radius mean here?
Blast radius means how far a bad change spreads after you deploy it. A small bug might break one page, while one bad network rule or secret change can break login, jobs, payments, and internal traffic at the same time.
Why are AI-generated infrastructure edits riskier than normal app code?
AI often produces neat, confident diffs, so teams treat them as low risk. That is dangerous with infrastructure because one short edit can change access, routing, or credentials for many systems at once.
Which changes need the strict approval lane?
Put shared network rules, database schema or permission edits, secret changes, IAM updates, backup settings, and production recovery settings in the strict lane. If one change can affect many services, customer data, or account access, do not treat it like routine code.
Who should approve risky infrastructure changes?
Let the person who owns that area review it, plus one backup reviewer who understands the same system. A general code reviewer may catch app bugs, but they often miss risky database, secret, or network changes.
Should we mix app code and infrastructure edits in one pull request?
No. Split them up. If one pull request mixes app code with a database grant or secret rotation, reviewers skim and miss the dangerous part. Smaller requests make review faster and rollback much safer.
What should a rollback note include?
Keep it short and specific. Say what will change, how you will undo it, how you will verify the rollback, and who will run it if the deploy goes wrong. Write that before approval, not during the outage.
Is staging enough before we deploy infrastructure changes?
Not by itself. Staging catches obvious issues, but production has different traffic, data size, timeouts, and dependencies. Test risky changes in a smaller scope first, then check the production-only risks before you deploy.
What warning signs should make us stop a merge?
Pause when a pull request touches app code, network rules, database edits, and secrets together. Also stop if nobody owns the change, the rollback note feels vague, or reviewers only read the AI summary instead of the actual diff.
How can a small team add these rules without slowing everything down?
Start with three lanes: normal app code, risky infrastructure, and emergency fixes. Put only network, database, secret, and access changes behind the stricter path. Most code can still move fast, so you add safety where the damage can spread wide.
When should we ask an outside CTO or advisor to set this up?
Bring in outside help when your team keeps mixing risky edits, ships without rollback notes, or argues about who owns production systems. An experienced fractional CTO can set approval lanes, assign ownership, and tighten AI-assisted workflows without turning every deploy into a meeting.


