AI adoption cost review: where new bills show up
AI adoption cost review should track retries, storage, reviewer time, and support work so teams see where spending moved after rollout.
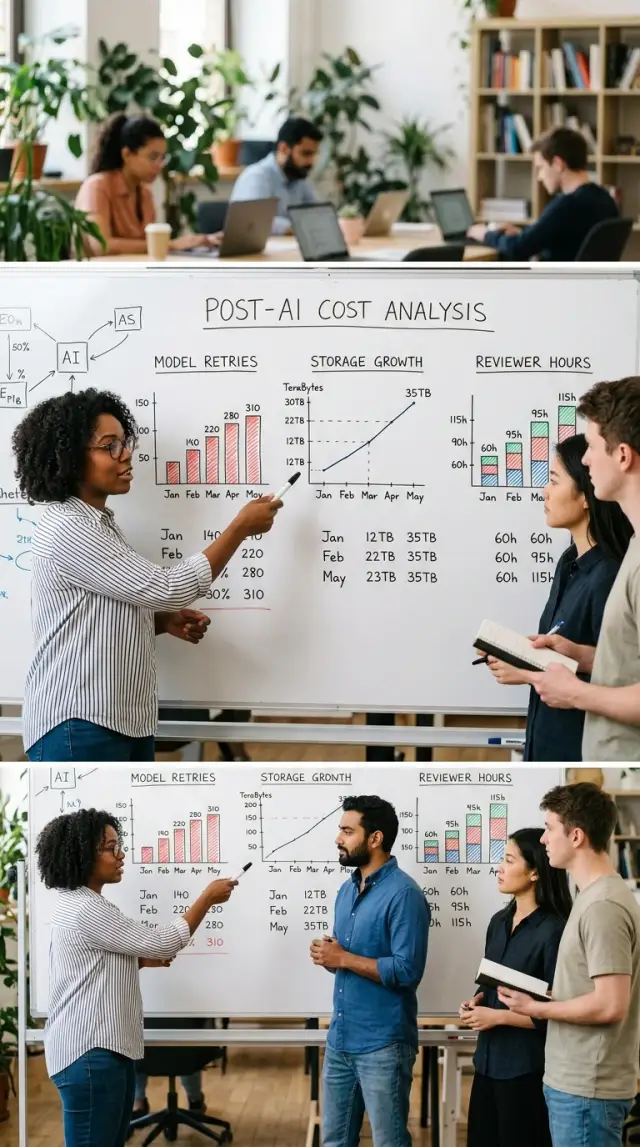
Table of Contents
Why AI savings can look wrong at first
The first numbers often tell the wrong story.
A team adds AI, a few repetitive tasks take less time, and payroll pressure eases. That feels like a clear win. But payroll is only one line on the bill.
Most AI work does not erase cost. It shifts cost. Instead of paying only for employee or contractor hours, you start paying for model calls, failed runs, storage, monitoring, review time, and cleanup when output is close but still not ready.
That is why the first month or two can look confusing. One column drops fast. Several smaller columns rise more slowly. If nobody groups those new costs together, the savings look larger than they are.
A small team can feel this almost at once. Say a product team uses AI to draft support replies, write test cases, and summarize customer notes. They might save 30 hours of manual work in a month. At the same time, they start paying for repeated model runs, larger logs and file storage, staff review before anything goes out, and extra engineering work to fix edge cases.
None of those costs looks dramatic on its own. Together, they can eat a big part of the labor savings.
Timing makes this even harder to spot. Payroll changes appear quickly if a team reduces contractor hours or slows hiring. New AI costs often show up later, after usage grows. Storage bills rise as teams keep prompts, results, screenshots, and audit trails. Review time rises when more departments start using the same workflow. Small charges stack up quietly.
That does not mean the rollout failed. It usually means the accounting view is too narrow. The spend did not vanish. It spread across tools, infrastructure, and human review.
Teams that see this early make better decisions. They stop asking only, "Did payroll go down?" and start asking, "Where did the work go, and what now costs money that did not cost money before?" That question gives a much cleaner picture.
Where the money goes instead
Payroll changes are the most visible part of the budget, so teams notice them first. A better review starts with the smaller charges growing in the background.
Model calls are the first place to look. One prompt can seem cheap, but the real workflow often adds retries, longer context, fallback models, and developer test runs. A single customer request can trigger five or ten calls if the first answer fails a rule, times out, or needs a second pass.
Storage also grows faster than many teams expect. You may save source files, prompts, outputs, logs, screenshots, embeddings, and backups for each run. If the team keeps everything for debugging, audits, or support, storage turns into a steady monthly bill instead of a one-time setup cost.
People costs move rather than disappear. Someone still reviews odd answers, fixes broken formatting, handles exceptions, and deals with support tickets after a bad result. Those reviewer hours are easy to miss because they sit across product, support, and operations instead of one obvious budget line.
The support layer adds another set of costs. Once AI touches customer-facing work, teams often add error tracking, usage dashboards, alerting, content filters, and access controls. Those tools make sense. They still belong in the AI operations budget.
Picture a startup that automates first-draft support replies and saves 30 staff hours a week. Then it notices higher model bills from retries, bigger storage bills from saved conversations, and a part-time reviewer checking risky replies. The team still comes out ahead, but the savings land in a different place than the first spreadsheet suggested.
Build a simple cost map
Most teams start with the AI invoice. That misses a lot, because the money usually follows a workflow, not a single tool.
Start with the jobs your team already does with AI. Keep it plain: support drafts, sales call summaries, document search, code review help. Give each workflow its own line. If you mix them together under one vendor bill, you lose the story fast.
A simple spreadsheet is enough. One row per workflow usually works better than one row per service.
For each workflow, write down what starts it, who touches it before it ends, which paid services sit behind it, how often it runs, and what counts as a finished result.
The handoffs matter more than people expect. List every step from start to finish: the person asking for the output, the app sending the request, the model producing the answer, any storage layer, and the person checking or fixing the result. If someone spends even 10 minutes a day cleaning up bad outputs, that belongs on the map.
Paid services also hide in quiet places. The model API is obvious. The storage bill, logging bill, transcription bill, queue, monitoring tool, and cloud jobs are easy to ignore because they sit on different invoices. They still belong to the same workflow.
Take a simple example. A team uses AI to summarize customer calls. One workflow includes call recording storage, speech-to-text, the model prompt, temporary storage for the summary, and a support lead who checks the final note before it goes into the CRM. That is five costs for one workflow. If you split them by vendor, the feature looks cheaper than it is.
Group by workflow, not invoice
Vendor invoices tell you who charged you. They do not tell you whether the work paid off.
Put related costs on one line, even if they come from different systems. If one workflow uses a model provider, cloud storage, and a reviewer, group them together. That gives you a cost per useful output, which is the number you can act on.
This kind of map also makes later reviews much easier. When a bill jumps, you can ask a direct question: which workflow grew, and why? That is much more useful than staring at a longer invoice from one vendor.
Track retries and failed runs
A run that fails once and succeeds on the second try still costs two runs. Teams often report only completed tasks, then wonder why the bill climbed. Retry volume usually explains the gap faster than payroll numbers do.
Count retries per task, not just total API calls. A support draft, invoice parser, or code review bot can look cheap when you sample one clean success. The real cost shows up when the same task needs three attempts because the first answer timed out, hit a rate limit, or missed the format your app expected.
Separate user retries from system retries. User retries usually mean the output was weak, vague, or off target. System retries point to app problems such as bad timeout settings, brittle parsing, or queues that fire the same job again after an unclear error. If you mix both into one number, you lose the reason behind the spend.
Long prompts deserve their own check. A task that retries with a 9,000-token prompt burns money much faster than a short request. This happens a lot when apps keep appending full chat history, old instructions, or repeated context on every attempt.
Failed jobs can also trigger work outside the model bill. A failed extraction job may run again, write another file, and send a reviewer back to fix the output by hand. One bad loop can raise compute, storage, and labor costs at the same time.
A simple task log goes a long way. Track the task ID, number of attempts, who triggered the retry, prompt size or token count, and the failure reason.
A small team can spot useful patterns in a month. If 12% of runs retry and most come from one workflow, fix that workflow first. Teams often save more by cutting failed runs than by chasing a cheaper model, because they stop paying for work that should not repeat at all.
Watch storage growth and data movement
Storage costs creep up quietly. AI workflows create more than final answers. They also create raw uploads, intermediate files, logs, embeddings, cached results, screenshots, backups, and copies moving between tools. This often explains why the bill keeps rising even when payroll drops.
Start with a monthly snapshot. Count the total size of raw files first, then track how much each related bucket grows after every new workflow. A team may upload 50 GB of source files in a month, then end up storing 200 GB after OCR output, chunked text, embeddings, logs, and backups pile on top.
A useful storage review checks five things: raw files and user uploads, logs and error dumps, embeddings or vector indexes, caches and generated files, and backups or archived copies.
Retention matters as much as growth. Many teams keep every output forever because deletion feels risky. That gets expensive fast. If a process retries three times and stores each result, you may end up paying to keep failed output that nobody will ever open again.
Data movement adds another bill. When one tool sends files to another, you may pay transfer fees, API charges, or both. Duplicate copies pile up too. One dataset can sit in app storage, a processing queue, a vector database, an analytics export, and a backup set at the same time.
Here is a common pattern. A support team uploads call recordings, transcribes them, stores transcripts for search, pushes chunks into an embedding store, then backs up the whole pipeline every night. The original 20 GB can turn into 60 GB or more without anyone noticing.
Review a few questions every month. Which files expire automatically? Which copies exist only because two tools sync the same data? Do backups include caches you can rebuild? Are jobs moving data across regions or vendors?
When storage growth stays on the same sheet as model and labor costs, surprise bills are much easier to catch.
Count reviewer hours and cleanup work
After automation starts, teams often focus on lower writing time and miss the larger picture. If people spend time checking drafts, fixing errors, and handling odd cases the AI could not solve, that time still costs money.
Start with minutes, not opinions. Ask each reviewer to log how long they spend on an AI-generated output from first read to final approval. Keep it simple. A shared sheet with task type, review time, cleanup time, and final status is enough.
Small edits matter. If a marketer spends 3 minutes checking a product summary, that is one thing. If they spend 12 minutes rewriting half of it because the tone is wrong or facts are off, that is rework. Rework belongs in your cost total just as much as model usage.
Edge cases need their own line. Teams often ignore the extra time spent answering unusual customer questions, fixing messy formatting, or correcting drafts that sound fine but miss an important detail. Those cases may be rare, but they eat hours fast.
A short review log should capture review minutes per task, cleanup or rewrite minutes, rejected outputs, edge cases handled by a person, and the manual time for the same task sampled once or twice each month.
That last comparison matters a lot. You need a clean view of assisted work versus fully manual work. If a task took 18 minutes before AI and now takes 11 minutes including review, you saved 7 minutes. If it now takes 20 minutes because staff keep fixing weak drafts, you added cost even if output volume went up.
Use real examples, not averages alone. A startup may see AI write first-pass support replies in seconds, while an operations lead still spends 90 minutes a day checking sensitive cases. That review time is part of the workflow, not an exception.
Good review data also tells you what to fix. You may need a better prompt, a tighter template, or a rule that sends certain requests straight to a person. When reviewer hours fall, the savings become real.
Run a monthly review
Monthly reviews work better when the scope stays small. Pick one workflow, such as support reply drafts or invoice parsing, and review one full month instead of trying to measure everything at once.
A narrow slice gives cleaner numbers. You can usually spot waste faster when you compare one workflow today with the same job before AI entered the process.
Use one sheet and fill it with the same categories every month: payroll time for everyone touching the workflow, including review and cleanup; tool invoices for models, APIs, and automation services; storage, database, and data transfer costs tied to the workflow; support costs from failed runs or bad output; and the old manual cost beside the new cost.
This works best when you use real inputs, not guesses. Pull invoices from finance, usage logs from your AI tools, and time estimates from the people doing the work. If someone spent 6 hours fixing messy outputs, count those 6 hours. Hidden labor is still labor.
Then compare the new workflow with the old manual process in plain terms. If the manual version cost $4,200 a month and the AI version costs $3,900, that looks good at first. But if storage doubled, retries keep climbing, and one reviewer spends 18 hours a month cleaning results, the savings are thin and may disappear next quarter.
After that, make a clear call on each cost line. Keep the parts that save time without extra cleanup. Trim anything that adds a little convenience but steady cost. Redesign the workflow if one weak step creates repeat model calls, bad outputs, or too much review.
A good monthly review ends with two or three actions, not a long report. If you cannot name the next fix, the review was too broad.
A simple example from a small team
Take a support team with eight agents and one manager. They add AI to draft replies for common questions such as refunds, password resets, and order updates. On paper, the change looks great in the first month. Each agent handles more tickets per day, and reply time drops.
The surprise shows up on harder tickets. When a customer writes a long complaint, mixes several issues in one message, or asks for an exception, the first draft often misses the point. The team runs the prompt again, edits the input, or switches to a second model. A ticket that used to take one human pass now burns through three or four model calls before anyone sends a reply.
The manager's time changes too. Before AI, they checked a small sample of replies. After AI, they review many more risky ones: refunds, angry customers, and anything with legal or billing language. That can easily turn into 8 to 10 extra hours each week. Payroll did not drop much. It moved.
Storage creeps up too. The team keeps prompts, drafts, final replies, and full transcripts so they can audit mistakes and improve prompts later. At first this feels cheap. Six months later, the archive is much larger than expected, especially if they also store attachments and every draft version.
A monthly snapshot might show 20% faster agent handling time, 35% more model calls than planned because of retries, 10 manager hours a week spent on review, and three times more stored conversation data.
That is why a real cost review needs more than a payroll line. This team did save time, but the new bills landed in model usage, oversight, and storage. If they looked only at agent speed, they would call the rollout cheaper than it really was.
Mistakes that hide real costs
The model invoice gets attention first because it is new, easy to export, and easy to blame. It is often only one part of the bill. A serious review has to look at the work around the model, not just the model itself.
One common mistake is treating token price as the whole budget. If a workflow calls the model three times, retries twice, stores every output, and then sends a person to fix the result, the model fee is only one line in a much longer chain. Cheap prompts can still create expensive operations.
Staff time gets missed for a simple reason: payroll already exists. But salary cost does not disappear just because nobody made a new purchase order. If support staff spend 30 minutes a day fixing AI-generated replies, or a product manager checks every summary before it goes out, that time belongs in the AI budget.
Managers often miss their own work. They approve prompts, calm unhappy customers, answer edge-case questions, and decide when a bad output needs a manual redo. None of that shows up on the vendor dashboard, yet it still costs money.
Storage is another quiet leak. Teams keep every prompt, output, screenshot, trace, and debug log because it feels safer. After a few months, that habit can raise cloud storage, backup, and data transfer bills more than expected. Old logs also make searches slower and cleanup harder.
A few warning signs tend to show up early:
- The model bill stays flat, but total operating cost keeps rising.
- Support and ops teams are "just checking" AI output more often.
- Storage usage grows every week, even when customer traffic stays steady.
- Managers spend more time reviewing exceptions than planned.
Small teams feel this fast. A founder may think AI saved one contractor fee, then lose the same amount through extra review time, larger storage bills, and manual cleanup. If you do not count those hours and systems, the savings on paper look better than the savings in real life.
A monthly checklist that actually helps
A monthly review works best when it stays boring and repeatable. Open the same report every month, compare it with the last one, and look for movement in the places where new spend usually hides.
Start with failed work. If retries went up, the bill may rise even when usage looks flat. A prompt change, a flaky integration, or a model timeout can turn one task into three paid runs.
Then look at people time. Reviewer hours should fall if the workflow is working well. If they stay flat or rise, the tool may be creating cleanup work instead of saving time. A team that spends 6 hours less writing but 8 hours more checking outputs did not cut cost. It moved cost.
Stored data deserves the same attention. AI workflows often keep prompts, outputs, logs, files, embeddings, and backups long after anyone needs them. If storage keeps growing, ask what still has a clear use and what should be deleted, compressed, or archived.
Use this short checklist each month:
- Compare retry counts with completed runs, not with total requests alone.
- Check whether reviewer and QA time fell, stayed flat, or climbed.
- Review stored files, logs, and vector data, then remove what no longer earns its keep.
- Test each workflow with a plain question: does it save more money than it costs?
- Flag any workflow that still looks confusing after two review cycles.
If the picture stays messy, an outside review can help. Someone who has spent years looking at software architecture, infrastructure, and AI operations can often spot where spending moved instead of dropped. Oleg Sotnikov at oleg.is does this kind of work with startups and small businesses, and a fresh look can uncover simple fixes that cut retries, storage growth, and reviewer hours at the same time.
Frequently Asked Questions
Why did payroll drop but our total AI cost stay flat?
Because AI often moves spend instead of removing it. You may save labor hours, then pay more for model calls, storage, monitoring, and review. Put all of those costs on one workflow line before you judge the savings.
What hidden costs do teams usually miss after adding AI?
Most teams miss retries, reviewer time, and stored data first. Those charges start small, then grow as more people use the workflow.
How should I track AI costs if several tools are involved?
Track costs by workflow, not by invoice. Put the trigger, every paid service, and every person who touches the output on one sheet. That gives you a cost per finished result instead of a pile of separate charges.
Should I count failed runs if the task eventually works?
Yes. A task that fails twice and succeeds on the third try costs three runs, not one. Log attempts, prompt size, and failure reason so you can see where the extra spend starts.
Why does storage grow so fast in AI workflows?
AI work creates more than final answers. Teams keep uploads, prompts, outputs, logs, embeddings, caches, and backups, and each copy adds to the bill. Set retention rules early so old debug data and failed runs do not pile up.
How do I measure reviewer and cleanup time?
Use a simple log with review minutes, rewrite minutes, and rejected outputs for each task type. Then compare that with the old manual time. If people spend almost as long fixing drafts as they once spent doing the work from scratch, the savings are thin.
How often should I review AI operating costs?
Check one workflow every month. Use the same categories each time: labor, model usage, storage, support issues, and the old manual cost. A small, repeatable review catches cost drift early.
What shows that an AI workflow is not paying off?
Watch for rising retries, flat reviewer hours, and storage that keeps climbing while output quality stays shaky. When a workflow needs constant cleanup, it saves less money than the first dashboard suggests.
Do I need special software to run a proper cost review?
No. A shared spreadsheet and basic usage logs are enough for most small teams. Start with one row per workflow and fill in real numbers from invoices, task logs, and staff time.
Can Oleg help review our AI costs?
Yes. Oleg Sotnikov works with startups and small businesses on AI operations, software architecture, and infrastructure. He can review where money moved, find waste in retries and storage, and suggest simpler workflows that cost less to run.


